















![1. void main_loop() {
2. while (true) {
3. for (x=0; x<ROW; x++) {
4. for(y=0;y<COL;y++){
5. switch (cell_to_char(PLANET[x][y])) {
6. case 'S':
7. if(UPDATE[x][y]==0 && shark_rule2(pw, x, y, k, l)==ALIVE) {
8. shark_rule1 (pw ,x , y, k, l);
9. }
10. break;
11. case 'F':
12. if(UPDATE[x][y]==0){
13. fish_rule4(pw, x, y, k, l);
14. fish_rule3(pw, x, y, k, l);
15. }
16. break;
17. }
18. }
19. }
20. }
21.}
17
https://github.com/DiamonDinoia/wator/
Simulator example](https://image.slidesharecdn.com/slides-210928163640/85/Introduction-to-FPGA-acceleration-17-320.jpg)
![1. int shark_rule2 (wator_t* pw, int x, int y, int *k, int* l){
2. int i=0;
3. long rand=random();
4. motion move[4];
5. if (DEATH[x][y]==pw->sd) {
6. DEATH[x][y]=0;
7. PLANET[x][y]=char_to_cell('W');
8. BIRTH[x][y]=0;
9. return DEAD;
10. }
11. if(DEATH[x][y]<pw->sd){
12. DEATH[x][y]++;
13. }
14. if (BIRTH[x][y]<pw->sb){
15. BIRTH[x][y]++;
16. return ALIVE;
17. }
18. if (BIRTH[x][y]==pw->sb) {
19. BIRTH[x][y]=0;
20. inizialize_motion(pw, x, y, move);
21. i=partialsort(move, 'W');
22. if(!i){
23. return ALIVE;
24. }
25. new_coordinate(x, y, k, l, rand%i, move);
26. return ALIVE;
27. }
28. return ERROR;
29.}
18
Total of 9 branches in 50 lines of code](https://image.slidesharecdn.com/slides-210928163640/85/Introduction-to-FPGA-acceleration-18-320.jpg)
![Metrics
$ perf record -e branch,branch-misses `./wator
[ perf record: Woken up 108 times to write data ]
[ perf record: Captured and wrote 28.441 MB perf.data (620737 samples) ]
$ perf report -n --symbols=main_loop
$
19](https://image.slidesharecdn.com/slides-210928163640/85/Introduction-to-FPGA-acceleration-19-320.jpg)






































Introduction to FPGA acceleration
- 1. Introduction to FPGA acceleration Marco Barbone [email protected] Introduction to FPGA acceleration 14/04/2021
- 2. About me 2 • M.Sc. in Computer Science and Networking Scuola superiore Sant’Anna & Università di Pisa • CERN OpenLab Summer student • Research Software Engineer, Maxeler Technologies • Ph.D. Student, Custom Computing research group, Imperial College London, Supervisor Prof. Wayne Luk • Member of Imperial College CMS group • Associate Ph.D. Student, The Institute of Cancer Research, London
- 3. What is an FPGA? 3 https://www.xilinx.com/content/dam/xilinx/imgs/kits/u200-hero-p.jpg https://www.intel.com/content/dam/altera-www/global/en_US/support/boards- kits/stratix10/mx_fpga/stratix10mxboardtop.jpg/_jcr_content/renditions/cq5dam.web.1920.1080.jpeg https://en.wikipedia.org/wiki/Field-programmable_gate_array A field-programmable gate array (FPGA) is an integrated circuit designed to be configured by a customer or a designer after manufacturing – hence the term "field- programmable".
