






















![Existing Tools
Metrics Databases
● Ganglia [Berkley]
● Graphite [Orbitz]
● OpenTSDB [Stubleupon]
● KairosDB
● InfluxDB
● Prometheus [SoundCloud]
● Gnocchi [OpenStack]
● Atlas [Netflix]
● Heroic [Spotify]
● Hawkular [Redhat]
● MetricTank [Raintank]
● Riak TS [Basho]
● Blueflood [Rackspace]
● DalmatinerDB
● Druid
● BTrDB
● Warp 10
● Tgres](https://image.slidesharecdn.com/infrastructuremonitoringpostgresfinal-170209105511/85/Infrastructure-Monitoring-with-Postgres-24-320.jpg)

























![Postgres for Metrics
Combine Series
average over all
for {series=cpu}
[time range/interval]
Read Series
for each {type}
for {series=cpu}
[time range/interval]](https://image.slidesharecdn.com/infrastructuremonitoringpostgresfinal-170209105511/85/Infrastructure-Monitoring-with-Postgres-51-320.jpg)
![Postgres for Metrics
List
Dimension
Values
List
Dimension
Names
List
Metric
Names
"metrics": [
"cpu.percent",
"cpu.user_perc",
"net.out_bytes_sec",
"net.out_errors_sec",
"net.in_bytes_sec",
"net.in_errors_sec"
…
]
"dimensions": [
"device",
"hostname",
"instance",
"mount_point",
"process_name",
"process_user"
…
]
"hostname": [
"dev-01",
"dev-02",
"staging-01",
"staging-02",
"prod-01",
"prod-02"
…
]](https://image.slidesharecdn.com/infrastructuremonitoringpostgresfinal-170209105511/85/Infrastructure-Monitoring-with-Postgres-52-320.jpg)











































![Postgres for Log Parsing
"log": {
"timestamp": 1232141412,
"message":
"Connect from 172.16.8.1:52690 to 172.16.8.10:5000 (keystone/HTTP)",
"dimensions": {
"severity": 6,
"facility": 16,
"pid": "39762",
"program": "haproxy",
"hostname": "dev-controller-0",
"tags": [ "connect" ]
},
}](https://image.slidesharecdn.com/infrastructuremonitoringpostgresfinal-170209105511/85/Infrastructure-Monitoring-with-Postgres-98-320.jpg)
![Postgres for Log Parsing
"log": {
"timestamp": 1232141412,
"message":
"Connect from 172.16.8.1:52690 to 172.16.8.10:5000 (keystone/HTTP)",
"dimensions": {
"severity": 6,
"facility": 16,
"pid": "39762",
"program": "haproxy",
"hostname": "dev-controller-0",
"tags": [ "connect" ]
},
}](https://image.slidesharecdn.com/infrastructuremonitoringpostgresfinal-170209105511/85/Infrastructure-Monitoring-with-Postgres-99-320.jpg)
![Postgres for Log Parsing
"log": {
"timestamp": 1232141412,
"message":
"Connect from 172.16.8.1:52690 to 172.16.8.10:5000 (keystone/HTTP)",
"dimensions": {
"severity": 6,
"facility": 16,
"pid": "39762",
"program": "haproxy",
"hostname": "dev-controller-0",
"tags": [ "connect" ],
"src_ip": "172.16.8.1",
"src_port": "52690",
"dest_ip": "172.16.8.10",
"dest_port": "5000",
"service_name": "keystone",
"protocol": "HTTP"
},
}](https://image.slidesharecdn.com/infrastructuremonitoringpostgresfinal-170209105511/85/Infrastructure-Monitoring-with-Postgres-100-320.jpg)



![Postgres for Log Parsing
Patterns Table
Store pattern to match and field names
CREATE TABLE patterns (
regex VARCHAR,
field_names VARCHAR[]
);
INSERT INTO patterns (regex, fields_names) VALUES (
'Connect from '
|| '(d+.d+.d+.d+):(d+) to (d+.d+.d+.d+):(d+)'
|| ' ((w+)/(w+))',
'{src_ip,src_port,dest_ip,dest_port,service,protocol}'
);](https://image.slidesharecdn.com/infrastructuremonitoringpostgresfinal-170209105511/85/Infrastructure-Monitoring-with-Postgres-104-320.jpg)


![Postgres for Log Parsing
# INSERT INTO logs (timestamp, message, dimensions) VALUES (
'2017-01-03T06:29:09.043Z',
'Connect from 172.16.8.1:52690 to 172.16.8.10:5000 (keystone/HTTP)',
