January 2015 HUG: Using HBase Co-Processors to Build a Distributed, Transactional RDBMS
4 likes4,623 views

The document discusses Splice Machine, a Hadoop-based RDBMS that offers an affordable solution for OLTP applications, providing scale-out, ACID transactions without the need for application rewrites. It emphasizes significant improvements in performance and cost compared to traditional Oracle RAC systems while enabling real-time analytics and cross-channel marketing capabilities. The architecture integrates various data sources and technologies to create a unified customer profile and enhance operational efficiency.






















January 2015 HUG: Using HBase Co-Processors to Build a Distributed, Transactional RDBMS
- 1. Powering OLTP Apps on Hadoop Monte Zweben Co-Founder and CEO January 24, 2015
- 2. 2 Who are We? THE ONLY HADOOP RDBMS Replace your old RDBMS with a scale-out SQL database Affordable, Scale-Out ACID Transactions No Application Rewrites 10x Better Price/Perf
- 3. 3 Campaign Management: Harte-Hanks Overview Digital marketing services provider Unified Customer Profile Real-time campaign management Complex OLTP and OLAP environment Challenges Oracle RAC too expensive to scale Queries too slow – even up to ½ hour Getting worse – expect 30-50% data growth Looked for 9 months for a cost-effective solution Solution Diagram Initial Results ¼ cost with commodity scale out 3-7x faster through parallelized queries 10-20x price/perf with no application, BI or ETL rewrites Cross-Channel Campaigns Real-Time Personalization Real-Time Actions
- 4. 4 Reference Architecture: Operational Apps Provide affordable scale-out for applications with a high concurrency of real-time reads/writes 3rd Party Data Sources Operational App (e.g., CRM, Supply Chain, eCommerce, Unica Campaign Mgmt) Customers Operational Employees Operational Reports & Analytics
- 5. 5 Reference Architecture: Operational Data Lake Offload real-time reporting and analytics from expensive OLTP and DW systems OLTP Systems Ad Hoc Analytics Operational Data Lake Executive Business Reports Operational Reports & Analytics ERP CRM Supply Chain HR … Data Warehouse Datamart Stream or Batch Updates ETL Real-Time, Event-Driven Apps
- 6. 6 Reference Architecture: Unified Customer Profile Improve marketing ROI with deeper customer intelligence and better cross-channel coordination Unified Customer Profile (aka DMP) Operational Reports for Campaign Performance Social Feeds Web/eCommerc e Clickstreams WebsiteDatamart Stream or Batch Updates BI Tools Demand Side Platform (DSP) Ad Exchange 1st Party/ CRM Data 3rd Party Data (e.g., Axciom) Ad Perf. Data (e.g., Doubleclick) Email Mktg Data Call Center Data POS Data Email Marketing App Ad Hoc Audience Segmentation BI Tools
- 7. 7 Proven Building Blocks: Hadoop and Derby APACHE DERBY ANSI SQL-99 RDBMS Java-based ODBC/JDBC Compliant APACHE HBASE/HDFS Auto-sharding Real-time updates Fault-tolerance Scalability to 100s of PBs Data replication
- 8. Derby 100% JAVA ANSI SQL RDBMS – CLI, JDBC, embedded Modular, Lightweight, Unicode Authentication and Authorization Concurrency Project History Started as Cloudscape in 1996 Acquired by Informix… then IBM… IBM Contributed code to Apache project in 2004 An active Apache project with conservative development DB2 influence. Many of the same limits/features Has Oracle’s stamp of approval – Java DB and included in JDK6 8
- 9. Derby Advanced Features Java Stored Procedures Triggers Two-phase commit (XA Support) Updatable SQL Views Full Transaction Isolation Support Encryption Custom Functions 9
- 10. Splice SQL Processing PreparedStatement ps = conn.prepareStatement(“SELECT * FROM T WHERE ID = ?”); 1. Look up in cache using exact text match (skip to 6 if plan found in cache) 2. Parse using JavaCC generated parser 3. Bind to dictionary, acquire types 4. Optimize Plan 5. Generate code for plan 6. Create instance of plan 10
