Kafka Connect and KSQL: Useful Tools in Migrating from a Legacy System to Kafka Streams (Alex Leung and Danica Fine, Bloomberg L.P.) Kafka Summit NYC 2019
Download as PPTX, PDF2 likes1,945 views

This document discusses using Kafka Connect and KSQL to migrate from a legacy system to Kafka Streams. It outlines four steps: 1) preparing the system, 2) integrating legacy data using Kafka Connect, 3) migrating the legacy application to Kafka Streams, and 4) validating the migration using KSQL to compare outputs and detect inconsistencies. Key challenges addressed include integrating different data partitioning schemes, comparing out-of-order or late data, and limitations of KSQL for validation. The overall goal is a methodical migration and validation approach to control risks during the transition.

























Kafka Connect and KSQL: Useful Tools in Migrating from a Legacy System to Kafka Streams (Alex Leung and Danica Fine, Bloomberg L.P.) Kafka Summit NYC 2019
- 1. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. Kafka Connect and KSQL Useful tools in migrating from a legacy system to Kafka Streams Kafka Summit New York 2019 April 2, 2019 Danica Fine, Software Engineer Alex Leung, Software Engineer
- 2. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. LEGACY APP APP KAFKA STREAM S APP KAFKA STREAM S APP KAFKA STREAMS Legacy Architecture SUB Market data (bid/ask/trade) Composite price (Bloomberg Generated Market Indicator) PUB UI CONFIG Desired Kafka Streaming Architecture
- 3. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. Migration Goals 1. Integrate existing legacy configurations 2. Run legacy and KStreams tasks to compare outputs 3. Methodical deployment and migration
- 4. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. Step 1. System Preparation APP KAFKA STREAMS LEGACY APPMarket data (bid/ask/trade)
- 5. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. Step 2. Integrate Legacy Data Systems Kafka Connect to the rescue!
- 6. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. LEGACY APP Legacy Architecture UI CONFIG Desired Kafka Streaming Architecture Kafka Connect APP KAFKA STREAM S APP KAFKA STREAM S APP KAFKA STREAMS SUB Market data (bid/ask/trade) PUB Composite price (Bloomberg Generated Market Indicator)
- 7. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. Source Connector Primer • Can poll data in variety of ways: —Bulk data load (i.e., select * from X) —Query mode —Incremental/timestamp selection • Transformations • Polling intervals
- 8. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. Configuration
- 9. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. Integrating Data into KStreams • KTable —Pro: Data only available to partition it belongs to; reduced memory. —Con: No guarantee on data availability at application startup. (https://issues.apache.org/jira/browse/KAFKA-4113) • GlobalKTable —Pro: All data available KStreams application starts at bootstrap. Designed for relatively static data —Con: Memory usage; all data is available to every partition…
- 10. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. Challenges • Task/worker work distribution —Source connectors distribute work differently —JDBC assigns one active task PER TABLE for bulk —One task per custom query • WHERE clauses conflict with incremental load • Partition and key of incoming data
- 11. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. Step 3. Migrate Legacy Application
- 12. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. KStreams Primer • Built on Kafka consumer-producer API • Topology is a DAG of processors • Build using DSL or processor API SRC TOPIC KSTREAM-SOURCE-002 KSTREAM-TRANSFORM-003 KSTREAM-FILTER-004 KSTREAM-MAPVALUES-014 KSTREAM-SINK-015 SINK TOPIC …
- 13. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. Step 4. Validation and QC Using KSQL to validate KStreams.
