Knowledge extraction in Web media: at the frontier of NLP, Machine Learning and Semantics
1 like293 views

Julien Plu defended his PhD thesis on knowledge extraction from web media. His research addressed three main challenges: 1) extracting entities from different types of texts and languages, 2) linking entities to multiple knowledge bases, and 3) adapting entity linking pipelines for different contexts. To extract entities, he evaluated various natural language processing techniques including phrase matching, sequence labeling using neural networks, and coreference resolution. He found that combining multiple named entity recognition models improved performance over using a single model. Plu's research provided methods for extracting and linking entities from diverse textual sources in an adaptable manner.




























































Knowledge extraction in Web media: at the frontier of NLP, Machine Learning and Semantics
- 1. Julien Plu [email protected] @julienplu Supervised by: Raphaël Troncy Co-supervised by: Giuseppe Rizzo Knowledge extraction in Web media: at the frontier of NLP, Machine Learning and Semantics
- 2. Julien Plu – PhD Thesis Defense Context 20/12/2018 2
- 3. Julien Plu – PhD Thesis Defense Motivating Scenario The Orange Amp company wants to know what their customers think about their last series of amps across the world 20/12/2018 3
- 4. Julien Plu – PhD Thesis Defense Challenge #1: Kinds of Texts 20/12/2018 4
- 5. Julien Plu – PhD Thesis Defense Challenge #2: Languages 20/12/2018 5
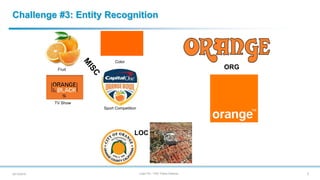
- 6. Julien Plu – PhD Thesis Defense Challenge #3: Entity Recognition 620/12/2018 ORG LOC Fruit Color TV Show Sport Competition
- 7. Julien Plu – PhD Thesis Defense Challenge #4: Entity Linking 720/12/2018 dbr:Orange_S.A. dbr:Orange_Music_Electronic_Company Additional challenges: • Personalization: • https://www.orange.fr or wikidata:Q1431486 for Orange • https://orangeamps.com or wikidata:Q769324 for Orange Amps • Temporality: Orange was called France Télécom until 2013 (http://dbpedia.org/resource/France_Télécom) wikidata:Q4830453 (Business)
- 8. Julien Plu – PhD Thesis Defense Research Questions 1. How can entities be extracted and typed, using multiple taxonomy of entity types, for various kinds of textual content? Entity Extraction and Recognition: in order to extract and recognize entities, one has to properly consider the specificities of the textual content to analyze: – Language: French, English, etc. – Kinds of texts: tweets, video subtitles, newswire, etc. – Vocabulary: DBpedia ontology, CoNLL taxonomy, etc. 2. How can different knowledge bases and their corresponding index be used to leverage the linking of the extracted entities? Knowledge Base Indexing: popular knowledge bases such as DBpedia, Wikidata, Musicbrainz or YAGO have differences: – They use a different vocabulary (DBpedia ontology for DBpedia, Music Ontology for Musicbrainz) – They are stored in different format (RDF for DBpedia, SQL for YAGO) 3. How to adapt an entity linking pipeline to different contexts? Entity Linking: a linking approach has to be adaptable to a specific knowledge base 820/12/2018
- 9. Julien Plu – PhD Thesis Defense Overview 920/12/2018 Text Input DBpedia Musicbrainz Index knowledge bases and provide entity candidates (RQ2) Generate candidates for each recognized entities and link them (RQ3) Extract and recognize entities depending of the language and the kind of text (RQ1) … Annotations Output Entity Extraction and Recognition Knowledge Base Indexing Entity Linking
- 10. Julien Plu – PhD Thesis Defense Research Question 1 Entity Extraction and Recognition Text Input DBpedia Musicbrainz Index knowledge bases and provide entity candidates (RQ2) Generate candidates for each recognized entities and link them (RQ3) Extract and recognize entities depending of the language and the kind of text (RQ1) … Annotations Output Entity Extraction and Recognition Knowledge Base Indexing Entity Linking 1020/12/2018