'{"hostname": "dev-controller-0", "program": "haproxy"}');
# SELECT timestamp, message, JSONB_PRETTY(dimensions) FROM logs;
-[ RECORD 1 ]+------------------------------------------------------------------
timestamp | 2017-01-03 06:29:09.043+00
message | Connect from 172.16.8.1:52690 to 172.16.8.10:5000 (keystone/HTTP)
jsonb_pretty | { +
| "src_ip": "172.16.8.1", +
| "dest_ip": "172.16.8.10", +
| "program": "haproxy", +
| "service": "keystone", +
| "hostname": "dev-controller-0", +
| "protocol": "HTTP", +
| "src_port": "52690", +
| "dest_port": "5000" +
| }](https://image.slidesharecdn.com/infrastructuremonitoringpostgresfinal-170209105511/85/Infrastructure-Monitoring-with-Postgres-107-320.jpg)








Infrastructure Monitoring with Postgres
- 1. Infrastructure Monitoring (with Postgres, obviously) Steve Simpson StackHPC [email protected] www.stackhpc.com
- 2. Overview 1) Background 2) Monitoring Postgres for Metrics 3) Requirements 4) Data & Queries 5) Optimisation Postgres for ... 6) Log Searching 7) Log Parsing 8) Queueing
- 3. Background
- 4. Background Systems Software Engineer C, C++, Python
- 5. Background Based in Bristol, UK Thriving Tech Industry
- 6. Background ● Gnodal ● 10GbE Ethernet ● ASIC Verification ● Embedded Firmware ● JustOne Database ● Agile “Big Data” RMDBS ● Based on PostgreSQL ● Storage Team Lead
- 7. Background Consultancy for HPC on OpenStack Multi-tenant massively parallel workloads Monitoring complex infrastructure Stack HPC
- 8. Background Cloud orchestration platform IaaS through API and dashboard Multi-tenancy throughout Network, Compute, Storage
- 9. Background Operational visibility is critical OpenStack is a complex, distributed application …to run your complex, distributed applications
- 10. Monitoring
- 11. Monitoring Requirements Gain visibility into the operation of the hardware and software e.g. web site, database, cluster, disk drive
- 12. Monitoring Requirements Fault finding and alerting Notify me when a server or service is unavailable, a disk needs replacing, ... Fault post-mortem, pre-emption Why did the outage occur and what can we do to prevent it next time
- 13. Monitoring Requirements Utilisation and efficiency analysis Is all the hardware we own being used? Is it being used efficiently? Performance monitoring and profiling How long are my web/database requests?
- 14. Monitoring Requirements Auditing (security, billing) Tracking users use of system Auditing access to systems or resources Decision making, future planning What is expected growth in data, or users? What of the current system is most used?
- 16. Existing Tools Checking and Alerting Agents check on machines or services Report centrally, notify users via dashboard Store history of events in database
- 17. Existing Tools Nagios / Icinga ping -c 1 $host || mail -s “Help!” $me
- 19. Existing Tools Metrics Periodically collect metrics, e.g. CPU% Store in central database for visualization Some systems allow checking on top
- 20. Existing Tools Ganglia Collector (gmond) + Aggregator (gmetad)
- 22. Existing Tools Grafana - visualization only
- 23. Existing Tools Metrics Databases ● Ganglia (RRDtool) ● Graphite (Whisper) ● OpenTSDB (HBase) ● KairosDB (Cassandra) ● InfluxDB ● Prometheus ● Gnocchi ● Atlas ● Heroic ● Hawkular (Cassandra) ● MetricTank (Cassandra) ● Riak TS (Riak) ● Blueflood (Cassandra) ● DalmatinerDB ● Druid ● BTrDB ● Warp 10 (Hbase) ● Tgres (PostgreSQL!)