- 14. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. Validation/QC: Motivation and Goals • Compare output • Alarm • Visualize • No client impact
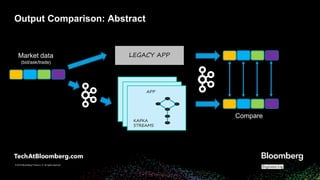
- 15. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. Compare APP KAFKA STREAMS LEGACY APPMarket data (bid/ask/trade) Output Comparison: Abstract
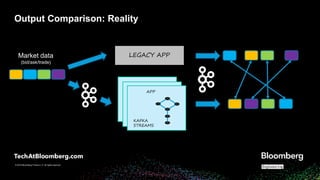
- 16. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. Output Comparison: Reality APP KAFKA STREAMS LEGACY APPMarket data (bid/ask/trade)
- 17. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. Challenges Solutions • Match output data of the two systems / Data out of order • 'WITH (TIMESTAMP=<time field>)’ + KSQL JOINs • Multiple data points per time interval • Late data • Retention • Aggregation
- 18. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. KSQL Primer • SQL-like layer on top of Kafka Streams • KSQL query Kafka Streams Topology • Scalable, fault-tolerant
- 19. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. Stream-to-Stream JOINs TOPIC-1 windowed1 merge SINK TOPIC joinThis joinOther windowed21 2 RocksDB Window State Stores sink source1 source2 TOPIC-2
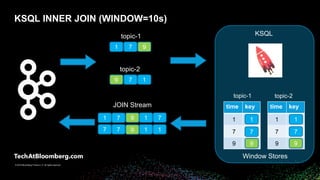
- 20. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. time keytime key KSQL INNER JOIN (WINDOW=10s) topic-1 1 7 7 1 9 JOIN Stream 1 9 7 9 7 7 1 1 7 1 topic-1 topic-2 1 7 9 1 7 9 Window Stores KSQL 9 topic-2 971 9 7 1
- 21. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. time key time key KSQL INNER JOIN (WINDOW=10s) - StreamTime 11 9 9 2d 8 7 7 1 7 99 7 1 2d2d 8 2d 2d 2d 2d 2d StreamTime: 92d JOIN Stream topic-1 topic-2 Window Stores KSQLtopic-1 topic-2
- 22. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. KSQL Comparison Market data (bid/ask/trade) APP KAFKA STREAMS LEGACY APP KSQL Compare App JOIN Aggregation & comparison
- 23. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. KSQL Comparison: Tick Data
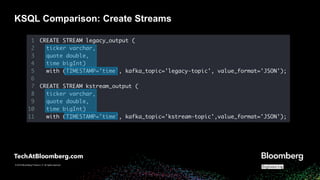
- 24. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. KSQL Comparison: Create Streams
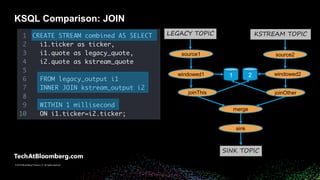
- 25. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. KSQL Comparison: JOIN LEGACY TOPIC windowed1 merge SINK TOPIC KSTREAM TOPIC joinThis joinOther windowed21 2 sink source1 source2
- 26. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. KSQL Comparison: Aggregation AGG-repartition mapValues COMPARE_1MS toStream aggregate
- 27. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. KSQL Comparison: Results
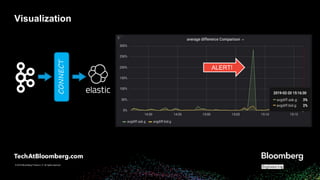
- 28. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. Visualization CONNECT ALERT!
- 29. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. KSQL Challenges & Limitations • No notion of GlobalKTable in KSQL (https://github.com/confluentinc/ksql/issues/816) • Timestamp as key inaccessible from nested Struct (https://github.com/confluentinc/ksql/issues/2188) • Window retention period not configurable —Future: grace period (https://github.com/confluentinc/ksql/issues/899) • Beware of “StreamTime”
- 30. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. What’s next… • Monitor dashboards and alarms • Enhancing replay-ability to address any inconsistencies and take action • Controlled release of KStreams application
- 31. © 2018 Bloomberg Finance L.P. All rights reserved. © 2019 Bloomberg Finance L.P. All rights reserved. Questions? Danica Fine, [email protected] Alex Leung, [email protected]
Editor's Notes
- #2: Derivatives Data Infrastructure group at Bloomberg We primarily design and build market data pipelines Which are then used by other internal derivatives team to apply big data and AI solutions to financial domain Our primary focus has been to migrate an existing legacy application to Kafka Streams. Today we’re going to break down our decision for moving to the Kafka ecosystem, how we migrated, and the tools we used to do so. Let’s dive in.
