Inside the Volta GPU Architecture and CUDA 9
2 likes3,173 views

The document details the Volta GPU architecture and the advancements introduced with CUDA 9, highlighting the Tesla V100 as a powerful tool for deep learning and high-performance computing. It covers innovations such as tensor cores, independent thread scheduling, and improved memory architectures aimed at enhancing computational efficiency. Additionally, performance comparisons demonstrate significant speedups in various deep learning tasks and efficient inference deployment capabilities.















![16
TENSOR CORE
Mixed Precision Matrix Math - 4x4 matrices
New CUDA TensorOp instructions
& data formats
4x4x4 matrix processing array
D[FP32] = A[FP16] * B[FP16] + C[FP32]](https://image.slidesharecdn.com/inside-the-volta-gpu-architecture-and-cuda-9-180603160742/85/Inside-the-Volta-GPU-Architecture-and-CUDA-9-16-320.jpg)























Inside the Volta GPU Architecture and CUDA 9
- 1. INSIDE THE VOLTA GPU ARCHITECTURE AND CUDA 9 Axel Koehler, Principal Solution Architect GPU$Technology$Conference$$Europe,$October$2017
- 2. 2 CONTINUED DEMAND FOR COMPUTE POWER Comprehensive$ Earth$System$ Model Coupled$simulation$ of$entire$cells Simulation$of$ combustion$for$new$ highEefficiency,$lowE emision engines. Predictive$ calculations$for$ supernovae 2016 Baidu Deep$Speech$2 Superhuman$Voice$ Recognition 2015 Microsoft$ResNet Superhuman$Image$ Recognition 2017 Google$Neural$ Machine$Translation Near$Human$ Language$Translation 100 ExaFLOPS 8700 Million Parameters 20 ExaFLOPS 300 Million Parameters 7 ExaFLOPS 60 Million Parameters Neural$Network$complexity$is$ExplodingEverEincreasing$compute$power$ Demand$ in$HPC
- 3. 3 INTRODUCING TESLA V100 The Fastest and Most Productive GPU for Deep Learning and HPC Volta Architecture Most Productive GPU Tensor Core 120 Programmable TFLOPS Deep Learning Improved SIMT Model New Algorithms Volta MPS Inference Utilization Improved NVLink & HBM2 Efficient Bandwidth
- 4. 4 NVIDIA Tesla V100 SXM2 Module with Volta GV100 GPU
- 5. 5 21B transistors 815 mm2 80 SM 5120 CUDA Cores 640 Tensor Cores 16 GB HBM2 900 GB/s HBM2 300 GB/s NVLink TESLA V100 *full GV100 chip contains 84 SMs
- 7. 7 VOLTA GV100 SM GP100 GV100 FP32 units 64 64 FP64 units 32 32 INT32 units NA 64 Tensor Cores NA 8 Register File 256 KB 256 KB Unified L1/Shared memory L1: 24KB Shared: 64KB 128 KB Active Threads 2048 2048 Redesigned for Productivity Completely$new$ISA Twice$the$schedulers Simplified$Issue$Logic Large,$fast$L1$cache Improved$SIMT$model Tensor$acceleration
- 8. 8 Shared Memory 64 KB L1$ 24 KB L2$ 4 MB Load/Store Units Pascal SM L2$ 6 MB Load/Store Units Volta SM L1$ and Shared Memory 128 KBLow Latency Streaming UNIFYING KEY TECHNOLOGIES
- 9. 9 L2$ 6 MB Load/Store Units SM L1$ and Shared Memory 128 KB VOLTA L1 AND SHARED MEMORY Volta Streaming L1$ : Unlimited cache misses in flight Low cache hit latency 4x more bandwidth 5x more capacity Volta Shared Memory : Unified storage with L1 Configurable up to 96KB
- 10. 10 NARROWING THE SHARED MEMORY GAP with the GV100 L1 cache Pascal Volta Cache: vs shared • Easier to use • 90%+ as good Shared: vs cache • Faster atomics • More banks • More predictable Average Shared Memory Benefit 70% 93% Directed testing: shared in global