- 24. Existing Tools Metrics Databases ● Ganglia [Berkley] ● Graphite [Orbitz] ● OpenTSDB [Stubleupon] ● KairosDB ● InfluxDB ● Prometheus [SoundCloud] ● Gnocchi [OpenStack] ● Atlas [Netflix] ● Heroic [Spotify] ● Hawkular [Redhat] ● MetricTank [Raintank] ● Riak TS [Basho] ● Blueflood [Rackspace] ● DalmatinerDB ● Druid ● BTrDB ● Warp 10 ● Tgres
- 25. Existing Tools
- 28. Existing Tools 2000 2010 2013 - 2015
- 31. Monasca Existing Tools Software Network Storage Log API Metric API Alerting Servers Metrics Logs
- 32. Monasca Existing Tools Software Network Storage Log API Metric API Alerting MySQL Servers Metrics Logs
- 33. Monasca Existing Tools Software Network Storage Log API InfluxDB Metric API Alerting MySQL Servers Metrics Logs
- 34. Monasca Existing Tools Software Network Storage Log API InfluxDB Metric API Alerting Grafana MySQL SQLite Servers Metrics Logs
- 35. Monasca Existing Tools Software Network Storage Log API Logstash Elastic InfluxDB Metric API Alerting Grafana MySQL SQLite Servers Metrics Logs
- 36. Monasca Existing Tools Software Network Storage Log API Logstash Elastic InfluxDB Metric API Alerting Grafana Kibana MySQL SQLite Servers Metrics Logs
- 37. Monasca Existing Tools Software Network Storage Log API Kafka Logstash Elastic InfluxDB Metric API Alerting Grafana Kibana MySQL SQLite Servers Metrics Logs
- 38. Monasca Existing Tools Software Network Storage Log API Kafka Logstash Elastic InfluxDB Metric API Alerting Grafana Kibana MySQL SQLite Servers Metrics Logs Zookeeper
- 39. Existing Tools Commendable “right tool for the job” attitude, but… How about Postgres? Fewer points of failure Fewer places to backup Fewer redundancy protocols One set of consistent data semantics Re-use existing operational knowledge
- 40. Monasca Existing Tools Software Network Storage Log API Kafka Logstash Elastic InfluxDB Metric API Alerting Grafana Kibana MySQL SQLite Servers Metrics Logs Zookeeper
- 41. Monasca Existing Tools Software Network Storage Log API Kafka Logstash Elastic InfluxDB Metric API Alerting Grafana Kibana SQLite Servers Metrics Logs Zookeeper
- 42. Monasca Existing Tools Software Network Storage Log API Kafka Logstash Elastic InfluxDB Metric API Alerting Grafana Kibana Servers Metrics Logs Zookeeper
- 43. Monasca Existing Tools Software Network Storage Log API Kafka Logstash Elastic Metric API Alerting Grafana Kibana Servers Metrics Logs Zookeeper
- 44. Monasca Existing Tools Software Network Storage Log API Kafka Logstash Metric API Alerting Grafana Grafana? Servers Metrics Logs Zookeeper
- 45. Monasca Existing Tools Software Network Storage Log API Logstash Metric API Alerting Grafana Grafana? Servers Metrics Logs Zookeeper
- 46. Monasca Existing Tools Software Network Storage Log API Logstash Metric API Alerting Grafana Grafana? Servers Metrics Logs
- 47. Monasca Existing Tools Software Network Storage Log API Metric API Alerting Grafana Grafana? Servers Metrics Logs
- 48. Monasca Existing Tools Software Network Storage Log API Metric API Alerting Grafana Servers Metrics Logs
- 50. Postgres for Metrics Requirements ● ~45M values/day (80x196 per 30s) ● 6 month history ● <1TB disk footprint ● <100ms queries