- 4. Microsoft’s Project Brainwave “Microsoft’s Project Brainwave is a deep learning platform for real-time AI inference in the cloud and on the edge. A soft Neural Processing Unit (NPU), based on a high-performance field-programmable gate array (FPGA), accelerates deep neural network (DNN) inferencing, with applications in computer vision and natural language processing. Project Brainwave is transforming computing by augmenting CPUs with an interconnected and configurable compute layer composed of programmable silicon.” 4 https://www.microsoft.com/en-us/research/project/project-brainwave/ https://www.microsoft.com/en-us/research/blog/microsoft-unveils-project-brainwave/
- 5. Amazon EC2 F1 instances use FPGAs to enable delivery of custom hardware accelerations. F1 instances are easy to program and come with everything you need to develop, simulate, debug, and compile your hardware acceleration code, including an FPGA Developer AMI and supporting hardware level development on the cloud. Using F1 instances to deploy hardware accelerations can be useful in many applications to solve complex science, engineering, and business problems that require high bandwidth, enhanced networking, and very high compute capabilities. Examples of target applications that can benefit from F1 instance acceleration are genomics, search/analytics, image and video processing, network security, electronic design automation (EDA), image and file compression and big data analytics. Amazon EC2 F1 https://aws.amazon.com/ec2/instance-types/f1/ 5
- 6. The DRAGEN Platform enables labs of all sizes and disciplines to do more with their genomic data. The DRAGEN Platform uses highly reconfigurable field-programmable gate array technology (FPGA) to provide hardware-accelerated implementations of genomic analysis algorithms, such as BCL conversion, mapping, alignment, sorting, duplicate marking, and haplotype variant calling. DNA Sequencing: DRAGEN Platform 6 https://www.illumina.com/products/by-type/informatics-products/dragen-bio-it-platform.html
- 7. The dataflow architecture for Smith-Waterman Matrix-fill and Traceback alignment stages, to perform short-read alignment on NGS data that delivers ×18 speedup over the respective Bowtie2 standalone components, while our codesigned Bowtie2 demonstrates a 35% boost in performance. Genomics DNA sequencing 7 https://ieeexplore.ieee.org/document/8892144
- 8. 8 Circuits Electrons Microarchitecture Program Machine Language Interpreter Circuits Electrons Microarchitecture Program Machine Language Circuits Electrons Program Microarchitecture Interpreted program Compiled program FPGA implementation Performance Fixed Programmable FPGAs fill the gap between software and hardware
- 9. Field Programmable Gate Array • FPGA is a reconfigurable substrate – Reconfigurable functions, interconnection of functions, input/output • FPGAs fill the gap between software and hardware – higher throughput than software – lower latency than software – more flexibility than hardware 9 Onur Mutlu, Digital Design and Computer Architecture, Spring 2020 Not always true!
- 10. Latency FPGAs achieve lower latency than software: – latency in the order of microseconds – latency constant and predictable CPUs are not suitable as thread overhead is ≈ 10 microseconds GPUs are even worse since PCIe bus sys-call requires milliseconds Examples: – Ultra low latency trading – CERN trigger system 10 https://www.velvetech.com/blog/fpga-in-high-frequency-trading/ https://indico.cern.ch/event/557251/contributions/2245644/attachments/1310074/2143323/thea_trg_intro_isotdaq2017.pdf
- 11. Throughput 11 𝒙𝟎 → 𝒇() → 𝒚𝟎 𝒙𝟏 → 𝒇() → 𝒚𝟏 𝒙𝟐 → 𝒇() → 𝒚𝟐 𝒙𝟑 → 𝒇() → 𝒚𝟑 𝒙𝟒 → 𝒇() → 𝒚𝟒 𝒙𝟓 → 𝒇() → 𝒚𝟓 𝒙𝟔 → 𝒇() → 𝒚𝟔 𝒙𝟕 → 𝒇() → 𝒚𝟕
- 12. Throughput 12 Maxeler MaxCompiler 𝒇()𝒇() 𝒇()𝒇() 𝒇()𝒇() 𝒇()𝒇() 𝒇()𝒇() 𝒇()𝒇() 𝒇()𝒇() 𝒇()𝒇() 𝒇()𝒇()
- 13. FPGA Accelerator Card 13 https://eu.mouser.com/ Price $8,707.34
