Introduction to Microsoft's Big Data Platform and Hadoop Primer
Download as PPTX, PDF0 likes403 views

The document provides an overview of Microsoft's big data platform and the Hadoop framework, detailing the complexities of big data, including its volume, velocity, and variety. It contrasts traditional RDBMS with MapReduce, emphasizing how Hadoop handles large-scale data processing through distributed computing, auto-replication, and a focus on commodity hardware. Additionally, it touches on Microsoft Azure's deployment models for Hadoop, highlighting various integration points and tools available for users.








![// Map Reduce is broken out into a Map function and reduce function
// ------------------------------------------------------------------
// Sample Map function: tokenizes string and establishes the tokens
// e.g. “a btcnd” is now an key value pairs representing [a, b, c, d]
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
// Sample Reduce function: does the count of these key value pairs
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException,
InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
Sample Java MapReduce WordCount Function](https://image.slidesharecdn.com/24hopsept2012dennyl-160605030737/85/Introduction-to-Microsoft-s-Big-Data-Platform-and-Hadoop-Primer-9-320.jpg)
![// Sample Generated Log
588.891.552.388,-,08/05/2011,11:00:02,W3SVC1,CTSSVR14,-,-,0,-
,200,-,GET,/c.gif,Mozilla/5.0 (Windows NT 6.1; rv:5.0)
Gecko/20100101 Firefox/5.0,http://foo.live.com/cid-
4985109174710/blah?fdkjafdf,[GUID],-,MSFT,
&PageID=1234&Region=89191&IsoCy=BR&Lang=1046&Referrer=hotmail.c
om&ag=2385105&Campaign=&Event=12034
GUID PUID Parameters
[GUID] [PUID] &PageID=1234&Region=89191&IsoCy=BR&Lang=104
6&Referrer=hotmail.com&ag=2385105&Campaign=
&Event=12034
select
GUID,
str_to_map("param", "&", "=")["IsoCy"],
str_to_map("param", "&", "=")["Lang"]
from
weblog;
HiveQL: SQL-like language
• Write SQL-like query which becomes
MapReduce functions
• Includes functions like str_to_map so one can
perform parsing functions in HiveQL
Query a Sample WebLog using HiveQL](https://image.slidesharecdn.com/24hopsept2012dennyl-160605030737/85/Introduction-to-Microsoft-s-Big-Data-Platform-and-Hadoop-Primer-11-320.jpg)





















Introduction to Microsoft's Big Data Platform and Hadoop Primer
- 1. Global Sponsors: Introduction to Microsoft's Big Data Platform and Hadoop Primer Denny Lee, Principal Program Manager Big Data – it’s not just about web and social
- 2. BIG DATA Audio / Video Log Files Text/Image Social Sentiment Data Market Feeds eGov Feeds Weather Wikis / Blogs Click Stream Sensors / RFID / Devices Spatial & GPS Coordinates WHAT IS BIG DATA? Mobile WEB 2.0 Advertising Collaboration eCommerce Digital Marketing Search Marketing Web Logs Recommendations Contacts Deal Tracking Sales Pipeline ERP / CRM Payables Payroll Inventory Data Complexity: Variety and Velocity Terabytes Gigabytes Megabytes Petabytes
- 3. How do I optimize my fleet based on weather and traffic patterns? What’s the social sentiment for my brand or products How do I better predict future outcomes?
- 4. A Definition of Big Data - 4Vs: volume, velocity, variability, variety Big data: techniques and technologies that make handling data at extreme scale economical.