- 51. Postgres for Metrics Combine Series average over all for {series=cpu} [time range/interval] Read Series for each {type} for {series=cpu} [time range/interval]
- 52. Postgres for Metrics List Dimension Values List Dimension Names List Metric Names "metrics": [ "cpu.percent", "cpu.user_perc", "net.out_bytes_sec", "net.out_errors_sec", "net.in_bytes_sec", "net.in_errors_sec" … ] "dimensions": [ "device", "hostname", "instance", "mount_point", "process_name", "process_user" … ] "hostname": [ "dev-01", "dev-02", "staging-01", "staging-02", "prod-01", "prod-02" … ]
- 53. Postgres for Metrics Data & Queries
- 54. Postgres for Metrics "metric": { "timestamp": 1232141412, "name": "cpu.percent", "value": 42, "dimensions": { "hostname": "dev-01" }, "value_meta": { … } } JSON Ingest Format Known, well defined structure Varying set of dimensions key/values
- 55. Postgres for Metrics CREATE TABLE measurements ( timestamp TIMESTAMPTZ, name VARCHAR, value FLOAT8, dimensions JSONB, value_meta JSON ); Basic Denormalised Schema Straightforward mapping onto input data Data model for all schemas
- 56. Postgres for Metrics SELECT TIME_ROUND(timestamp, 60) AS timestamp, AVG(value) AS avg FROM measurements WHERE timestamp BETWEEN '2015-01-01Z00:00:00' AND '2015-01-01Z01:00:00' AND name = 'cpu.percent' AND dimensions @> '{"hostname": "dev-01"}'::JSONB GROUP BY timestamp Single Series Query One hour window | Single hostname Measurements every 60 second interval
- 57. Postgres for Metrics SELECT TIME_ROUND(timestamp, 60) AS timestamp, AVG(value) AS avg, dimensions ->> 'hostname' AS hostname FROM measurements WHERE timestamp BETWEEN '2015-01-01Z00:00:00' AND '2015-01-01Z01:00:00' AND name = 'cpu.percent' GROUP BY timestamp, hostname Group Multi-Series Query One hour window | Every hostname Measurements every 60 second interval
- 58. Postgres for Metrics SELECT TIME_ROUND(timestamp, 60) AS timestamp, AVG(value) AS avg FROM measurements WHERE timestamp BETWEEN '2015-01-01Z00:00:00' AND '2015-01-01Z01:00:00' AND name = 'cpu.percent' GROUP BY timestamp All Multi-Series Query One hour window | Every hostname Measurements every 60 second interval
- 59. Postgres for Metrics SELECT DISTINCT name FROM measurements Metric Name List Query :)
- 60. Postgres for Metrics SELECT DISTINCT JSONB_OBJECT_KEYS(dimensions) AS d_name WHERE name = 'cpu.percent' FROM measurements Dimension Name List Query (for specific metric)
- 61. Postgres for Metrics SELECT DISTINCT dimensions ->> 'hostname' AS d_value WHERE name = 'cpu.percent' AND dimensions ? 'hostname' FROM measurements Dimension Value List Query (for specific metric and dimension)
- 63. Postgres for Metrics CREATE TABLE measurements ( timestamp TIMESTAMPTZ, name VARCHAR, value FLOAT8, dimensions JSONB, value_meta JSON ); CREATE INDEX ON measurements (name, timestamp); CREATE INDEX ON measurements USING GIN (dimensions); Indexes Covers all necessary query terms Using single GIN saves space, but slower
- 64. Postgres for Metrics ● Series Queries ● All, Group, Specific ● Varying Time Window/Interval 5m|15s, 1h|15s, 1h|300s, 6h|300s, 24h|300s ● Listing Queries ● Metric Names, Dimension Names & Values ● All, Partial
