








![Most statistical NLP/IR work regards words as atomic symbols:
• book, information, university
In vector space, this is a sparse vector with one 1 and a lot of zeros
• book → [0 0 0 1 0 0 0 0 0 0]
• university → [0 0 0 0 0 0 0 0 1 0]
Problem:
• The dimensionality of the vector will be the size of vocabulary
• No semantic relationship between word vectors’ representations](https://image.slidesharecdn.com/introtonir-240727201841-b01c3ae9/85/Introduction-to-Neural-Information-Retrieval-and-Large-Language-Models-10-320.jpg)






























![• [CLS]
• [SEP]
• [MASK]
• [PAD]
BERT Special Symbols](https://image.slidesharecdn.com/introtonir-240727201841-b01c3ae9/85/Introduction-to-Neural-Information-Retrieval-and-Large-Language-Models-44-320.jpg)
















Introduction to Neural Information Retrieval and Large Language Models
- 1. Introduction to Neural Information Retrieval Sajad Ebrahimi – M.A.Sc in Computer Engineering at UoG [email protected]
- 2. Outline 1. IR through the Ages 2. Text Embedding 3. Word2Vec in detail 4. FastText 5. Seq2Seq Model / Encoder-Decoder architecture / Attention / Transformers 6. BERT Intuition and Applications 7. Using Language Models for retrieval a. Why Language Models are Useful? b. Bi-Encoder vs. Cross-Encoder c. HuggingFace 8. Let’s code together a. Load a dataset b. Get the embeddings c. Calculate the similarity d. Compare models
- 3. IR through the ages
- 4. • There are two possible outcomes: TRUE (Document matches the Query) or FALSE • Query is specified using Boolean logic operators: AND, OR, NOT • Ranking? Boolean Retrieval
- 5. Indexing
- 7. Behrooz Mansoori, “Introduction to Information Retrieval”, 2022
- 8. The fundamental idea behind text embedding is to capture the contextual and semantic information of words and phrases in a way that can be used for various NLP tasks, such as text classification, sentiment analysis, information retrieval, machine translation, and more. 1. Numerical Representation 2. Semantic Information 3. Feature Engineering 4. Dimensionality Reduction 5. Transfer Learning What is Text Embedding?
- 9. ● One-hot vectors map objects into a vector of fixed-length ● We have not captured any semantic relationships ○ Is there a relationship between man and king? ● We would like to develop a model in which ○ King - Man + Woman → Queen ○ Apple Inc. vs Apple (fruit) Motivation
- 10. Most statistical NLP/IR work regards words as atomic symbols: • book, information, university In vector space, this is a sparse vector with one 1 and a lot of zeros • book → [0 0 0 1 0 0 0 0 0 0] • university → [0 0 0 0 0 0 0 0 1 0] Problem: • The dimensionality of the vector will be the size of vocabulary • No semantic relationship between word vectors’ representations
- 11. WORD2VEC
- 12. The output probabilities are going to relate to how likely it is to find each vocabulary word near our input word ● e.g, for the input word “Soviet”, the output probabilities are going to be much higher for words like “Union” and “Russia” than for unrelated words like “watermelon” and “kangaroo” Train the neural network to do this by feeding it word pairs found in our training documents The intuition
- 13. Window size (context) is a hyperparameter
- 14. ● A word just as a text string to a neural network ○ We need a way to represent the words to the network ○ Build a vocabulary of words from our training documents ● Words are represented by one-hot encoding ○ A vector with the size of a vocabulary ○ 1 if the word is present, otherwise 0 ○ e.g., 1000 for cat ● IT NEEDS TOO MUCH RESOURCES Training Details
- 15. Instead of trying to predict the probability of being a nearby word for all the words in the vocabulary, we try to predict the probability that our training sample words are neighbors or not. Maximizing the similarity of the words in the same context and minimizing it when they occur in different contexts. Negative Sampling
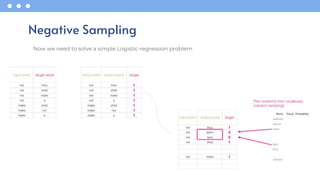
- 16. Now we need to solve a simple Logistic-regression problem Negative Sampling