- 15. CPU 15 https://www.amazon.com/ 64 cores Price $4,985 + RAM FPGA: $8,707.34 64-CORE CPU: $4,985 + RAM 5120 CUDA cores GPU: $8,999
- 16. • FPGA have higher throughput than CPUs (and GPUs) if the workload: – Has many branch mispredictions – Has many cache faults • CPU: Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz • L1 latency = 2 cycles • L2 latency = 15 cycles • L3 latency = 32 cycles 16 https://github.com/DiamonDinoia/cpp-learning/blob/master/cache-latency/cache_test.c
- 17. 1. void main_loop() { 2. while (true) { 3. for (x=0; x<ROW; x++) { 4. for(y=0;y<COL;y++){ 5. switch (cell_to_char(PLANET[x][y])) { 6. case 'S': 7. if(UPDATE[x][y]==0 && shark_rule2(pw, x, y, k, l)==ALIVE) { 8. shark_rule1 (pw ,x , y, k, l); 9. } 10. break; 11. case 'F': 12. if(UPDATE[x][y]==0){ 13. fish_rule4(pw, x, y, k, l); 14. fish_rule3(pw, x, y, k, l); 15. } 16. break; 17. } 18. } 19. } 20. } 21.} 17 https://github.com/DiamonDinoia/wator/ Simulator example
- 18. 1. int shark_rule2 (wator_t* pw, int x, int y, int *k, int* l){ 2. int i=0; 3. long rand=random(); 4. motion move[4]; 5. if (DEATH[x][y]==pw->sd) { 6. DEATH[x][y]=0; 7. PLANET[x][y]=char_to_cell('W'); 8. BIRTH[x][y]=0; 9. return DEAD; 10. } 11. if(DEATH[x][y]<pw->sd){ 12. DEATH[x][y]++; 13. } 14. if (BIRTH[x][y]<pw->sb){ 15. BIRTH[x][y]++; 16. return ALIVE; 17. } 18. if (BIRTH[x][y]==pw->sb) { 19. BIRTH[x][y]=0; 20. inizialize_motion(pw, x, y, move); 21. i=partialsort(move, 'W'); 22. if(!i){ 23. return ALIVE; 24. } 25. new_coordinate(x, y, k, l, rand%i, move); 26. return ALIVE; 27. } 28. return ERROR; 29.} 18 Total of 9 branches in 50 lines of code
- 19. Metrics $ perf record -e branch,branch-misses `./wator [ perf record: Woken up 108 times to write data ] [ perf record: Captured and wrote 28.441 MB perf.data (620737 samples) ] $ perf report -n --symbols=main_loop $ 19
- 21. Workload Examples FPGA GPU Sparse Matrix Dense Matrix Sparse Graph Dense Graphs Graph Neural Network Convolutional Neural Network Decision tree (Monte-Carlo) Simulation Genomics computation 21 https://ieeexplore.ieee.org/document/8685122
- 22. 22 Particle Proton Electron Photon Process a Process b Process c Process n
- 23. FPGA Programming
- 24. FPGA Design Flow 24 Problem Definition Hardware Description Language (HDL) Verilog, VHDL Bitstream Generation Logic Synthesis Placement and Routing Programming the FPGA Xilinx Vivado Intel Quartus High-level Synthesis (HLS) Google XLS MaxCompiler Vivado HLS oneAPI Place & Route might take days!
- 25. 25 CPU GPU FPGA Engineering time short medium very long Compilation time short short very long Debugging easy medium hard Maintainability easy medium hard
- 26. • Avoid running Place and Route – Simulate VHDL, Verilog using ModelSim • ModelSim is slow! – It is possible to execute very small testbenches in a reasonable amount of time 26
- 27. FPGA Design Flow 27 Problem Definition Hardware Description Language (HDL) Bitstream Generation Logic Synthesis Placement and Routing Programming the FPGA High-level Synthesis (HLS)
- 28. 28 https://github.com/google/xls It generates a X86-64 executable from source
- 29. High-level Synthesis (HLS) • Using HLS toolchains makes unit testing possible in a reasonable amount of time • It is easy to interface with a reference software implementation to compare the results • It makes FPGA programming much less cumbersome 29
- 30. 1. double_multiplier multiplier_39759952( 2. .clk(clk), 3. .rst(rst), 4. .input_a(wire_39069600), 5. .input_a_stb(wire_39069600_stb), 6. .input_a_ack(wire_39069600_ack), 7. .input_b(wire_39795024), 8. .input_b_stb(wire_39795024_stb), 9. .input_b_ack(wire_39795024_ack), 10. .output_z(wire_39795168), 11. .output_z_stb(wire_39795168_stb), 12. .output_z_ack(wire_39795168_ack)); 30 https://github.com/dawsonjon/fpu/blob/master/double_multiplier/test_bench.v Double floating-point multiplication in Verilog Using a library function!