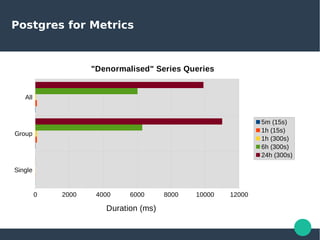
- 65. Postgres for Metrics Single Group All 0 2000 4000 6000 8000 10000 12000 "Denormalised" Series Queries 5m (15s) 1h (15s) 1h (300s) 6h (300s) 24h (300s) Duration (ms)
- 66. Postgres for Metrics Single Group All 0 500 1000 1500 2000 2500 "Denormalised" Series Queries 5m (15s) 1h (15s) 1h (300s) 6h (300s) 24h (300s) Duration (ms)
- 67. Postgres for Metrics Dimension Values Dimension Names Metric Names 0 10000 20000 30000 40000 50000 60000 "Denormalised" Listing Queries All Partial Duration (ms)
- 68. Postgres for Metrics Dimension Values Dimension Names Metric Names 0 1000 2000 3000 4000 5000 6000 7000 8000 "Denormalised" Listing Queries All Partial Duration (ms)
- 69. Postgres for Metrics CREATE TABLE measurement_values ( timestamp TIMESTAMPTZ, metric_id INT, value FLOAT8, value_meta JSON ); CREATE TABLE metrics ( id SERIAL, name VARCHAR, dimensions JSONB, ); Normalised Schema Reduces duplication of data Pre-built set of distinct metric definitions
- 70. Postgres for Metrics CREATE FUNCTION get_metric_id (in_name VARCHAR, in_dims JSONB) RETURNS INT LANGUAGE plpgsql AS $_$ DECLARE out_id INT; BEGIN SELECT id INTO out_id FROM metrics AS m WHERE m.name = in_name AND m.dimensions = in_dims; IF NOT FOUND THEN INSERT INTO metrics ("name", "dimensions") VALUES (in_name, in_dims) RETURNING id INTO out_id; END IF; RETURN out_id; END; $_$; Normalised Schema Function to use at insert time Finds existing metric_id or allocates new
- 71. Postgres for Metrics CREATE VIEW measurements AS SELECT * FROM measurement_values INNER JOIN metrics ON (metric_id = id); CREATE INDEX metrics_idx ON metrics (name, dimensions); CREATE INDEX measurements_idx ON measurement_values (metric_id, timestamp); Normalised Schema Same queries, use view to join Extra index to help normalisation step
- 72. Postgres for Metrics Single Group All 0 500 1000 1500 2000 2500 "Normalised" Series Queries 5m (15s) 1h (15s) 1h (300s) 6h (300s) 24h (300s) Duration (ms)
- 73. Postgres for Metrics Single Group All 0 200 400 600 800 1000 "Normalised" Series Queries 5m (15s) 1h (15s) 1h (300s) 6h (300s) 24h (300s) Duration (ms)
- 74. Postgres for Metrics Dimension Values Dimension Names Metric Names 0 200 400 600 800 1000 "Normalised" Listing Queries All Partial Duration (ms)
- 75. Postgres for Metrics ● As time window grows less detail is necessary, e.g. ● 30s interval at 1 hour ● 300s interval at 6 hour
- 76. Postgres for Metrics Timestamp Metric Value 10:00:00 1 10 10:00:00 2 2 10:00:30 1 10 10:00:30 2 4 10:01:30 1 20 10:01:30 2 4 10:02:00 1 15 10:02:00 2 2 10:02:30 1 5 10:02:30 2 2 10:03:00 1 10 10:03:00 2 6 Timestamp Metric Value 10:00:00 1 40 10:00:00 2 10 10:02:00 1 30 10:02:00 2 8
- 77. Postgres for Metrics CREATE TABLE summary_values_5m ( timestamp TIMESTAMPTZ, metric_id INT, value_sum FLOAT8, value_count FLOAT8, value_min FLOAT8, value_max FLOAT8, UNIQUE (metric_id, timestamp) ); Summarised Schema Pre-compute every 5m (300s) interval Functions to be applied must be known