- 11. Julien Plu – PhD Thesis Defense Definitions: Entity and Named Entity An entity can be nominal, which means it is a common thing like human (a noun). A named entity is generally a proper noun, like Julien or Henry. Example with a named entity recognition (NER) labelling: In Boston, Michelle used to run with John Lennon. He was as slow as a snail but she was as fast as a train, probably because she worked at a running shop. Example with an entity mention detection (EMD) labelling: In Boston, Michelle used to run with John Lennon. He was as slow as a snail but she was as fast as a train, probably because she worked at a running shop. 20/12/2018 11
- 12. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition: Extractors To extract and recognize entities one can use several approaches as extractors, namely: Phrase matching (gazetteer or dictionary): – DBpedia Spotlight (Mendes et al. 2011) – Babelfy (Moro et al. 2014) Sequence labelling (NER, POS and Chunk taggers): – WAT (Piccinno et al. 2014) – AIDA (Hoffart et al. 2011) – Entityclassifier.eu (Dojchinovski et al. 2013) – FOX (Speck et al. 2014) Coreference resolution: – Pre-computed dictionary from the AIDA dataset (Ganea et al., 2017) 1220/12/2018
- 13. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition: Methods A bit of history of the NLP approaches used as extractors: Until the years 2000’s, systems were often rule based: – (Rau, 1991) that extracts only Organization entities (regex) – (Farmakiotou et al., 2000) that works only on Greek to recognize Person, Location and Organization (gazetteers + regex) From the years 2000’s, we see emerging more and more approaches that are machine learning based: – SVM (Asahara et al., 2003) – CRF – Stanford NER (Finkel et al., 2005) Since the last four years, the approaches are essentially deep learning based using unsupervised embeddings: – Bi-LSTM (Wang et al., 2015) – Bi-LSTM + CRF (Huang et al., 2015) – Unsupervised embeddings: word2vec, fastText, GloVe 1320/12/2018
- 14. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition: Datasets #1 A bit of history of the NLP datasets: First NLP datasets are from early 1990s, with the Penn Treebank for POS and dependency parsing Every year since 2000, the conference CoNLL, provides a shared task over a specific NLP task on different languages: – 2000: Chunking for English – 2002-2003: NER for Spanish and Dutch, then for English and German – 2011-2012: Coreference for English Since 2009, TAC-KBP organizes by NIST, that uses Freebase (BaseKB) as knowledge base NER on tweets with the NEEL challenges (2013-2016) and W-NUT challenges since 2016 NER on web search queries with the ERD 2014 challenge Fine grained NER in timed texts (subtitles and ASR) with ETAPE in 2012 1420/12/2018
- 15. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition: Datasets #2 These datasets are very different in terms of: Mention boundaries: "the pope" vs "pope" Taking into account nested entities or not: – "The President of the United States of America" – "President", "United States of America" – "President", "United States of America", "The President of the United States of America" We observed that all these datasets have some bias. We propose to use the following metrics that are useful when developing NER/NEL datasets: Confusability: the confusability of a mention is the number of meanings that this mention can have. Prominence: the prominence of a resource ri is the percentage of other resources that are less known than ri Dominance: the dominance of a resource ri for a given mention is a measure of how commonly ri is meant with regard to other possible meanings 20/12/2018 15 Van Erp M., Mendez P. N., Paulheim H., Ilievski F., Plu J., Rizzo G., Waitelonis J. (2016) Evaluating Entity Linking: An Analysis of Current Benchmark Datasets and a Roadmap for Doing a Better Job. In: 10th Language Resources and Evaluation Conference, Portoroz, Slovenia.