- #3: D Alright, so where do we begin? Here is a high level view of our architecture. Our legacy application is a monolithic C++ task the purpose of which is to read in a stream of key-value pair market data points that we refer to as ticks. These ticks are processed in real-time by the application which then produces a composite market indicator. In addition, we have a UI component that is used by internal analysts to configure the application in near real-time. So, this all looks well and good, but we wanted to do better. Ultimately, our decision to move to Kafka Streams was driven by several reasons: The universe of market data is ever-growing, and we wanted to prepare for a higher. This output data is relied on by thousands of our clients, and, in general, we wanted to increase the scalability and fault-tolerance of the application Enter Kafka Streams (**ACTION**) You'll note that the only thing we wanted to change was the application, itself. Leave the rest of the architecture alone, if possible.
- #4: D Before migrating anything, we sat down to discuss our goals for the migration, which we boiled down to three main focal points. (**ACTION**) Didn’t want to change the UI that the analysts are already familiar with. Along with that, no changes to the underlying database. So we made a choice to leverage Kafka Connect for importing this data and bringing it into Kafka. (**ACTION**) Another goal was to run tasks in parallel, so that we could detect differences outside of a certain epsilon and have reporting and alarming mechanisms on top of that. KSQL provided a good framework for joining and analyzing these two streams. (**ACTION**) And once the data is verified, we wanted to migrate to the new infrastructure in a strategic manner. All of this was so that we could minimize client impact during the migration process. That being said, let’s dive into the steps we actually took to migrate our application.
- #5: D When we embarked on this journey, (**ACTION**) our legacy application was grabbing data directly from an internal data source containing the market data; neither the input data nor the output composite data was in Kafka. So our first order of business was to change that. (**ACTION**) We began by changing the legacy application to route the existing output into a Kafka topic. (**ACTION**) Then we routed the input market data into a Kafka topic for later use in our KStreams application. (**ACTION**) And finally we created a Kafka topic to hold the output data from our KStreams application. As we were routing data into Kafka topics, we also added an additional timestamp field to the messages in the output topics; this extra field allowed us to create a semi-unique key for every Kafka message that we used to join the two topics during the KSQL comparison step. Note that this timestamp was already available in our input data as its event time, so it made sense for us to create a semi-unique key using this timestamp and the key from the input data.
- #6: D
- #7: D Here’s the high-level architecture again. Quick overview of the legacy database. It contains configuration and override options that the analysts use to tweak the application’s flow. There aren’t many updates on a regular basis; maybe tens per day. But these updates need to be propagated to the application in a timely manner. Our SLA was 1 minute. In the past, the legacy application directly loaded data from the configuration database, but (**ACTION**) we opted to leverage Kafka Connect to bring the data in for us. For those of you not familiar, Kafka Connect is a simple tool to bridge external data sources with Kafka. It offers both source and sink connectors to poll and push data into and out of various data sources. Some other features that we appreciated include: Scheduled polling to meet our import SLA. Single message transformation; in other words, the ability to cleanse and alter our data as we extract it. Distributed workload and automatic failover mechanisms to increase the application’s overall fault-tolerance Of course, data directly available in Kafka topic. For this specific use case, we utilized a JDBC source connector and implemented a custom transformer
- #8: D Just a quick overview of source connectors. You have the ability to configure them to poll data in a variety of ways. Incremental/timestamp mode allow you to easily emulate a sort of change data capture and avoid ingesting all of the data every time you poll. And keep in mind that these modes can be mixed and matched – you can use timestamp/incremental load on a list of tables or along with a custom query, as we did. There are a lot of transformations available out-of-the-box, including Inserting a field, elevating a value to a key, regex, etc. But you also have the ability to implement a custom transformer, as we chose to do. In a custom transformer, you have greater control over partitions, keys, etc. Polling intervals are fully configurable so you can meet your pre-defined SLAs
- #9: D What I really wanted to highlight here how simple it is to set up a connector. Just a JSON configuration file. Something to keep in mind is that some of these configuration parameters are the same across all source connectors, while some are JDBC source connector-specific. So what happens when we launch this connector? 1. Every 1 minute, (**ACTION**) defined by the polling interval, the connector will execute the (**ACTION**) custom query. Since we are using (**ACTION**) timestamp mode, the connector will also append a WHERE clause to this custom query in order to determine the rows where the timestamp column is greater than the current offset (which, in distributed mode, is stored in another Kafka topic). 2. Note that, at this point, the data is not yet in Kafka. 3. Data will then run through the (**ACTION**) transformer where we update the partition and key, as well as perform some data alignment. We update the key in this custom way because we use a specially formatted key for state store access in KStreams app. 4. Finally, the data is pushed as a message to the Kafka topic.