- 78. Postgres for Metrics CREATE FUNCTION update_summarise () RETURNS TRIGGER LANGUAGE plpgsql AS $_$ BEGIN INSERT INTO summary_values_5m VALUES ( TIME_ROUND(NEW.timestamp, 300), NEW.metric_id, NEW.value, 1, NEW.value, NEW.value) ON CONFLICT (metric_id, timestamp) DO UPDATE SET value_sum = value_sum + EXCLUDED.value_sum, value_count = value_count + EXCLUDED.value_count, value_min = LEAST (value_min, EXCLUDED.value_min), value_max = GREATEST(value_max, EXCLUDED.value_max); RETURN NULL; END; $_$; Summarised Schema Entry for each metric/rounded time period Update existing entries by aggregating
- 79. Postgres for Metrics CREATE TRIGGER update_summarise_trigger AFTER INSERT ON measurement_values FOR EACH ROW EXECUTE PROCEDURE update_summarise (); CREATE VIEW summary_5m AS SELECT * FROM summary_values_5m INNER JOIN metrics ON (metric_id = id); Summarised Schema Trigger applies row to summary table View mainly for convenience when querying
- 80. Postgres for Metrics SELECT TIME_ROUND(timestamp, 300) AS timestamp, AVG(value) AS avg FROM measurements WHERE timestamp BETWEEN '2015-01-01Z00:00:00' AND '2015-01-01Z06:00:00' AND name = 'cpu.percent' GROUP BY timestamp Combined Series Query Six hour window | Every hostname Measurements every 300 second interval
- 81. Postgres for Metrics SELECT TIME_ROUND(timestamp, 300) AS timestamp, SUM(value_sum) / SUM(value_count) AS avg FROM summary_5m WHERE timestamp BETWEEN '2015-01-01Z00:00:00' AND '2015-01-01Z06:00:00' AND name = 'cpu.percent' GROUP BY timestamp Combined Series Query Use pre-aggregated summary table Mostly the same; extra fiddling for AVG
- 82. Postgres for Metrics Single Group All 0 200 400 600 800 1000 "Summarised" Series Queries 5m (15s) 1h (15s) 1h (300s) 6h (300s) 24h (300s) Duration (ms)
- 83. Postgres for Metrics Dimension Values Dimension Names Metric Names 0 200 400 600 800 1000 "Summarised" Listing Queries All Partial Duration (ms)
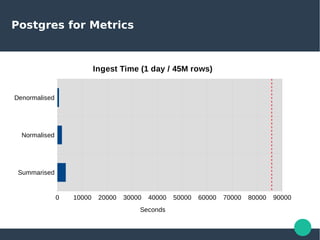
- 84. Postgres for Metrics Summarised Normalised Denormalised 0 10000 20000 30000 40000 50000 60000 70000 80000 90000 Ingest Time (1 day / 45M rows) Seconds
- 85. Postgres for Metrics Summarised Normalised Denormalised 0 500 1000 1500 2000 2500 3000 3500 4000 Ingest Time (1 day / 45M rows) Seconds
- 86. Postgres for Metrics Summarised Normalised Denormalised 0 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000 Disk Usage (1 day / 45M rows) MB
- 87. Postgres for Metrics ● Need coarser summaries for wider queries (e.g. 30m summaries) ● Need to partition data by day to: ● Retain ingest rate due to indexes ● Optimise dropping old data ● Much better ways to produce summaries to optimise ingest, specifically: ● Process rows in batches of interval size ● Process asynchronous to ingest transaction
- 88. Postgres for…
- 90. Postgres for Log Searching Requirements ● Central log storage ● Trivially searchable ● Time bounded ● Filter ‘dimensions’ ● Interactive query times (<100ms)
- 91. Postgres for Log Searching "log": { "timestamp": 1232141412, "message": "Connect from 172.16.8.1:52690 to 172.16.8.10:5000 (keystone/HTTP)", "dimensions": { "severity": 6, "facility": 16, "pid": "39762", "program": "haproxy" "hostname": "dev-controller-0" }, } Log Ingest Format Typically sourced from rsyslog Varying set of dimensions key/values