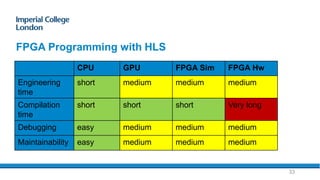
- 33. FPGA Programming with HLS 33 CPU GPU FPGA Sim FPGA Hw Engineering time short medium medium medium Compilation time short short short Very long Debugging easy medium medium medium Maintainability easy medium medium medium
- 34. HLS • Advantages: – simplify programming – reduces engineering time – Allows “rapid prototyping” • Disadvantages: – Nowadays HLS still achieves less performance than hand-written optimized Verilog/VHDL 34
- 35. Performance • HLS still requires significant engineering effort depending on the size of the problem • Hardware builds still take significant amount of time • What if the FPGA does not perform as hoped? • Reengineer the problem and start from scratch? • Optimize the code a build several times? 35
- 37. To understand the major factors that dictate performance when using compute co-processors – Bandwidths and latencies of the various interconnects – The capacities of different memories – Impact of data movements – Accelerator specific properties, e.g., for FPGA • Hardware/arithmetic operations space • Clock frequency • Fine-grain tunable numeric operations and their impact • Other custom computing approaches, e.g., compression Accelerator compute capabilities Objective Georgi Gaydadjiev, Advanced Parallel Programming 2019-20
- 38. FPGA Performance • FPGA Performance is predictable • There is no context switch, garbage collector or any background process • The bitstream will be executed the same number of clock cycles every time • The number of clock cycles needed can be computed easily Further read: Nils Voss et al. (2021), On Predictable Reconfigurable System Design 38 https://doi.org/10.1145/3436995
- 39. Modern AMD PC Architecture 39 https://hexus.net/tech/features/mainboard/131789-amd-ryzen-3000-supporting-x570-chipset-examined/
- 40. Xilinx Alveo U250 Data Center Accelerator Card 40 64 GB DDR4 @600MHz 4 channels of 64-bit 16G RDIMMs available bandwidth: 77 GB/s or 2,400 MT/s 16x PCI-Express Power = 225W 100 Gbit Eth (QSFP28) x 2 54MB On-chip Memory available at 38 TB/s Georgi Gaydadjiev, Advanced Parallel Programming 2019-20
- 41. PCIe 3.0 (x16) 15.75 GB/s PCIe 4.0 (x16) 31.51 GB/s Modern System Architecture 41 77 GB/s 100 Gbit Ethernet https://en.wikipedia.org/wiki/DDR4_SDRAM https://en.wikipedia.org/wiki/List_of_AMD_Ryzen_processors https://www.xilinx.com/products/boards-and- kits/alveo/u250.html
- 42. 42 Våge, Liv H CMS Particle Track Reconstruction Callgraph Bottleneck
- 43. 1. If compute bound -> optimize the algorithm, increase clock frequency 2. If I/O bound, find a strategy to reduce the I/O (caching, compression accelerate other portion of the code) 3. Repeat until theoretical limit reached 43
- 46. Performance Model example 46 Setup Total time (s) DFE + NUFFT on CPU 16.07058 All on CPU (C++) 24.72233 All on CPU (MATLAB) 65.118 CPU + NUFFT on GPU 18.43535 DFE + NUFFT on GPU 9.78360
- 47. FPGA Design Flow (simplified) 47 Problem Definition Hardware Description Language (HDL) Bitstream Generation Logic Synthesis Placement and Routing Programming the FPGA Modelling and performance prediction High-level Synthesis (HLS) Final Architecture Architecture Benchmark
- 48. Current projects
- 49. MR-Linac Source: https://www.icr.ac.uk/news-features/mr-linac combines an MRI scanner and a linear particle accelerator
- 50. Monte Carlo Real Time Adaptive Radiotherapy New computing challenges
- 51. 108 particles needs to be simulated to achieve statistical significance The stochastic behaviour breaks the pipeline of modern CPUs Not suitable for GPU due to the lack of branch-predictors Random memory accesses due to many lookup tables Modern CPU and GPU implementations take more than 1 minute (Ziegenhein2015) Other cloud-based approaches have reliability concerns (Ziegenhein2017) Expensive 51 Source: https://iopscience.iop.org/article/10.1088/0031-9155/60/15/6097/meta https://iopscience.iop.org/article/10.1088/1361-6560/aa5d4e/meta
- 52. Assuming rng uniformly distributed: if(rng.getRandom() < 0.5) then f(x) else g(y) In the GPU case branches can significantly affect the instruction throughput by causing threads of the same warp to diverge. The diverging branches are de-scheduled! Worst-case for branch predictors 52
- 53. On-going project that aims to accelerate track reconstruction using FPGA accelerators (Våge, Liv) CMS Particle Track Reconstruction 53 https://www.researchgate.net/publication/260003686_Empirical_Bayes_unfolding_of_elementary_particle_spectra_at_the_Large_Hadron_Collider
- 54. Summary • FPGAs are becoming widely used in industry as accelerators for suitable challenges (ultra low latency inference, graph processing and genomics) • FPGAs widely used in HEP close to detector (trigger systems) • Recent toolchain developments making programming FPGAs more accessible • Potential applications in HEP starting to be studied 54
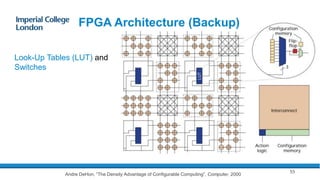
- 55. FPGA Architecture (Backup) 55 Look-Up Tables (LUT) and Switches Andre DeHon, “The Density Advantage of Configurable Computing”, Computer, 2000
- 56. 3-bit input LUT (3-LUT) 56 input (3 bits) output (1 bit) Data Input Multiplexer (Mux): Selects one of the data input corresponding to select input 3 Select Input 0 0 0 0 0 1 0 1 0 0 1 1 1 0 0 1 0 1 1 1 0 1 1 1 3-LUT can implement any 3-bit input function Onur Mutlu, Digital Design and Computer Architecture, Spring 2020
- 59. 59