- #10: D Now that the data is in a Kafka topic, how do we bring it into KStreams? KStreams actually answers this question with the notion of something called a KTable. The KTable abstraction was specifically created for this sort of use-case: Where we want to enrich a stream with data from a database table where only the latest value is important. These KTables are, thus, first-class citizens. So, for our use case, it made sense to port the data into some sort of Ktable. But there are two types: Although there is no real guarantee that all of the data is available at startup, there is a best-effort attempt at timestamp synchronization. Since we had a relatively small dataset of about 50,000 rows, memory wasn’t really an issue for us. Even though the data was already partitioned in our previous transformer step, we ultimately decided to go with a GlobalKTable.
- #11: D The first hurdle was understanding the work distribution across workers and tasks. The frequency of our data make it such that we don’t need to scale, but it’s something to keep in mind for your use case. The second was WHERE clauses in our custom query. Recall from our configuration piece that timestamp and incremental mode will append a WHERE clause to filter for rows whose timestamp field is greater than a specified offset. Our query initially included its own WHERE clause filtering at the end of the query; however, having two individual sets of WHERE clauses at the end of a query will cause errors from the jdbc driver. If you plan to use WHERE clause filtering in your custom query, you will need to rework the query to move these WHERE clauses to somewhere other than the end of the query. Before the data reaches the Kafka topic, there is no partition or key defined. Once it reaches Kafka, the messages will be round-robined to partitions. If you want to join the data later, it is crucial that you set the key and partition of these messages; you have the opportunity do this in the transformer. However, recall that if you are using a GlobalKTable, as we chose to do, the partition does not matter, as all of the data will will be available across all instances of your KStreams application. In our case, setting the key was important in order for us to match the key structure of our other state stores.
- #12: D Kstreams wasn’t meant to be the focus of the talk, but, for sake of completion, we’ll briefly chat about this piece.
- #13: D Kafka Streams is built on top of the Kafka consumer-producer API. You define your streaming application by creating a topology. This topology is a DAG of processors – and data points flow through these processors one at a time. Processors can be defined using the KStreams DSL or custom transformers can be implemented. --- For our use case, we chose to leverage the processor API to define our topology. This was due to the fact that we had very complex business logic embedded in the legacy app, and we wanted greater control over our implementation. Luckily, our C++ code was implemented in such a modular way that it could easily be broken up into these transform, processor steps. We also implemented several state stores at various granularities. With our earlier decision to use the GlobalKTable, we materialize the configuration data into another sort of state store, and use the key that we defined in our custom transformer to access entries of this store. Again, note that every entry of this GlobalKTable is available on every running instance of our KStreams application.
- #14: Thanks Danica I'd like to talk about how we used KSQL to validate the functionality our new kstream application Next
- #15: Our Motivation behind this is pretty obvious Before we can consider enabling the new application, we must make sure the output is consistent with the legacy system; Also, once this consistency is achieved, we want to alarm when any inconsistencies exist we want this to happen ASAP, versus an end of the day with some batch job We’d also like to visualize the results so we can monitor the progress as we go Last and most importantly, #1 goal is not to impact existing clients throughout this process
- #16: Okay, so how can make sure the data is consistent? To revisit what Danica mentioned, Both applications share the input data then output to a separate kafka topic also, we carried forward a timestamp, from the input data, into each output message this will be used to help correlate the output of the two systems here is what it looks like in a perfect world, where all the same keys (which are colors) line up and can be easily compared However, we don’t live in a perfect world
- #17: In reality this is more like what we’re dealing with Two applications processing data independently so we'll have to deal with comparing data that is not in the same order, some is delayed etc. keys may occur > once How do we correlate the correct output and compare it?