- 92. Postgres for Log Searching CREATE TABLE logs ( timestamp TIMESTAMPTZ, message VARCHAR, dimensions JSONB ); Basic Schema Straightforward mapping of source data Allow for maximum dimension flexibility
- 93. Postgres for Log Searching connection AND program:haproxy Query Example Kibana/Elastic style using PG-FTS SELECT * FROM logs WHERE TO_TSVECTOR('english', message) @@ TO_TSQUERY('connection') AND dimensions @> '{"program":"haproxy"}';
- 94. Postgres for Log Searching CREATE INDEX ON logs USING GIN (TO_TSVECTOR('english', message)); CREATE INDEX ON logs USING GIN (dimensions); Indexes Enables fast text search on ‘message’ & Fast filtering based on ‘dimensions’
- 95. Postgres for … Log Parsing
- 96. Postgres for Log Parsing "log": { "timestamp": 1232141412, "message": "Connect from 172.16.8.1:52690 to 172.16.8.10:5000 (keystone/HTTP)", "dimensions": { "severity": 6, "facility": 16, "pid": "39762", "program": "haproxy", "hostname": "dev-controller-0" }, }
- 97. Postgres for Log Parsing "log": { "timestamp": 1232141412, "message": "Connect from 172.16.8.1:52690 to 172.16.8.10:5000 (keystone/HTTP)", "dimensions": { "severity": 6, "facility": 16, "pid": "39762", "program": "haproxy", "hostname": "dev-controller-0" }, }
- 98. Postgres for Log Parsing "log": { "timestamp": 1232141412, "message": "Connect from 172.16.8.1:52690 to 172.16.8.10:5000 (keystone/HTTP)", "dimensions": { "severity": 6, "facility": 16, "pid": "39762", "program": "haproxy", "hostname": "dev-controller-0", "tags": [ "connect" ] }, }
- 99. Postgres for Log Parsing "log": { "timestamp": 1232141412, "message": "Connect from 172.16.8.1:52690 to 172.16.8.10:5000 (keystone/HTTP)", "dimensions": { "severity": 6, "facility": 16, "pid": "39762", "program": "haproxy", "hostname": "dev-controller-0", "tags": [ "connect" ] }, }
- 100. Postgres for Log Parsing "log": { "timestamp": 1232141412, "message": "Connect from 172.16.8.1:52690 to 172.16.8.10:5000 (keystone/HTTP)", "dimensions": { "severity": 6, "facility": 16, "pid": "39762", "program": "haproxy", "hostname": "dev-controller-0", "tags": [ "connect" ], "src_ip": "172.16.8.1", "src_port": "52690", "dest_ip": "172.16.8.10", "dest_port": "5000", "service_name": "keystone", "protocol": "HTTP" }, }
- 101. Postgres for Log Parsing ….regex! # SELECT REGEXP_MATCHES( 'Connect from 172.16.8.1:52690 to 172.16.8.10:5000 (keystone/HTTP)', 'Connect from ' || '(d+.d+.d+.d+):(d+) to (d+.d+.d+.d+):(d+)' || ' ((w+)/(w+))' ); regexp_matches --------------------------------------------------- {172.16.8.1,52690,172.16.8.10,5000,keystone,HTTP} (1 row)
- 102. Postgres for Log Parsing Garnish with JSONB # SELECT JSONB_PRETTY(JSONB_OBJECT( '{src_ip,src_port,dest_ip,dest_port,service, protocol}', '{172.16.8.1,52690,172.16.8.10,5000,keystone,HTTP}' )); jsonb_pretty ------------------------------- { + "src_ip": "172.16.8.1", + "dest_ip": "172.16.8.10",+ "service": "keystone", + "protocol": "HTTP", + "src_port": "52690", + "dest_port": "5000" + } (1 row)
- 103. Postgres for Log Parsing CREATE TABLE logs ( timestamp TIMESTAMPTZ, message VARCHAR, dimensions JSONB ); Log Schema – Goals: Parse message against set of patterns Add extracted information as dimensions
