





















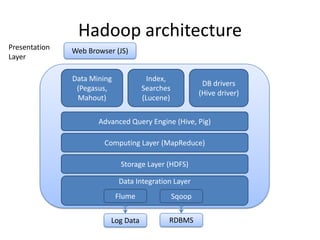



The document presents an introduction to Hadoop and MapReduce, focusing on big data characteristics and the challenges associated with it. It explains Hadoop's architecture and the MapReduce programming model, detailing how data processing is optimized for large datasets. The content includes historical context, comparisons with traditional RDBMS, and a demonstration of Hadoop on Google Cloud's infrastructure.




























































