- 16. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition Sequence Labelling Sequence Labelling: assigning a category to each element of a sequence (e.g. POS, Chunking, NER) NNP VBZ DT NN IN NN WDT VBZ NNS . Chunking NP VP NP NP PP NP NP VP NP . NER Orange is a company from England that makes amps . ORG O O O O LOC O O O O POS Orange is a company from England that makes amps . Orange is a company from England that makes amps . 1620/12/2018
- 17. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition Sequence Labelling We used a number of NLP frameworks as entity extractor based on sequence labelling (Stanford CoreNLP, spaCy and OpenNLP). Each framework propose different models for various languages (Spanish, Italian, French, Chinese, English, etc.) Each model might be complementary First contribution: we improve the NER of each framework by combining multiple models altogether. For example, Stanford CoreNLP provides 3 pre- trained NER models for English that can be combined 1720/12/2018 Plu J., Rizzo G., Troncy R. (2016) Enhancing Entity Linking by Combining NER Models. In: 13th European Semantic Web Conference (ESWC'16), Open Extraction Challenge, Heraklion, Crete, Greece.
- 18. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition NER Combination Apply multiple models over the same piece of text Merge the results into one single output 1820/12/2018
- 19. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition NER Combination NER Combiner example over a tweet with Stanford CoreNLP Head over to @Orangeamps @Instagram now to see Mike run his gear NER results with a single model trained on the NEEL2016 training set NER results by combining the model trained on the NEEL2016 training set and another trained on CoNLL2003 O O O ORG ORG O O O O O O O Head over to @Orangeamps @Instagram now to see Mike run his gear O O O ORG ORG O O O PER O O O 1920/12/2018
- 20. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition NER Combination NER Combination over CoNLL2002 and 2003 with Stanford CoreNLP (F1): English: CoNLL2003, MUC7 German: CoNLL2003, Europeana Newspapers Dutch: CoNLL2002, Europeana Newspapers Spanish: CoNLL2002, Wikiner Method English German Dutch Spanish Single model 86.31 70.59 78.15 77.09 Model combination 87.94 71.90 79.71 81.14 2020/12/2018
- 21. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition NER Combination Tweets are very different than newswire text for NLP processing NER Combination with Stanford CoreNLP on the NEEL2016 dataset: Very low results: a large part of the entities are hashtags or user mentions Need a specific pre-processing for parsing tweets Need to have an easier way to train the models and handling these hashtags and user mentions Need to have an agnostic approach (language and kind of text) 20/12/2018 21 Method English (F1) Single model 6.2 Model combination 11.67
- 22. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition DeepNER Second contribution: Deep Learning based approach A single approach for the three sequence labelling task (POS, NER and Chunking) Easy to train (two columns CoNLL format) Language and kind of text adaptive without a tough manual tuning step 2220/12/2018
- 23. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition DeepNER Lample et al. 2016 2320/12/2018
- 24. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition DeepNER Ma et al. 2016 2420/12/2018
- 25. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition DeepNER Ma et al. 2016 was better suited to be adapted: Much faster to train Easier to re-implement Easier to customize the network Our improvements over Ma et al. 2016: Better approach to compute the characters embeddings: – the characters embeddings are computed by doing the average of each word embedding in which they appear Add several other word features (isUserMention, isDate, isHashtag, isURL) in order to be able to process tweets Add another Bi-LSTM network before the CRF layer to improve the way the context is handled (Lample et al. 2016) 2520/12/2018
