


































Introduction to HiveQL
- 1. Introduction to HiveQL BY KRISTIN FERRIER
- 2. About Me – Kristin Ferrier 15+ Years in IT (Software development and BI development) 10+ years experience with SQL Server and 5+ years experience with Oracle Co-founder OKCSQL Currently Sr. Data Analyst at an energy company Social Media Twitter: @SQLenergy Blog: http://www.kristinferrier.com
- 3. Agenda Hadoop – Very High Level Hive and HiveQL - High Level Getting started with Hive and HiveQL HiveQL examples Resources for getting started with HiveQL
- 4. Hadoop Open source software Popular for storing, processing, and analyzing large volumes of data For example, web logs or sensor data Main distributions Cloudera Hortonworks MapR (has some proprietary components)
- 5. Hadoop 2.0 Main Components Hadoop Distributed File System (HDFS) Handles the data storage MapReduce Handles the processing Works with key value pairs Often written in Java Can be written in any scripting language using the Streaming API of Hadoop
- 6. Example MapReduce Code public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, one); } } } Code from Hortonworks tutorial found at http://hortonworks.com/hadoop-tutorial/introducing-apache-hadoop-developers/
- 7. Getting Started with Hadoop What if I don’t know Java? Or one of the Scripting languages using the Streaming API of Hadoop Example: Python That’s OK. If you know SQL, then Hive and HiveQL may be a great starting point for your Hadoop learning
- 8. Hive Hive essentially allows us to use tables within Hadoop Built on top of Apache Hadoop Can access files stored in HDFS or HBase HCatalog allows you to apply table structures to the data HiveQL to query the data
- 9. HiveQL HiveQL is SQL-like language for querying data from Hive Follows some of the ANSI SQL-92 standard Offers its own extensions Implicitly turned into MapReduce jobs
- 10. HiveQL – Key SQL items it has SELECT FROM WHERE GROUP BY HAVING JOINS – Some kinds
- 11. HiveQL – Key differences from SQL No transactions No materialized views Update and delete available only with Hive 0.14 and later Hive 0.14 was released November 2014
- 12. Accessing Hive Hue Web interface for Hadoop Beeswax Hive UI within Hue
- 13. Hue
- 14. Beeswax
- 15. Getting Data into Hive Tables One way is to import a file into Hive Can create the table at this time Can import the data at this time File can even come from a Windows box
- 16. Importing a file Beeswax Tables Create a new table from a file
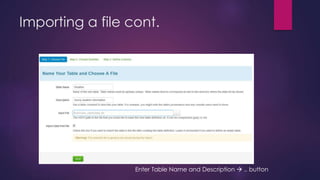
- 17. Importing a file cont. Enter Table Name and Description .. button
- 18. Importing a file cont. Upload a file Select your Windows file Open
- 19. Importing a file cont. After file uploads, double-click your file
- 20. Importing a file cont. Choose a Delimiter
- 21. Importing a file cont. Select column data types Create Table
- 22. Importing a file cont. Table has been created
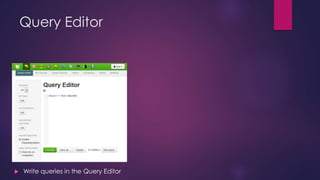
- 23. Query Editor Write queries in the Query Editor
- 24. Select SELECT * FROM WEATHER
- 25. Where, Group By, Min/Max
- 26. Where, Group By, Min/Max - Results
- 27. Aliasing, Ordering Standard SQL syntax for Aliasing SORT BY instead of ORDER BY– For ordering
- 28. Aliasing, Ordering - Results
- 29. Joins INNER, LEFT, RIGHT, and FULL OUTER Equi Joins only: (table1.key = table2.key) is allowed but not (table1.key <> table2.key) Extensions exist like LEFT SEMI JOIN
- 30. INNER JOIN
- 31. INNER JOIN - Results
- 32. LEFT SEMI JOIN Left Semi Joins are less necessary starting with Hive 0.13 As of Hive 0.13 the IN/NOT IN/EXISTS/NOT EXISTS operators are supported using subqueries SELECT a.key, a.value FROM a WHERE a.key in (SELECT b.key FROM B); can be rewritten to SELECT a.key, a.val FROM a LEFT SEMI JOIN b ON (a.key = b.key) Example from https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Joins
- 33. Performance Queries can take minutes to run. Focus is on analysis of large data sets. Relational databases are still a strong solution for providing the faster performance of CRUD (create, read, update, and delete) operations required by OLTP systems.
- 34. Summary Hive essentially allows us to use tables in Hadoop We can query them using HiveQL, which is similar to SQL Knowing how to write MapReduce code is not required, as the HiveQL will be turned into MapReduce for us
- 35. Getting Started Yourself Hortonworks Sandbox Portable Hadoop environment with tutorials Even though the sandbox runs Hadoop on Linux, you can run the sandbox on your Windows machine and access it via a web browser Available at http://hortonworks.com/sandbox
- 36. Getting Started Yourself Hive DML Reference https://cwiki.apache.org/confluence/display/hive/languageManual+dml Apache’s Hive Language Manual https://cwiki.apache.org/confluence/display/Hive/LanguageManual Treasure’s HiveQL Reference http://docs.treasuredata.com/articles/hive Network World – Comparing the top Hadoop Distros http://www.networkworld.com/article/2369327/software/comparing-the- top-hadoop-distributions.html
- 37. Contact Info Social Media Twitter: @SQLenergy Blog: http://www.kristinferrier.com