- 5. Scale Up! With the power of the Hubble telescope, we can take amazing pictures 45M light years away Amazing image of the Antennae Galaxies (NGC 4038-4039) Analogous with scale up: • non-commodity • specialized equipment • single point of failure*
- 6. Scale Out | Commoditized Distribution Hubble can provide an amazing view Giant Galactic Nebula (NGC 3503) but how about radio waves? • Not just from one area but from all areas viewed by observatories • SETI @ Home: 5.2M participants, 1021 floating point operations1, 769 teraFLOPS2 Analogous with commoditized distributed computing • Distributed and calculated locally • Engage with hundreds, thousands, + machines • Many points of failure, auto-replication prevents this from being a problem
- 7. What is Hadoop? • Synonymous with the Big Data movement • Infrastructure to automatically distribute and replicate data across multiple nodes and execute and track map reduce jobs across all of those nodes • Inspired by Google’s Map Reduce and GFS papers • Components are: Hadoop Distributed File System (HDFS), Map Reduce, Job Tracker, and Task Tracker • Based on the Yahoo! “Nutch” project in 2003, became Hadoop in 2005 named after Doug Cutting’s son’s toy elephant Reference: http://en.wikipedia.org/wiki/File:Hadoop_1.png Map Reduce Layer HDFS Layer Task tracker Job tracker Task tracker Name node Data node Data node
- 8. Comparing RDBMS and MapReduce Traditional RDBMS MapReduce Data Size Gigabytes (Terabytes) Petabytes (Hexabytes) Access Interactive and Batch Batch Updates Read / Write many times Write once, Read many times Structure Static Schema Dynamic Schema Integrity High (ACID) Low (BASE) Scaling Nonlinear Linear DBA Ratio 1:40 1:3000 Reference: Tom White’s Hadoop: The Definitive Guide
- 9. // Map Reduce is broken out into a Map function and reduce function // ------------------------------------------------------------------ // Sample Map function: tokenizes string and establishes the tokens // e.g. “a btcnd” is now an key value pairs representing [a, b, c, d] public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } // Sample Reduce function: does the count of these key value pairs public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } Sample Java MapReduce WordCount Function
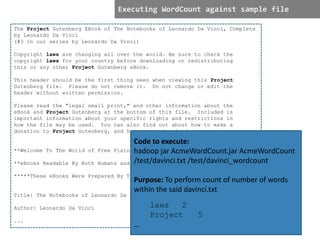
- 10. The Project Gutenberg EBook of The Notebooks of Leonardo Da Vinci, Complete by Leonardo Da Vinci (#3 in our series by Leonardo Da Vinci) Copyright laws are changing all over the world. Be sure to check the copyright laws for your country before downloading or redistributing this or any other Project Gutenberg eBook. This header should be the first thing seen when viewing this Project Gutenberg file. Please do not remove it. Do not change or edit the header without written permission. Please read the "legal small print," and other information about the eBook and Project Gutenberg at the bottom of this file. Included is important information about your specific rights and restrictions in how the file may be used. You can also find out about how to make a donation to Project Gutenberg, and how to get involved. **Welcome To The World of Free Plain Vanilla Electronic Texts** **eBooks Readable By Both Humans and By Computers, Since 1971** *****These eBooks Were Prepared By Thousands of Volunteers!***** Title: The Notebooks of Leonardo Da Vinci, Complete Author: Leonardo Da Vinci ... Code to execute: hadoop jar AcmeWordCount.jar AcmeWordCount /test/davinci.txt /test/davinci_wordcount Purpose: To perform count of number of words within the said davinci.txt laws 2 Project 5 … Executing WordCount against sample file
- 11. // Sample Generated Log 588.891.552.388,-,08/05/2011,11:00:02,W3SVC1,CTSSVR14,-,-,0,- ,200,-,GET,/c.gif,Mozilla/5.0 (Windows NT 6.1; rv:5.0) Gecko/20100101 Firefox/5.0,http://foo.live.com/cid- 4985109174710/blah?fdkjafdf,[GUID],-,MSFT, &PageID=1234&Region=89191&IsoCy=BR&Lang=1046&Referrer=hotmail.c om&ag=2385105&Campaign=&Event=12034 GUID PUID Parameters [GUID] [PUID] &PageID=1234&Region=89191&IsoCy=BR&Lang=104 6&Referrer=hotmail.com&ag=2385105&Campaign= &Event=12034 select GUID, str_to_map("param", "&", "=")["IsoCy"], str_to_map("param", "&", "=")["Lang"] from weblog; HiveQL: SQL-like language • Write SQL-like query which becomes MapReduce functions • Includes functions like str_to_map so one can perform parsing functions in HiveQL Query a Sample WebLog using HiveQL
- 12. Traditional RDBMS: Move Data to Compute As you process more and more data, and you want interactive response • Typically need more expensive hardware • Failures at the points of disk and network can be quite problematic It’s all about ACID: atomicity, consistency, isolation, durability Can work around this problem with more expensive HW and systems • Though distribution problem becomes harder to do
- 13. Hadoop (and NoSQL in general) follows the Map Reduce framework • Developed initially by Google -> Map Reduce and Google File system • Embraced by community to develop MapReduce algorithms that are very robust • Built Hadoop Distributed File System (HDFS) to auto-replicate data to multiple nodes • And execute a single MR task on all/many nodes available on HDFS Use commodity HW: no need for specialized and expensive network and disk Not so much ACID, but BASE (basically available, soft state, eventually consistent) Hadoop / NoSQL: Move Compute to the Data