- 12. 12 PRE-VOLTA WARP EXECUTION MODEL 32 thread warp Program Counter (PC) and Stack (S) Pre-Volta Time X;#Y; diverge reconverge A;#B; if (threadIdx.x < 4) { A; B; } else { X; Y; } No Synchronization Permitted
- 13. 13 VOLTA WARP EXECUTION MODEL 32 thread warp with independent schedulingPC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S PC,S Convergence Optimizer Volta diverge A; B; X; Y; Synchronization may lead to interleaved scheduling! Time synchronize if (threadIdx.x < 4) { A; __syncwarp(); B; } else { X; __syncwarp(); Y; } __syncwarp();
- 14. 14 Volta Independent Thread Scheduling: • Enables interleaved execution of statements from divergent branches • Enables execution of fine-grain parallel algorithms where threads within a warp may synchronize and communicate • At any given clock cycle, CUDA cores execute the same instruction for all active threads in a warp just as before • Execution is still SIMT which retains the high throughput • Use explicit synchronization, don’t rely on implicit convergence • CUDA 9 provides a fully explicit synchronization model VOLTA: INDEPENDENT THREAD SCHEDULING Extended'SIMT'model'enables'thread4parallel'programs'to'execute'with'vector'efficiency Volta: Threads may wait for messages
- 16. 16 TENSOR CORE Mixed Precision Matrix Math - 4x4 matrices New CUDA TensorOp instructions & data formats 4x4x4 matrix processing array D[FP32] = A[FP16] * B[FP16] + C[FP32]
- 17. 18 USING TENSOR CORES Volta Optimized Frameworks and Libraries __device__ void tensor_op_16_16_16( float *d, half *a, half *b, float *c) { wmma::fragment<matrix_a, …> Amat; wmma::fragment<matrix_b, …> Bmat; wmma::fragment<matrix_c, …> Cmat; wmma::load_matrix_sync(Amat, a, 16); wmma::load_matrix_sync(Bmat, b, 16); wmma::fill_fragment(Cmat, 0.0f); wmma::mma_sync(Cmat, Amat, Bmat, Cmat); wmma::store_matrix_sync(d, Cmat, 16, wmma::row_major); } CUDA C++ Warp-Level Matrix Operations NVIDIA cuDNN, cuBLAS, TensorRT
- 18. 19 0 1 2 3 4 5 6 7 8 9 10 512 1024 2048 4096 Relative2Performance Matrix2Size2(M=N=K) cuBLAS Mixed2Precision2(FP162Input,2FP322compute) P1002(CUDA28) V1002Tensor2Cores22(CUDA29) 0 0,2 0,4 0,6 0,8 1 1,2 1,4 1,6 1,8 2 512 1024 2048 4096 Relative2Performance Matrix2Size2(M=N=K) cuBLAS Single2Precision2(FP32) P1002(CUDA28) V1002(CUDA29) cuBLAS GEMMS FOR DEEP LEARNING V100 Tensor Cores + CUDA 9: over 9x Faster Matrix-Matrix Multiply 9.3x1.8x Note: pre-production Tesla V100 and pre-release CUDA 9. CUDA 8 GA release.
- 19. 20 NEW HBM2 MEMORY ARCHITECTURE STREAM:Triad-DeliveredGB/s P100 V100 76% DRAM Utilization 95% DRAM Utilization 1.5x Delivered Bandwidth • Unifying$Compute$&$Memory$in$Single$Package • More$bandwidth$and$more$energy$$efficient • ECC$can$be$active$without$a$bandwidth$or$ capacity$penalty
- 20. 21 VOLTA NVLINK • 6 NVLINKS @ 50 GB/s bidirectional • Reduce number of lanes for lightly loaded link (Power savings) • Coherence features for NVLINK enabled CPUs POWER9 based node Hybrid cube mesh (eg. DGX1V)
- 21. 22 STATE OF UNIFIED MEMORY High performance, low effort Allocate Beyond GPU Memory Size Unified Memory GPU CPU PGI OpenACC on Pascal P100 Geometric mean across all 15 SPEC ACCEL™ benchmarks 86% PCI-E, 91% NVLink Unified Memory Explicit data movement Automatic data movement for allocatables 86% Performance vs no Unified Memory PGI 17.1 Compilers OpenACC SPEC ACCEL™ 1.1 performance measured March, 2017. SPEC® and the benchmark name SPEC ACCEL™ are registered trademarks of the Standard Performance Evaluation Corporation.