- 26. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition DeepNER Sequence labelling over NEEL2016 (NER) (F1) Sequence labelling over CoNLL2002 and 2003 (NER) (F1) Method English German Dutch Spanish Ma et al. 2016 91.21 Lample et al. 2016 90.94 78.76 81.74 85.75 Tran et al. 2017 91.66 86.24 Single model 86.31 70.59 78.15 77.09 Model combination 87.94 71.90 79.71 81.14 DeepNER 92.18 82.44 86.54 88.77 Method English Single model 6.2 Model combination 11.67 DeepNER 66.63 2620/12/2018
- 27. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition DeepNER Sequence labelling over CoNLL2009 (POS) (ACC) Sequence labelling over CoNLL2000 (chunking) method English German Catalan Spanish Chinese Czech Google Syntaxnet 97.65 97.52 99.03 98.97 94.72 99.02 Deep-sequence-tagger 98.09 98.04 99.15 99.12 88.47 99.13 Method Accuracy Zhai et al. 2017 94.7 Deep-sequence-tagger 96.4 2720/12/2018
- 28. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition Coreference Coreference resolution is the task of finding all noun phrases that refers to the same entity 20/12/2018 28
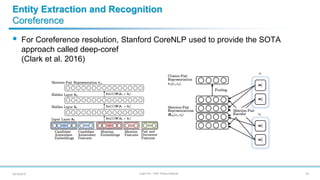
- 29. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition Coreference For Coreference resolution, Stanford CoreNLP used to provide the SOTA approach called deep-coref (Clark et al. 2016) 2920/12/2018
- 30. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition Coreference Deep-coref does not take into account the semantics of the mentions, while this can improve the accuracy of a coreference approach (Prokofyev et al. 2015) We did improve the mention-pair ranking network by adding the notion of semantic in the mention features and its ranking function 3020/12/2018
- 31. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition Coreference Coreference resolution over CoNLL2012 method MUC B3 CEAF-E AVG F1 P R F1 P R F1 P R F1 Deep- coref 63.4 72.9 68.3 57.5 60.9 59.1 52.1 58.2 55 60.8 Sanapho r++ 65.8 74.7 70 58.8 62.4 60.6 52.5 58.6 55.4 62 3120/12/2018 Plu J., Prokofyev R., Tonon A., Cudré-Mauroux P., Difallah D. E., Troncy R., Rizzo G. (2018) Sanaphor++: A Combination of Deep Neural Networks and Semantics for Coreference Resolution. In 11th edition of the Language Resources and Evaluation Conference (LREC), Miyazaki, Japan
- 32. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition Overlap Resolution Detect overlaps among boundaries of entities coming from the extractors Different heuristics can be applied: Merge: (“United States” and “States of America” => “United States of America”) default behaviour Simple Substring: (“Florence” and “Florence May Harding” => ”Florence” and “May Harding”) Smart Substring: (”Giants of New York” and “New York” => “Giants” and “New York”) 3220/12/2018 Plu J., Rizzo G., Troncy R. (2015) Revealing Entities from Textual Documents Using a Hybrid Approach. In (ISWC'15) 3rd International Workshop on NLP & DBpedia, Bethlehem, Pennsylvania, USA.
- 33. Julien Plu – PhD Thesis Defense Entity Extraction and Recognition Summary We proposed a way to combine multiple extractors for the task of entity extraction and recognition over multiple languages and kinds of texts. DeepNER outperforms current state-of-the-art (end 2017) on multiple languages for POS and NER tagging and for Chunking on English. 2018: we see a new wave of approaches (FLAIRS, ELMo, BERT) that pushes further the SoA Our coreference resolution approach outperforms current state-of-the-art (end 2017) for English. 3320/12/2018
- 34. Julien Plu – PhD Thesis Defense Research Question 2 Knowledge Base Indexing Text Input DBpedia Musicbrainz Index knowledge bases and provide entity candidates (RQ2) Generate candidates for each recognized entities and link them (RQ3) Extract and recognize entities depending of the language and the kind of text (RQ1) … Annotations Output Entity Identification and Recognition Knowledge Base Indexing Entity Linking 3420/12/2018