- 11. Splice Details Parse Phase Forms explicit tree of query nodes representing statement Generate Phase Generate Java byte code (an Activation) directly into an in-memory byte array Loaded with special ClassLoader that loads from the byte array Binds arguments to proper types Optimize Phase Determine feasible join strategies Optimize based on cost estimates Execute Phase Instantiates arguments to represent specific statement state Expressions are methods on Activation Trees of ResultSets generated that represent the state of the query 11
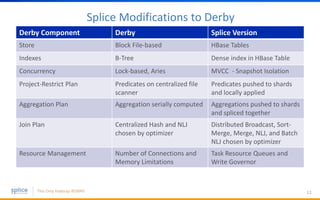
- 12. Splice Modifications to Derby 12 Derby Component Derby Splice Version Store Block File-based HBase Tables Indexes B-Tree Dense index in HBase Table Concurrency Lock-based, Aries MVCC - Snapshot Isolation Project-Restrict Plan Predicates on centralized file scanner Predicates pushed to shards and locally applied Aggregation Plan Aggregation serially computed Aggregations pushed to shards and spliced together Join Plan Centralized Hash and NLJ chosen by optimizer Distributed Broadcast, Sort- Merge, Merge, NLJ, and Batch NLJ chosen by optimizer Resource Management Number of Connections and Memory Limitations Task Resource Queues and Write Governor
- 13. 13 HBase: Proven Scale-Out Auto-sharding Scales with commodity hardware Cost-effective from GBs to PBs High availability thru failover and replication LSM-trees
- 14. 14 Distributed, Parallelized Query Execution Parallelized computation across cluster Moves computation to the data Utilizes HBase co-processors No MapReduce
- 15. Splice HBase Extensions Asynchronous Write Pipeline Non-blocking, flushable writes Writes data, indexes, and constraints (index) concurrently Batches writes in chunks for bulk WAL Edits vs. single WAL Edits Synchronization free internal scanner vs. synchronized external scanner Linux Scheduler Modeled Resource Manager Resource Queues that handle DDL, DML, Dictionary, and Maintenance Operations Sparse Data Support Efficiently store sparse data Does not store nulls 15
- 16. Schema Advantages Non-Blocking Schema Changes Add columns in a DDL transaction No read/write locks while adding columns Sparse Data Support Efficiently store sparse data Does not store nulls 16
- 17. ANSI SQL-99 Coverage 17 Data types – e.g., INTEGER, REAL, CHARACTER, DATE, BOOLEAN, BIGINT DDL – e.g., CREATE TABLE, CREATE SCHEMA, ALTER TABLE, DELETE, UPDATE Predicates – e.g., IN, BETWEEN, LIKE, EXISTS DML – e.g., INSERT, DELETE, UPDATE, SELECT Query specification – e.g., SELECT DISTINCT, GROUP BY, HAVING SET functions – e.g., UNION, ABS, MOD, ALL, CHECK Aggregation functions – e.g., AVG, MAX, COUNT String functions – e.g., SUBSTRING, concatenation, UPPER, LOWER, POSITION, TRIM, LENGTH Conditional functions – e.g., CASE, searched CASE Privileges – e.g., privileges for SELECT, DELETE, INSERT, EXECUTE Cursors – e.g., updatable, read-only, positioned DELETE/UPDATE Joins – e.g., INNER JOIN, LEFT OUTER JOIN Transactions – e.g., COMMIT, ROLLBACK, READ COMMITTED, REPEATABLE READ, READ UNCOMMITTED, Snapshot Isolation Sub-queries Triggers User-defined functions (UDFs) Views – including grouped views
- 18. 18 Lockless, ACID transactions State-of-the-Art Snapshot Isolation 18 Adds multi-row, multi-table transactions to HBase with rollback Fast, lockless, high concurrency ZooKeeper coordination Extends research from Google Percolator, Yahoo Labs, U of Waterloo Transaction A Transaction B Transaction C Ts Tc
- 19. 19 BI and SQL tool support via ODBC No application rewrites needed 19
- 20. SQL Database Ecosystem 20 Ad-hoc Analytics Operational (OLTP + OLAP) New SQL IN-MEMORY RDBMSMPP New SQL Proprietary HW Lower Cost Higher Cost Hadoop RDBMS SQL-on-Hadoop Phoenix SQL-on-HBase
- 21. What People are Saying… 21 Recognized as a key innovator in databases Scaling out on Splice Machine presented some major benefits over Oracle ...automatic balancing between clusters...avoiding the costly licensing issues. Quotes Awards An alternative to today’s RDBMSes, Splice Machine effectively combines traditional relational database technology with the scale-out capabilities of Hadoop. The unique claim of … Splice Machine is that it can run transactional applications as well as support analytics on top of Hadoop.
- 22. 22 Summary THE ONLY HADOOP RDBMS Replace your old RDBMS with a scale-out SQL database Affordable, Scale-Out ACID Transactions No Application Rewrites 10x Better Price/Perf