- 104. Postgres for Log Parsing Patterns Table Store pattern to match and field names CREATE TABLE patterns ( regex VARCHAR, field_names VARCHAR[] ); INSERT INTO patterns (regex, fields_names) VALUES ( 'Connect from ' || '(d+.d+.d+.d+):(d+) to (d+.d+.d+.d+):(d+)' || ' ((w+)/(w+))', '{src_ip,src_port,dest_ip,dest_port,service,protocol}' );
- 105. Postgres for Log Parsing Log Processing Apply all configured patterns to new rows CREATE FUNCTION process_log () RETURNS TRIGGER LANGUAGE PLPGSQL AS $_$ DECLARE m JSONB; p RECORD; BEGIN FOR p IN SELECT * FROM patterns LOOP m := JSONB_OBJECT(p.field_names, REGEXP_MATCHES(NEW.message, p.regex)); IF m IS NOT NULL THEN NEW.dimensions := NEW.dimensions || m END IF; END LOOP; RETURN NEW; END; $_$;
- 106. Postgres for Log Parsing CREATE TRIGGER process_log_trigger BEFORE INSERT ON logs FOR EACH ROW EXECUTE PROCEDURE process_log (); Log Processing Trigger Apply patterns as messages and extend dimensions, as inserted into logs table
- 107. Postgres for Log Parsing # INSERT INTO logs (timestamp, message, dimensions) VALUES ( '2017-01-03T06:29:09.043Z', 'Connect from 172.16.8.1:52690 to 172.16.8.10:5000 (keystone/HTTP)', '{"hostname": "dev-controller-0", "program": "haproxy"}'); # SELECT timestamp, message, JSONB_PRETTY(dimensions) FROM logs; -[ RECORD 1 ]+------------------------------------------------------------------ timestamp | 2017-01-03 06:29:09.043+00 message | Connect from 172.16.8.1:52690 to 172.16.8.10:5000 (keystone/HTTP) jsonb_pretty | { + | "src_ip": "172.16.8.1", + | "dest_ip": "172.16.8.10", + | "program": "haproxy", + | "service": "keystone", + | "hostname": "dev-controller-0", + | "protocol": "HTTP", + | "src_port": "52690", + | "dest_port": "5000" + | }
- 109. Requirements ● Offload data burden from producers ● Persist as soon as possible to avoid loss ● Handle high velocity burst loads ● Data does not need to be queryable Postgres for Queueing
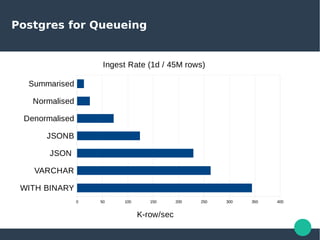
- 110. Postgres for Queueing WITH BINARY VARCHAR JSON JSONB Denormalised Normalised Summarised 0 50 100 150 200 250 300 350 400 Ingest Rate (1d / 45M rows) K-row/sec
- 111. Postgres for Queueing WITH BINARY VARCHAR JSON JSONB Denormalised Normalised Summarised 0 50 100 150 200 250 300 350 400 Ingest Rate (1d / 45M rows) K-row/sec
- 112. Postgres for Queueing WITH BINARY VARCHAR JSON JSONB Denormalised Normalised Summarised 0 50 100 150 200 250 300 350 400 Ingest Rate (1d / 45M rows) K-row/sec
- 113. Postgres for Queueing WITH BINARY VARCHAR JSON JSONB Denormalised Normalised Summarised 0 50 100 150 200 250 300 350 400 Ingest Rate (1d / 45M rows) K-row/sec
- 114. Postgres for Queueing WITH BINARY VARCHAR JSON JSONB Denormalised Normalised Summarised 0 50 100 150 200 250 300 350 400 Ingest Rate (1d / 45M rows) K-row/sec
- 115. Conclusion.. ?
- 116. Conclusion… ? ● I view Postgres as a very flexible “data persistence toolbox” ● ...which happens to use SQL ● Batteries not always included ● That doesn’t mean it’s hard ● Operational advantages of using general purpose tools can be huge ● Use & deploy what you know & trust