- 14. Hadoop: Auto-replication • Hadoop processes data in 64MB chunks and then replicates to different servers • Replication value set at the hdfs-site.xml, dfs.replication node
- 15. Windows ServerHadoopOnAzure.com Preview (current) MICROSOFT HADOOP DEPLOYMENT MODELS • On-demand Elastic Hadoop Cluster • Complete elasticity • Simplified management and deployment • Pay only compute cycles used On-Demand Virtual Clusters • Dedicated Hadoop cluster in the Cloud • Dedicated workloads w/ more stringent storage and latency requirements • Some elasticity • Dedicated Hadoop cluster on Windows Server • On-Premise workloads • Management Integration
- 16. WHAT’S IN HADOOP ON AZURE AND WINDOWS Excel Hive Add-In Hadoop Apache Pig Interactive Console (Hive, JS) CLR / .NET HDFS Connectivity * HDFS / Azure and Data Market Integration Metro UI Extensive Samples HiveODBC SQOOP
- 17. 17 Hadoop on Azure in Action
- 19. 19
- 28. 28
- 30. New Opportunities New Insights Data Scientist Casual User Information Worker Volume Variety Velocity Ref: ARC306 - Cloud Data Analytics: Challenges and Opportunities
- 31. For More Information Please Visit: HadoopOnAzure.com
- 33. Global Sponsors: Thank You for Attending
Editor's Notes
- #3: ERP, SCM, CRM, and transactional Web applications are classic examples of systems processing Transactions. Highly structured data in these systems is typically stored in SQL databases. Web 2.0 are about how people and things interact with each other or with your business. Web Logs, User Click Streams, Social Interactions & Feeds, and User-Generated Content are classic places to find Interaction data. Ambient data tends is coming “Internet of Things”. Mary Meeker has predicted 10B connected devices by 2015. Sensors for heat, motion, pressure and RFID and GPS chips within such things as mobile devices, ATM machines, and even aircraft engines provide just some examples of “things” that output ambient signals… There are multiple types of data personal - > organizational - > public - > private So we should NOT minimize our thinking to just data that flows through an organization. Ex. The mortgage-related data you may have COULD benefit from being blended with external data found in Zillow, for example. Moreover, the government has the Open Data Initiative. Which means that more and more data is being made publicly available.
- #4: Today new types of questions are being asked to drive the business. These questions include: Questions on Social & Web Analytics e.g. What is my brand and product sentiment? How effective is my online campaign? Who am I reaching? How can I optimize or target the correct audience? Questions that require connecting to live data feeds e.g. a large shipping company uses live weather feeds and traffic patterns to fine tune its ship and truck routes leading to improved delivery times and cost savings. Retailers analyze sales, pricing and economic, demographic and live weather data to tailor product selections at particular stores and determine the timing of price markdowns. Questions that require advanced analytics e.g. Financial firms using machine learning to build better fraud detection algorithms that go beyond the simple business rules involving charge frequency and location to also include an individual’s customized buying patterns ultimately leading to a better customer experience. Organizations that are able to take advantage of Big Data to ask and answer these new types of questions will be able to more effectively differentiate and derive new value for the business whether it is in the form of revenue growth, cost savings or creating entirely new business models. Gartner asserts that “By 2015 businesses that build a modern information management system will outperform their peers financially by 20 percent.” McKinsey agrees, confirming that organizations that use data and business analytics to drive decision making are more productive and deliver higher return on equity than those who don’t.
- #5: http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data
- #6: Taken by Hubble telescope: The Antennae Galaxies/NGC 4038-4039 http://hubblesite.org/gallery/album/galaxy/pr2006046a/xlarge_web/
- #7: Hubble Telescope view of Giant Galactic Nebula NGC 3503 -> to -> SETI @ Home SETI @ Home Stats: 1021 floating point operations on 9/26/2001 769 teraFLOPS on 11/14/2009
- #20: Hadoop on Azure Starting screen to spin up your HoA cluster.
- #21: Creation of cluster
- #22: Once cluster is created, Live Tile style interface good for both desktops and mobile devices
- #23: Load file (input.txt) up to HoA cluster by using the fs.put() method
- #24: From the Interactive JavaScript console, you can run Pig queries initiated right from you browser
- #25: Interactive Javascript allows you to visualize the results of your Big Data right from the browser window
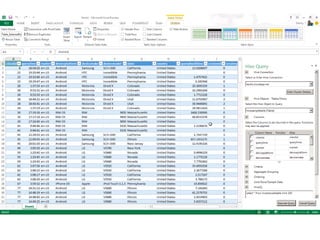
- #26: Execute Hive queries against the browser window.
- #28: PowerPivot connecting to the same Hive Mobile Sample table within Hadoop on Azure
- #29: Power View report based on the PowerPivot on Hadoop on Azure
- #30: Excel 2013 PowerView on Hadoop on Azure