- 17. The skip-gram neural network model is actually surprisingly simple in its most basic form Two assumptions: ● A word can be used to generate the words surrounding it ● Given the center word, the context words are generated independently Skip Gram Model
- 19. ● The center word is generated based on the context words. Continuous Bag of Words (CBOW) model
- 21. The hidden layer is going to be represented by a weight matrix • 10,000 rows (one for every word in our vocabulary) • 300 columns (one for every hidden neuron) o 300 features is what Google used in their published model trained on the Google news dataset • The end goal of all of this is really just to learn this hidden layer weight matrix • The hidden layer of this model is really just operating as a lookup table The Hidden Layer
- 22. • each output neuron (one per word in our vocabulary) will produce an output between 0 and 1, and the sum of all these output values will add up to 1 The Output Layer
- 23. 1. Lack of Context Sensitivity 2. Out-of-vocabulary Words / Difficulty with Rare Words 3. Semantic Ambiguity (Doesn't Capture Phrase-level Semantics) 4. Domain Specificity 5. Not Capturing Word Order 6. Morphology (eat and eaten) Word2Vec cons
- 24. FastText
- 25. • It was invented to make up the Word2Voc’s shortages like OOV and Morphology • In essence, it is based on the idea of character n-grams FastText Bojanowski et al, FastText n-gram embedding model, 2017
- 26. • For a word, we generate character n-grams of length 3 to 6 present in it • Two-step vector representation updating: 1. First, the embedding for the center word is calculated by taking a sum of vectors for the character n-grams and the whole word itself 2. For the actual context words, we directly take their word vector from the embedding table without adding the character n-grams FastText Training
- 27. 1. High memory requirements 2. Lack of Context Sensitivity 3. Not Capturing Word Order 4. Domain Specificity FastText cons
- 29. • Seq2seq models have evolved, and attention mechanisms have been introduced to address challenges related to capturing long-range dependencies. Seq2Seq Model Sutskever et al. Sequence to Sequence Learning with Neural Networks, 2014
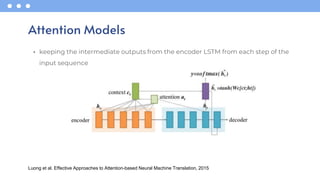
- 32. • keeping the intermediate outputs from the encoder LSTM from each step of the input sequence Attention Models Luong et al. Effective Approaches to Attention-based Neural Machine Translation, 2015
- 33. Attention is all you need! Vaswani et al., Attention is all you need, 2017
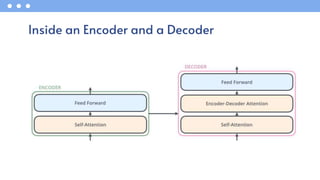
- 34. Inside an Encoder and a Decoder
- 35. Self-Attention
- 36. https://github.com/jessevig/bertviz Want to get a visualized attention?
- 37. BERT
- 38. • BERT makes use of Transformers, an attention mechanism that learns contextual relations between words (or sub-words) in a text • An encoder that reads the text input and a decoder that produces a prediction for the task. Transformer encoder reads the entire sequence of words at once • Since BERT’s goal is to generate a language model, only the encoder mechanism is necessary Introduction Devlin et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, 2019
- 40. It has been trained based on two approaches: 1. Masked LM: mask some percentage of the input tokens at random, and then predict those masked tokens mask 15% of all WordPiece tokens in each sequence at random. 2. Next Sentence Prediction: understanding the relationship between two sentences (50% of positive pairs) Used BooksCorpus (800M words) and Wikipedia (2,500M words) • IT IS EXPENSIVE Pre-training in detail
- 42. BERT Size
- 43. What are the differences? BERTbase BERTlarge Model Size 110M 340M Hidden Layers 12 transformer layers 24 transformer layers Attention Heads 12 16 Hidden Unit Size 768 1024 Total Hidden Units 12 layers * 768 units 24 layers * 1024 units • Obviously, they have differences in training time and required computational resources
- 44. • [CLS] • [SEP] • [MASK] • [PAD] BERT Special Symbols
- 45. Under the hood