- 22. 23 VOLTA + UNIFIED MEMORY VOLTA + NVLINK CPU VOLTA + PCIE CPU
- 23. 24 VOLTA MULTI-PROCESS SERVICE Hardware Accelerated Work Submission Hardware Isolation VOLTA MULTI-PROCESS SERVICE Volta GV100 A B C CUDA MULTI-PROCESS SERVICE CONTROL CPU Processes GPU Execution Volta MPS Enhancements: • MPS clients submit work directly to the work queues within the GPU • Reduced launch latency • Improved launch throughput • Improved isolation amongst MPS clients • Address isolation with independent address spaces • Improved quality of service (QoS) • 3x more clients than Pascal A B C
- 24. 25 Efficient inference deployment without batching system Single Volta Client, No Batching, No MPS VOLTA MPS FOR INFERENCEResnet50Images/sec,7mslatency Multiple Volta Clients, No Batching, Using MPS Volta with Batching System 7x faster 60% of perf with batching V100 measured on pre-production hardware.
- 25. 26 P100 V100 Ratio Training acceleration 10 TOPS 125 TOPS 12.5x Inference acceleration 21 TFLOPS 125 TOPS 6x FP64/FP32 5/10 TFLOPS 7.8/15.7 TFLOPS 1.5x HBM2 Bandwidth 720 GB/s 900 GB/s 1.2x NVLink Bandwidth 160 GB/s 300 GB/s 1.9x L2 Cache 4 MB 6 MB 1.5x L1 Caches 1.3 MB 10 MB 7.7x GPU PERFORMANCE COMPARISON
- 26. 27 REVOLUTIONARY AI PERFORMANCE 3X Faster DL Training Performance Over 80x DL Training Performance in 3 Years 1x K80 cuDNN2 4x M40 cuDNN3 8x P100 cuDNN6 8x V100 cuDNN7 0x 20x 40x 60x 80x 100x Q1 15 Q3 15 Q2 17 Q2 16 Googlenet Training Performance (Speedup Vs K80) SpeedupvsK80 85% Scale-Out Efficiency Scales to 64 GPUs with Microsoft Cognitive Toolkit 0 5 10 15 64X V100 8X V100 8X P100 Multi-Node Training with NCCL2.0 (ResNet-50) ResNet50 Training for 90 Epochs with 1.28M images dataset | Cognitive Toolkit with NCCL 2.0 | V100 performance measured on pre-production hardware. 1 Hour 7.4 Hours 18 Hours 3X Reduction in Time to Train Over P100 0 10 20 1X V100 1X P100 2X CPU LSTM Training (Neural Machine Translation) Neural Machine Translation Training for 13 Epochs |German ->English, WMT15 subset | CPU = 2x Xeon E5 2699 V4 | V100 performance measured on pre-production hardware. 15 Days 18 Hours 6 Hours
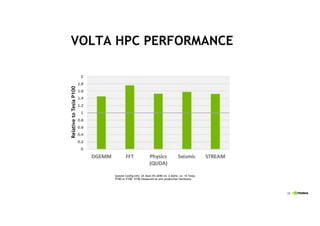
- 27. 28 VOLTA HPC PERFORMANCE RelativetoTeslaP100 System Config Info: 2X Xeon E5-2690 v4, 2.6GHz, w/ 1X Tesla P100 or V100. V100 measured on pre-production hardware.