- #18: Luckily, Kafka Streams, and better yet, KSQL can help ACTION: Matching output of the legacy and kstreams: Recall: timestamp carried forward, from the input, to output message of both outputs Once we’ve done that, (ACTION) we can extract this timestamp and use in conjunction with a S-S JOIN ACTION: What if you have multiple data points per time interval (i.e. timestamp isn’t a unique key) ACTION: Instead of comparing single data points, we can compare aggregations over a window ACTION: What if output from one topic comes in late? ACTION: There is a notion of retention, where state stores associated with JOINs keep data around for some amount of time – currently 24h Now, these are all fairly trivial things to do with KSQL I want to get into some S-S JOINs details for our comparison, but first a KSQL primer for those of you new to it
- #19: Recall (ACTION): Kafka streams is a library built on top of the producer/consumer API from vanilla Kafka Giving you topology of processors built using the DSL or low level processor API each processor takes a message from a kafka topic & does things like filter, map, aggregate before passing to next processor in the graph so there’s nothing wrong with writing a bunch of low-level consumer/producer code to do these things manually, but Kafka Streams gives you these higher level abstractions along with scalability, fault-tolerance, and processing guarantees to make life a lot easier ACTION: now KSQL makes your life even easier KSQL built on top of kafka streams With it, you can express the same filters, map, aggregations etc. using SQL-like queries and kafka streams topologies are created for you, under the covers. Get Scalability and fault-tolerance, just like Kafka streams Similarly, it's perfectly fine to write Kafka Streams applications yourself, by building the topologies, manually BUT, KSQL gives you higher level query abstractions and if it handles your use-case, you might as well use it and write less code! (After all, you only have a limited number of keystrokes in your lifetime.) And this is what we chose to compare our two applications: legacy and kstreams logo: https://docs.confluent.io/current/ksql/docs/concepts/ksql-and-kafka-streams.html
- #20: Let’s look at some Stream to Stream JOIN details which we will use to correlate our two output topics to each other, so we can compare the values The topology on the RHS is a simplified version of the topology created (automatically) when the CREATE STREAM AS SELECT with a JOIN (on left) is issued Two source topics get joined, and potentially merged into a single sink topic based on a match This is kinda like a database table join where two tables are merged into a single result based on some matching column However, unlike a typical database table JOINs, in a S-S JOIN not only the field needs to match, but needs to within a certain time window ACTION (here, 10s) to achieve this, under the covers, there are Window State Stores on which this key+timestamp lookup is performed Flow a record is received from one topic (topic-1 or topic-2) then, a lookup is performed on “opposite” windowed state store for match (key+overlapping timestamp) If there is a match, results are merged and emitted to the sink topic Finally, the key+timestamp+value is added to local store (for future events received on the other side)
- #21: let’s look at that flow with some sample data again, we'll use a window of 10s messages will flow from left to right, into two separate topics: topic-1 and topic-2 KSQL will consume these topics, invoke the JOIN logic, and emit results back to Kafka on bottom (when matches occur) input messages you’ll see… the Colors – indicate keys and the Numbers – indicate timestamps, in seconds note: ignoring values -- not important – we’re, just correlating the keys in a time window First (ACTION), blue key w/ts=1 comes in on topic-2 recall the JOIN logic: lookup in “opposite” window store emit JOIN results (if match) then add key+time+value to local window store in this case, the ”opposite" state store (topic-1’s) is empty, so no JOIN results are emitted and the local state store (topic-2’s) is simply updated next, a green key w/ts=9 shows up on topic-1 while there is one key in the opposite state store in a 10s window, it isn't green, so no join results emitted and the local state store updated now, when a blue key w/ts=7 shows up on topic-1 finally, there is a match in the opposite state store, and a JOIN result is emitted and local state store updated same, when this blue key shows up on topic-2 JOIN result emitted, store updated again for the green key on topic-2 JOIN result emitted, store updated Finally, the blue key w/ts=1 shows up on topic-1 in this case, there are two matching blue keys in the 10s window in the opposite state store both emitted and the local window store updated At this point, we have this JOIN stream (just another topic in kafka), where it contains every combination of topic-1 and topic-2 where keys match within a 10s window note again: we haven’t done anything with the values, we've just matched the correct keys in a window