- 35. Julien Plu – PhD Thesis Defense Knowledge Base Indexing Large choice 3520/12/2018
- 36. Julien Plu – PhD Thesis Defense Knowledge Base Indexing Challenges Knowledge bases can be indexed for: Computing entity summaries Computing entity embeddings Real use case: Wikimedia is investigating how to index Wikidata into Elasticsearch while reducing as much as possible what to index https://lists.wikimedia.org/pipermail/wikidata/2018-July/012252.html 3620/12/2018
- 37. Julien Plu – PhD Thesis Defense Knowledge Base Indexing Challenges Each knowledge base has: its own schema its own format its own content This is a problem when we want to use such or such knowledge base for disambiguating entities without changing the way we get the candidates 3720/12/2018
- 38. Julien Plu – PhD Thesis Defense Knowledge Base Indexing Select properties Example with DBpedia (2016-04 snapshot): 4.726.950 entities 281datatype properties Approach: 1. Load DBpedia in a full text search engine such as Elasticsearch 2. Generate a list of tuples (mention, link) from known linking datasets (AIDA, NEEL and OKE) 3. Query ES with the mention of each tuple with each of the 281 properties. If, among the results, the link associated to the mention appears, the property is kept 3820/12/2018
- 39. Julien Plu – PhD Thesis Defense Knowledge Base Indexing Select properties (Abrams, dbo:J._J._Abrams) . . . . dbo:abstract dbo:longName rdfs:label dbo:slogan dbo:birthName foaf:name 3920/12/2018
- 40. Julien Plu – PhD Thesis Defense Knowledge Base Indexing Select properties The list of 72 properties is still big, so we need to reduce again this number. For that, we optimize the process with the following algorithm This optimization allowed to keep only four properties: • dbo:wikiPageRedirects • dbo:wikiPageWikilinksText • dbo:demonym • rdfs:label 4020/12/2018
- 41. Julien Plu – PhD Thesis Defense Knowledge Base Indexing Evaluation Recall without the optimization by querying only the rdfs:label property: Recall with the optimization: OKE2015 OKE2016 OKE2017 T1 OKE2017 T2 OKE2017 T3 Recall 77.21 75.03 84.35 81.77 98.39 NEEL2014 NEEL2015 NEEL2016 AIDA Recall 67.96 67.12 63.82 91.13 OKE2015 OKE2016 OKE2017 T1 OKE2017 T2 OKE2017 T3 Recall 98.38 97.34 99.12 96.45 100 NEEL2014 NEEL2015 NEEL2016 AIDA Recall 93.35 93 93.55 99.62 4120/12/2018
- 42. Julien Plu – PhD Thesis Defense Knowledge Base Indexing Summary We succeed to handle more than one knowledge bases We have found an algorithm to optimize the cover of a knowledge base We succeed to find what are the best properties to search over a knowledge base 4220/12/2018
- 43. Julien Plu – PhD Thesis Defense Research Question 3 Entity Linking Text Input DBpedia Musicbrainz Index knowledge bases and provide entity candidates (RQ2) Generate candidates for each recognized entities and link them (RQ3) Extract and recognize entities depending of the language and the kind of text (RQ1) … Annotations Output Entity Identification and Recognition Knowledge Base Indexing Entity Linking 4320/12/2018
- 44. Julien Plu – PhD Thesis Defense Entity Linking History A bit of history of the entity linking approaches: Independent approach: they are the most context independent approaches, often based on string similarity and entity popularity (e.g. PageRank) – (Gottipati et al., 2011) – (Pilz et al., 2011) Collaborative approach: they are the most popular approaches until two years ago, often based on representing a collective context across all the recognized entities – (Cucerzan, 2007) – (Hoffart et al., 2011) Deep learning approach: the most popular approaches since two years, often based on entity embeddings and relations: – (Yamada et al., 2016) – (Fang et al., 2016) 4420/12/2018