- 28. 29 INTRODUCING CUDA 9 Tesla V100 New GPU Architecture Tensor Cores NVLink Independent Thread Scheduling BUILT FOR VOLTA COOPERATIVE THREAD GROUPS Flexible Thread Groups Efficient Parallel Algorithms Synchronize Across Thread Blocks in a Single GPU or Multi-GPUs cuBLAS for Deep Learning NPP for Image Processing cuFFT for Signal Processing FASTER LIBRARIES DEVELOPER TOOLS & PLATFORM UPDATES Faster Compile Times Unified Memory Profiling NVLink Visualization New OS and Compiler Support partition sync sync
- 29. 30 CUDA 9: WHAT’S NEW IN LIBRARIES VOLTA PLATFORM SUPPORT PERFORMANCE IMPROVED USER EXPERIENCENEW ALGORITHMS Utilize Volta Tensor Cores Volta optimized GEMMs (cuBLAS) Out-of-box performance on Volta (all libraries) GEMM optimizations for RNNs (cuBLAS) Faster image processing (NPP) FFT optimizations across various sizes (cuFFT) Multi-GPU dense & sparse solvers, dense eigenvalue & SVD (cuSOLVER) Breadth first search, clustering, triangle counting, extraction & contraction (nvGRAPH) New install package for CUDA Libraries (library-only meta package) Modular NPP with small footprint, support for image batching DEEP LEARNING Scientific Computing
- 30. 31 CUDA 9: UP TO 5X FASTER LIBRARIES 2x faster library speeds up image, video and signal processing operations cuBLAS cuFFT NPP 5x – 9x faster GEMM operations speed up deep learning and HPC apps Up to 100x faster than IPP for image processing and computer vision operations 0X 1X 1X 2X 2X 3X 1 64 16384 4194304 SpeedupVs.CUDA8* Data Size 1D 2D 3D 0x 50x 100x Color Proc. Filters Geometry Transforms JPEG Morphological Ops. Speedup Vs. IPP** * V100 and CUDA 9 (r384); Intel Xeon Broadwell, dual socket, E5-2698 v4@ 2.6GHz, 3.5GHz Turbo with Ubuntu 14.04.5 x86_64 with 128GB System Memory * P100 and CUDA 8 (r361); For cublas CUDA$8$(r361): Intel Xeon Haswell, single-socket, 16-core E5-2698 v3@ 2.3GHz, 3.6GHz Turbo with CentOS 7.2 x86-64 with 128GB System Memory ** CPU system running IPP: Intel Xeon Haswell single-socket 16-core E5-2698 v3@ 2.3GHz, 3.6GHz Turbo Ubuntu 14.04.5 x86_64 with 128GB System Memory 0x 2x 4x 6x 8x 10x 512 1024 2048 2816 SpeedupVs.CUDA8* Matrix Size FP32 FP16 I/O, FP32 Compute
- 32. 33 COOPERATIVE GROUPS A flexible model for synchronisation and communication within groups of threads Levels$of$cooperation: TODAY Levels$of$cooperation: CUDA$9
- 33. 34 COOPERATIVE GROUPS BASICS Flexible, Explicit Synchronization Thread groups are explicit objects in your program You can synchronize threads in a group Create new groups by partitioning existing groups Partitioned groups can also synchronize thread_group block =1this_thread_block(); block.sync(); thread_group tile321=1tiled_partition(block,132); thread_group tile41=1tiled_partition(tile32,14); tile4.sync(); Note: calls in green are part of the cooperative_groups:: namespace Thread Block Group Partitioned Thread Groups
- 34. 35 COOPERATIVE GROUPS Flexible and Scalable Thread Synchronization and Communication Define, synchronize, and partition groups of cooperating threads Flexible: High-performance API for clean and robust management of thread groups Scalable: Create and manage groups within warps, across thread blocks, and even across GPUs Deploy Everywhere (*): Kepler and Newer GPUs Supported by CUDA developer tools * Note: Multi-Block and Multi-Device Cooperative Groups are only supported on Pascal and above GPUs Thread Block Group Partitioned Thread Groups
- 36. 37 UNIFIED MEMORY PROFILING Correlate CPU Page Faults with Source Page Fault Correlation
- 37. 38 NEW UNIFIED MEMORY EVENTS Page ThrottlingMemory Thrashing Remote Map Visualize Virtual Memory Activity
- 38. 39 FUTURE: UNIFIED SYSTEM ALLOCATOR Allocate unified memory using standard malloc Removes CUDA-specific allocator restrictions Data movement is transparently handled Requires operating system support: HMM Linux Kernel Module void1sortfile(FILE1*fp,1int N)1{ char1*data; //1Allocate1memory1using1any1standard1allocator data1=1(char1*)1malloc(N1*1sizeof(char)); fread(data,11,1N,1fp); sort<<<...>>>(data,N,1,compare); use_data(data); //1Free1the1allocated1memory free(data); } CUDA 8 Code with System Allocator
- 39. 40 ADDITIONAL RESOURCES • Volta • Whitepaper http://www.nvidia.com/object/volta-architecture-whitepaper.html • Blog https://devblogs.nvidia.com/parallelforall/inside-volta • CUDA 9 • Blog https://devblogs.nvidia.com/parallelforall/cuda-9-features-revealed • Download https://developer.nvidia.com/cuda-downloads
- 40. Axel Koehler, Principal Solution Architect [email protected]