- #22: Before we get into applying this to our comparison problem, I wanted to address how data is retained in the windowed state store i.e how long a join window will remain open, waiting for data to join on -- today that is 24h StreamTime is the largest timestamp encountered and what that 24h retention period is based on Let's say our window state stores are where we left and the current StreamTime is 9s -- the largest TS encountered now, if a BLUE key w/ts=2d later shows up on topic-2 ACTION First, as one might expect, no JOIN matches, since, while there are matching blue keys, none are in a 10s window the next thing that happens is that StreamTime is updated to 2d later then, the state store is checked for entries that are older than 24h from this new Stream time. In this case, everything is older than 24h from the streamTime and it is purged the only thing left will be the newest blue key now when the blue key with ts=8 shows up on topic-1, there will no longer be no JOIN output (store wiped out) similarly, since StreamTime is shared here, the topic-1’s state store is wiped out for the same reason Also, the blue key w/ts=8 is NOT added to state store (b/c 8 itself is older than 24h from streamTime) same on other side: no JOIN results and no state store change (because of the streamtime) (ACTION) only when the key w/ts=2d later data is processed does that result in JOIN result & state store updated We encountered this early on where our JOIN would emit data and suddenly stop after 12-24 hours and it turned out that our timestamps were jumping around, causing things to get cleaned up by this 24h retention period so watch out for that! Next…
- #23: to bring things together Remember, our original challenge of correlating the output topics of both of our applications? we had market data being processed by legacy and kstreams independently and outputting to Kafka and we wanted to line up the correct keys so we could compare them? well, that sounds a lot like what our S-S JOIN gives us: correlating keys in a time window So, we're going to take the two output topics, from our applications, and use them as input for the KSQL comparison app (ACTION) KSQL will first use a S-S JOIN to get every combination of the two topics where keys match within a given window (ACTION) Once the JOIN is created, we can use KSQL aggregations on the JOIN topic to do the actual comparison (ACTION)
- #24: now let’s look at the KSQL queries we can use to achieve this Slide shows some sample contents of our two topics: legacy output (top) and kstream output (bottom) each contain a ticker symbol for the key (I’m using colors again for these) that same ticker and a quote, and timestamp for the value Next
- #25: First thing is create streams corresponding to existing topics (ACTION) here I've highlighted where the schema of the topic data is specified; again, ticker, quote, time note (ACTION): the “WITH TIMESTAMP” syntax Takes the timestamp from a field in the value so our downstream JOIN will use that as the timestamp for its window the input timestamp was carried forward to both output topics specifically for this purpose of correlating the legacy and kstream output messages Note here no kafka streams topologies created yet Next…
- #26: Now let's JOIN the two streams together so matching output messages can be compared Recall, Stream to stream JOINs have to be windowed (ACTION) Note unlike the animation example, where we used a 10s JOIN window (which was for illustration purposes), since we have the same timestamps in both output topics and they will match exactly, we can use the smallest window: 1ms also note that the timestamp used for this JOIN window is the one extracted from the values of the original topics (ACTION) Under the covers here, a kafka streams topology is created automatically EXPLAIN - what topology is created for a given query Next...
- #27: - Okay, now that we’ve correlated the two streams, into a single JOIN'd stream, let's do the actual comparison of the values remember, we can have multiple messages within a single ms, so let’s do a window’d aggregation on the JOIN’d data and compare those instead of single data points if we had a globally unique id, we wouldn’t need to do an aggregation, but our timestamp is not quite unique (ACTION) Aggregations result in tables, so here, we’re creating a table (not a stream) What this does, is for every ticker, for every ms, we’ll have an average quote for both sides (ACTION) avg_quote_legacy (ACTION) kstream (ACTION) And then take the difference of the two averages as a percentage, so we can compare to some threshold and alarm note: we could have added the threshold check here (e.g. > 5%), but we've decided to keep that check in our metrics system, to get a more complete picture (ACTION) Again under the covers here, a kafka streams topology is created automatically Next...
- #28: Back to the small sample input that we started with... - (ACTION) two blue keys (in same ms) - (ACTION) one green key (ACTION) well here is the output of the JOIN which has each combination of the two keys and values within the ms window (ACTION) And the aggregation has the corresponding averages for each key in each millisecond, along with the difference of the averages, as a percentage once the JOIN and the aggregation queries are running, outputting to real Kafka topics, as new events show up on the two application output topics, the JOIN and aggregation will continue to process them and emit results to the these topics until these queries are stopped. What do we do next? Next..
