Ingesting Over Four Million Rows Per Second With QuestDB Timeseries Database - Berlin Buzzwords
0 likes99 views

Javier Ramirez discusses the evolution and performance of various database systems, emphasizing the strengths and specialized use cases of QuestDB, particularly for time-series data. He outlines key assumptions for data ingestion and querying, highlighting the need for efficient storage and querying strategies tailored to time-series patterns. The document also covers technical considerations, trade-offs, and future enhancements aimed at improving performance and compatibility.






































Ingesting Over Four Million Rows Per Second With QuestDB Timeseries Database - Berlin Buzzwords
- 1. Ingesting over four million rows per second on a single database instance Javier Ramirez @supercoco9
- 2. About me: I like databases & open source 2022- today. Developer relations at an open source database vendor ● QuestDB, PostgreSQL, MongoDB, Timescale, InfluxDB, Apache Flink 2019-2022. Data & Analytics specialist at a cloud provider ● Amazon Aurora, Neptune, Athena, Timestream, DynamoDB, DocumentDB, Kinesis Data Streams, Kinesis Data Analytics, Redshift, ElastiCache for Redis, QLDB, ElasticSearch, OpenSearch, Cassandra, Spark… 2013-2018. Data Engineer/Big Data & Analytics consultant ● PostgreSQL, Redis, Neo4j, Google BigQuery, BigTable, Google Cloud Spanner, Apache Spark, Apache BEAM, Apache Flink, HBase, MongoDB, Presto 2006-2012 - Web developer ● MySQL, Redis, PostgreSQL, Sqlite, ElasticSearch late nineties to 2005. Desktop/CGI/Servlets/ EJBs/CORBA ● MS Access, MySQL, Oracle, Sybase, Informix As a student/hobbyist (late eighties - early nineties) ● Amsbase, DBase III, DBase IV, Foxpro, Microsoft Works, Informix The pre-SQL years The licensed SQL period The libre and open SQL revolution / The NoSQL rise The hadoop dark ages / The python hegemony/ The cloud database big migrations The streaming era/ The database as a service singularity The SQL revenge/ the realtime database/the embedded database
- 3. Some things I will talk about ● Accept you are not PostgreSQL. You are not for everyone and cannot do everything ● Make the right assumptions ● Take advantage of modern hardware and operating systems ● Obsess about storage ● Reduce/control your dependencies ● Measure-implement-repeat continuously to improve performance
- 5. We would like to be known for: ● Performance ○ Better performance with smaller machines ● Developer Experience ● Proudly Open Source (Apache 2.0)
- 6. But I don’t need 4 million rows per second
- 7. Good, because you probably aren’t getting them.
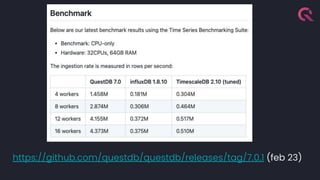
- 8. 8
- 10. Try out query performance on open datasets https://demo.questdb.io/
- 11. All benchmarks are lies (but they give us a ballpark) Ingesting over 1.4 million rows per second (using 5 CPU threads) https://questdb.io/blog/2021/05/10/questdb-release-6-0-tsbs-benchmark/ While running queries scanning over 4 billion rows per second (16 CPU threads) https://questdb.io/blog/2022/05/26/query-benchmark-questdb-versus-clickhouse-timescale/ Time-series specialised benchmark https://github.com/questdb/tsbs
- 15. If you can use only one database for everything, go with PostgreSQL
- 18. Not all (big) (or fast) data problems are the same
- 19. Do you have a time-series problem? Write patterns ● You mostly insert data. You rarely update or delete individual rows ● It is likely you write data more frequently than you read data ● Since data keeps growing, you will very likely end up with much bigger data than your typical operational database would be happy with ● Your data origin might experience bursts or lag, but keeping the correct order of events is important to you ● Both ingestion and querying speed are critical for your business
- 20. Do you have a time-series problem? Read patterns ● Most of your queries are scoped to a time range ● You typically access recent/fresh data rather than older data ● But still want to keep older data around for occasional analytics ● You often need to resample your data for aggregations/analytics ● You often need to align timestamps from multiple data series
- 21. We can make many assumptions about the shape of the data and usage patterns
- 22. Data will most often be queried in a continuous range, and recent data will be preferred => Store data physically sorted by “designated timestamp” on disk (deal with out of order data) Store data in partitions, so we can skip a lot of data quickly Aggressive use of prefetching by the file system Most queries are not a select *, but aggregations on timestamp + a few columns => Columnar storage model. Open only the files for the column the query needs Most rows will have some sort of non-unique ID (string or numeric) to scope on => Special Symbol type, looks like a String, behaves like a Number. Faster and smaller Some assumptions when reading data
- 23. Data will be fast and continuous => Keep (dynamic and configurable) buffers to reduce write operations Slower reads should not slow down writes => Shared CPU/threads pool model, with default separate thread for ingestion and possibility to dedicate threads for parsing or other tasks Stale data is useful, but longer latencies are fine => Allow mounting old partitions on slower/cheaper drives Old data needs to be removed eventually => Allow unmounting/deleting partitions (archiving into object storage in the roadmap) Some assumptions when writing data
- 24. Queries should allow for reasonably complex filters and aggregations => Implement SQL, with pg-wire compatibility for compatibility Writes should be fast. Also, some users might be already using other TSDB => Implement the Influx Line Protocol (ILP) for speed and compatibility. Provide client libraries, as ILP is not as popular Many integrations might be from IoT or simple devices with bash scripting => Implement HTTP endpoint for querying, importing, and exporting data Operations teams will want to read QuestDB metrics, not stored data Implement health and metrics endpoint, with Prometheus compatibility Some assumptions when connecting
- 25. Say no to nice-to-have features that would degrade performance
- 26. But also say yes When it makes sense
- 27. Technical decisions and trade offs
- 29. Native unsafe memory. Shared across languages and OS Java C/C++ Rust * Mmap https://db.cs.cmu.edu/mmap-cidr2022/ * https://github.com/questdb/rust-maven-plugin
- 30. SIMD vectorization and own JIT compiler Single Instruction, multiple Data (SIMD): parallelizes/vectorizes operations in multiple registers. QuestDB only supports it on Intel and AMD processors. JIT compiler: compiles SQL statements EXPLAIN: helps understand execution plans and vectorization
- 31. 31
- 32. SELECT count(), max(total_amount), avg(total_amount) FROM trips WHERE total_amount > 150 AND passenger_count = 1; (Trips table has 1.6 billion rows and 24 columns, but we only access 2 of them) You can try it live at https://demo.questdb.io
- 33. Re-implement the JAVA std library ● Java Classes work with heap memory. We need off-heap ● JAVA classes tend to do too many things (they are generic) and a lot of type conversions ● This includes IO, logging, atomics, collections… using zero GC and native memory ● Zero Dependencies (except for testing) on our pom.xml
- 35. How would *YOU* efficiently sort a multi GB unordered CSV file?
- 37. Some things we are trying out next for performance ● Compression, and exploring data formats like arrow/ parquet ● Own ingestion protocol ● Embedding Julia in the database for custom code/UDFs ● Moving some parts to Rust ● Second level partitioning ● Improved vectorization of some operations (group by multiple columns or by expressions ● Add specific joins optimizations (index nested loop joins, for example)
- 39. More info https://questdb.io https://demo.questdb.io https://github.com/javier/questdb-quickstart We 💕 contributions and ⭐ stars github.com/questdb/questdb THANKS! Javier Ramirez, Head of Developer Relations at QuestDB, @supercoco9