Introduction to Apache Kafka- Part 1
Download as ODP, PDF11 likes4,082 views

This document introduces Apache Kafka, a fast, scalable, and fault-tolerant publish-subscribe messaging system used for building data pipelines. It covers key topics such as Kafka's high-level overview, use cases, partition distribution, and the replication protocol, along with basic operational commands. The document also references various resources for further exploration of Kafka's functionalities.
































































![Question & Option[Answer]](https://image.slidesharecdn.com/kafka-01-160606104622/85/Introduction-to-Apache-Kafka-Part-1-70-320.jpg)

Introduction to Apache Kafka- Part 1
- 1. Himani Arora Software Consultant Knoldus Software LLP Satendra Kumar Sr. Software Consultant Knoldus Software LLP Introduction to Apache Kafka-01
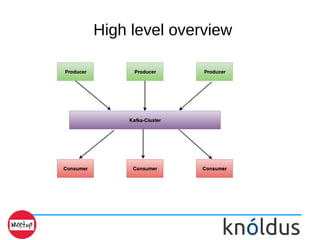
- 2. Topics Covered ➢ What is Kafka ➢ Why Kafka ➢ High level overview ➢ Use cases ➢ Key terminology ➢ Partitions distribution over brokers ➢ Replication protocol ➢ Demo
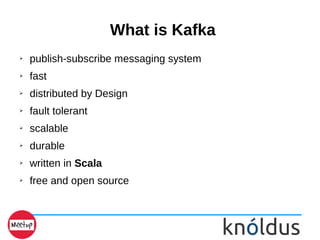
- 3. What is Kafka ➢ publish-subscribe messaging system ➢ fast ➢ distributed by Design ➢ fault tolerant ➢ scalable ➢ durable ➢ written in Scala ➢ free and open source
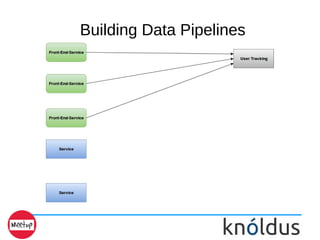
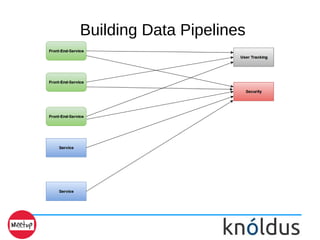
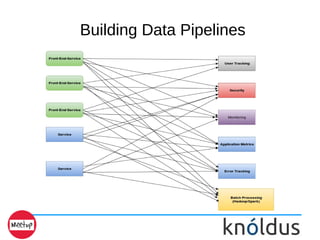
- 9. Building Data Pipelines This is Bad data pipelining
- 10. Building Data Pipelines Kafka decouples Data Pipelines
- 13. Use cases ➢ Messaging ➢ Website Activity Tracking ➢ Metrics ➢ Log Aggregation ➢ Real-Time Stream Processing ➢ Event Sourcing ➢ Commit Log ➢ Internet Of Things (IoT)
- 14. Key Terminology
- 26. Anatomy of a Topic For each topic, the Kafka cluster maintains a partitioned log that looks like this: http://kafka.apache.org/images/log_anatomy.png Number of partition for a Topic is configurable. In this example number of partition are three.
- 27. Reading & Writing From Topic https://content.linkedin.com/content/dam/engineering/en-us/blog/migrated/partitioned_log_0.png Topic with two partition:
- 35. Partitions Distribution Who is responsible for these tasks ?
- 39. Responsibility Of Controller ● managing the states of partitions and replicas ● performing administrative tasks like reassigning partitions
- 40. Roles For Partition ➢ Each partition has one server which acts as the "leader" and zero or more servers which act as "followers". ➢ The leader handles all read and write requests for the partition while the followers passively replicate the leader. ➢ If the leader fails, one of the followers will automatically become the new leader. ➢ Each server acts as a leader for some of its partitions and a follower for others so load is well balanced within the cluster.
- 65. Demo
- 66. Basic Operations ● List all topics created: bin/kafka-topics.sh --list --zookeeper localhost:2181 ● Describe a topic: – bin/kafka-topics.sh --zookeeper localhost:2181 --topic topic-name –describe
- 67. Basic Operations Adding a topic: $ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic topic_name Modifying a topic $ bin/kafka-topics.sh --zookeeper zk_host:localhost:2181 --alter --topic my_topic_name --partitions 4 Deleting a topic bin/kafka-topics.sh --zookeeper zk_host:localhost:2181 --delete --topic my_topic_name
- 68. Basic Operations Balancing Leadership: $ bin/kafka-preferred-replica-election.sh --zookeeper zk_host:localhost:2181 – Or Also configure Kafka to do this automatically by setting the following configuration : auto.leader.rebalance.enable = true
- 69. References ● http://kafka.apache.org/documentation.html ● https://engineering.linkedin.com/kafka/benchmarking-apache-k ● http://www.confluent.io/blog/tutorial-getting-started-with-the-new ● http://kafka-summit.org ● http://www.confluent.io/blog/hands-free-kafka-replication-a-less
Editor's Notes
- #10: 1) spend 10 to 20 % time for data integration 2) It is not scalable 3) push based system does not work.
- #18: Topics are high level abstraction that kafka provides. A topic is a category or feed name to which messages are published.
- #19: The topics are further divided into partitions.
- #20: Each partition is an ordered, immutable sequence of messages that is continually appended to—a commit log. The messages in the partitions are each assigned a sequential id number called the offset that uniquely identifies each message within the partition.
- #22: Producers publish data to the topics of their choice. The producer is responsible for choosing which message to assign to which partition within the topic. This can be done in a round-robin fashion simply to balance load or it can be done according to some semantic partition function (say based on some key in the message). More on the use of partitioning in a second.
- #24: 1) The key abstraction in Kafka is the topic. 2) Producers publish their records to a topic, and consumers subscribe to one or more topics. 3) A Kafka topic is just a sharded write-ahead log. 4) Producers append records to these logs and consumers subscribe to changes. 5) Each record is a key/value pair. The key is used for assigning the record to a log partition (unless the publisher specifies the partition directly).
- #26: Each node in the cluster is called a Kafka broker.
- #27: Each partition is an ordered, immutable sequence of messages that is continually appended to—a commit log. The messages in the partitions are each assigned a sequential id number called the offset that uniquely identifies each message within the partition.