- #29: let's send this data to an external system to visualize and alarm Once in Kafka, best way to get data from Kafka into an external system is to use Kafka Connect We happen to use an in-house metrics and alarming system, so we wrote our own simple connector for that, but there are plenty of open source connectors available, like elasticsearch, shown here Then, you can visualize in Grafana, set up alerting, etc. LOGO: https://www.elastic.co/brand
- #30: Now some challenges and limitations of KSQL that we think it's worth noting GlobalKTable - not available to you in KSQL only have KTable and need to JOIN a stream to it, it needs to be co-partitioned, it can’t be broadcast to every partition Second, remember extracting the timestamp from the value to be used downstream? Cannot do this if the timestamp is nested in a Struct Workaround: intermediate stream to pull timestamp to the top level, then use the "WITH TIMESTAMP" notation on a downstream query Third, the retention period that we discussed is hard-coded to 24h at the moment. already a notion of GRACE period in kafka streams but this is not yet able to be expressed in KSQL windowstore.changelog.additional.retention.ms – only configures the topic, not the store Finally, beware of StreamTime if your join stops, you could be hitting this that is it for me, I will now hand back to Danica to wrap things up
- #31: D Right now, we’re in the middle of validating the data using Alex’s KSQL. Monitor dashboards alarms Use KSQL + Connect + alarming to detect issues Enhancing replay-ability Be able to reproduce on both applications when inconsistencies arise Controlled release Our next step is to kick off a controlled release to the KStreams application. During this stage, we plan to again utilize our configuration database as well as Kafka Connect to control a feature-flag to determine which keys are switched over to KStreams. No client impact.
- #32: D/A As our title suggested, the major takeaway of this talk is that Kafka Connect and KSQL are essential tools for migrating to the KStreams ecosystem. We’ve shown how Kafka Connect can help bridge the gap between external data systems and Kafka, and we’ve also demonstrated how KSQL can offer a means for validating your migrated application and quantifying the success of this migration. (**ACTION**) FAQ: Connect ================= Q: How do you deploy your Connect? A: We have a team that provides Connect as a Service, using K8s Q: Once you chose the globalKTable, did you perform a JOIN on it? A: we materialized it into a state store to query directly. the lookup we performed was the key+another field (?) Q: How do you deal with Connect errors? A: KIP for retry-able exceptions KSQL/Kafka Streams ================= Q: what if the data doesn’t simply match, how can get to the root cause? A: replay of both applications to replay same input data future: table-to-table JOINs to compare state stores Q: how do you plan on enabling the application slowly, with no client impact A: we plan on having a per-ticker configuration option in our database (which is pulled in by Connect) a ”shared feature flag” if you will Q: If retention is 24h, will there be enough space for an entire day of data? A: rocksdb: spills to disk true, if too many unique keys, at some point, you’ll run out of memory/disk will be able to tweak in future with GRACE Q: What was the root case of the JOIN+StreamTime issue? A: started processing from "earliest" and worked through a big backlog of ticks, from weeks ago. Some tickers were hotter than others and ... we did not maintain partitioning throughout these stream queries so partition affinity changed for the keys – what you had was timestamps jumping around Q: you used a window of 1ms, why not make it bigger? What are the tradeoffs? A (JOINs): Bigger JOIN window: each lookup/fetch emits more combinations of data points, more space usage in output topic Smaller JOIN window: more correct since we’re getting closer comparing outputs according to the same input; more granular results, memory/disk usage with rocksdb is same (?) this is retention A (Aggregation): Bigger aggregation windows: more datapoints and less keys in output topic, smaller topics after compaction; can play with cache size and commit interval smaller aggregation windows: less data-points, more keys in output topic Q: Any specific parameters were set for KSQL? A: The defaults worked for our load; as we add more load, a great feature of KSQL is that you can scale out played with windowstore.changelog.additional.retention.ms but that only affected the topic Q: How do you deploy KSQL? A: using the cp-ksql-server docker images + a .sql file in headless mode for debugging, I would use interactive mode with a built the .jar Q: What load does it handle A: we currently are handling 1000s-10k/sec with two instances of KSQL (4 threads each) Q: why use inner JOIN? What about data points that have no corresponding “other” A: We also have streams that are publishing raw data to kafka, so our metrics system can compare the counts; only then will we concentrate on values TODO: new outer JOIN timing enhancements