- 46. • RoBERTa: A robustly optimized BERT o Facebook AI research team o They used 160GB of text instead of the 16GB dataset originally used to train BERT o Increased the number of iterations from 100K to 300K and then further to 500K o Dynamically changing the masking pattern applied to the training data o Removing the next sequence prediction objective from the training procedure BERT-based Models Liu et al. Roberta: A robustly optimized BERT pretraining approach, 2019
- 47. • DistilBERT: a distilled version of BERT BERT-based Models Sanh et al. in DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter, 2020 BERTbase DistilBERT Model Size 110M 66M Hidden Layers 12 transformer layers 6 transformer layers Attention Heads 12 12 Hidden Unit Size 768 768 Total Hidden Units 12 layers * 768 units 6 layers * 768 units
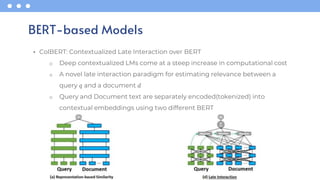
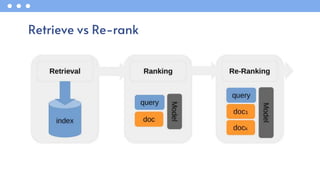
- 48. • ColBERT: Contextualized Late Interaction over BERT o Deep contextualized LMs come at a steep increase in computational cost o A novel late interaction paradigm for estimating relevance between a query 𝑞 and a document 𝑑 o Query and Document text are separately encoded(tokenized) into contextual embeddings using two different BERT BERT-based Models
- 49. • Sentence-BERT: A modification of the pre-trained BERT network that use siamese and triplet network structures to derive semantically meaningful sentence embeddings that can be compared using cosine-similarity BERT-based Models Reimers and Gurevych. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, 2019
- 50. • BertTokenizer • BertModel • BertForMaskedLM • BertForSequenceClassification • BertForMultipleChoice • BertForTokenClassification • BertForQuestionAnswering BERT For X provided by the HuggingFace
- 51. Using LMs for retrieval
- 52. Allows us to answer questions like: o Given that we see “John” and “feels”, how likely will we see “happy” as opposed to “habit” as the next word? o Given that we observe “baseball” three times and “game” once in a news article, how likely is it about sports? o Given that a user is interested in sports news, how likely would the user use “baseball” in a query? Why Language Models are useful?
- 56. • The platform where the machine learning community collaborates on models, datasets, and applications. o Models o Datasets o Spaces o APIs o etc. • An NLP Course provided by the HuggingFace (Highly Recommended): o https://huggingface.co/learn/nlp-course/chapter0/1?fw=pt Hugging Face 🤗
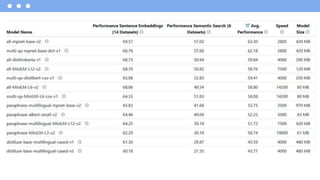
- 58. • Transformers is a Python framework for state-of-the-art sentence, text, and image embeddings. This framework can compute sentence/text embeddings for different languages. • pip install transformers Transformers
- 60. • Try to get the representation of some texts using Word2Vec and BERT • Getting familiar with sentence-transformers library • Use an LLM for retrieving information • Compare the performance of models Find the codes here 👇: https://colab.research.google.com/drive/1T24mWOVisVv0N45- GlAGm8lCreZmzV0v?usp=sharing What are we going to do? 💻
- 61. Any Question?
- 62. Thank you for your attention! • M.A.Sc. in Computer Engineering at University of Guelph • sadjadeb.github.io • Follow Me on X: @sadjadeb • [email protected]
- 63. 1. Bhaskar Mitra and Nick Craswell, “An Introduction to Neural Information Retrieval”, 2018 2. Behrooz Mansoori, “Introduction to Information Retrieval”, 2022 3. Sutskever et al. Sequence to Sequence Learning with Neural Networks, 2014 4. https://towardsdatascience.com/day-1-2-attention-seq2seq-models-65df3f49e263 5. https://data-hub.ir/word2vec 6. https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq- models-with-attention/ 7. https://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time/ 8. Devlin et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, 2019 9. Reimers and Gurevych. Sentence-BERT: Sentence Embeddings using Siamese BERT- Networks, 2019 10. Liu et al. Roberta: A robustly optimized BERT pretraining approach, 2019 11. https://itnext.io/deep-learning-in-information-retrieval-part-iii-ranking-da511f2dc325 References