- 45. Julien Plu – PhD Thesis Defense Entity Linking Candidate Generation and NIL clustering First we generate candidate links for all extracted mentions If the mention has no candidates, it will be linked to NIL NIL entities have to be clustered: Henry and Peter Stone lived all their childhood together but now, Peter moved to another country. The clustering is done with a string comparison over each NIL mention and grouped when being similar. 20/12/2018 45
- 46. Julien Plu – PhD Thesis Defense Entity Linking Independent Approach 𝑟𝑟 𝑙𝑙 = 𝑎𝑎. 𝐿𝐿 𝑚𝑚, 𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡 + 𝑏𝑏. max 𝐿𝐿 𝑚𝑚, 𝑅𝑅 + 𝑐𝑐. max 𝐿𝐿 𝑚𝑚, 𝐷𝐷 . 𝑃𝑃𝑃𝑃(𝑙𝑙) r(l): the score of the candidate l L: the Levenshtein distance m: the extracted mention title: the title of the candidate l R: the set of redirect pages associated to the candidate l D: the set of disambiguation pages associated to the candidate l PR: Pagerank associated to the candidate l a, b and c are weights following the properties: a > b > c and a + b + c = 1 4620/12/2018 We take each extracted mention and we apply the following independent formula:
- 47. Julien Plu – PhD Thesis Defense Entity Linking Independent Approach Evaluation over several benchmark datasets (F1): (1): PBOH (Ganea O-E et al. 2016) (2): FOX (Speck et al. 2014) (3): DBpedia Spotlight (Mendes et al. 2011) Take away: need to better take into account the context surrounding the mention Datasets OKE 2015 OKE 2016 OKE 2017 T1 OKE 2017 T2 OKE 2017 T3 NEEL 2014 NEEL 2015 NEEL 2016 AIDA Independent formula 38.02 30.86 33.42 43.72 99.98 36.92 26.81 39.12 53.3 Best in Gerbil 64.12 (1) 67.59 (1) 69.32 (1) 68.18 (1) 14.55 (2) 72.74 (1) 39.01 (3) 35.17 (3) 88.12 (1) 4720/12/2018
- 48. Julien Plu – PhD Thesis Defense Entity Linking JeuxDeLiens RezoJDM: French lexico-semantic network http://www.jeuxdemots.org/jdm-about.php ~1M of entities and ~230M of relations vertices: words, concepts, expressions Relations: lexical (lemma, POS…) semantics (hyperonymy, agent, cause…) ~100 types of relations 4820/12/2018
- 49. Julien Plu – PhD Thesis Defense Entity Linking JeuxDeLiens The first step of the disambiguation is to compute the score of a path with the following formula: With: 4920/12/2018
- 50. Julien Plu – PhD Thesis Defense Entity Linking JeuxDeLiens The second step uses the previous formula to express the similarity between two vertices: With: 5020/12/2018
- 51. Julien Plu – PhD Thesis Defense Entity Linking JeuxDeLiens Statistics of the dataset created from LeMonde articles: Evaluation on this dataset: Approach F1 Independent formula 45.9 JeuxDeLiens 77.2 5120/12/2018 Plu J., Cousot K., Lafourcade M., Troncy R., Rizzo G. (2018) JeuxDeLiens: Word Embeddings and Path-Based Similarity for Entity Linking using the French JeuxDeMots Lexical Semantic Network. In: 25ème conférence sur le Traitement Automatique des Langues Naturelles (TALN) Number of articles 15 Number of entities of type PERSON 228 Number of entities of type LOCATION 117 Number of entities of type ORGANIZATION 226
- 52. Julien Plu – PhD Thesis Defense Entity Linking JeuxDeLiens Advantages: Works much better than the independent formula on RezoJDM Able to detect NIL entities with a threshold Disadvantages: Works only with RezoJDM Long to run (around a minute per entity disambiguated) 5220/12/2018
- 53. Julien Plu – PhD Thesis Defense Entity Linking DeepLink We need an approach that can be adapted to a much larger set of knowledge bases as our independent formula One possible solution is to investigate a deep learning based approach One state-of-the-art approach that might answers our needs is DSRM (Huang et al. 2015) 5320/12/2018
- 54. Julien Plu – PhD Thesis Defense Entity Linking DeepLink We further improved the DSRM approach with the following changes: use of fastText embeddings instead of tri-letter based word hashing for representing connected entities surface forms and description use a different architecture than the fully connected layers (Shan et al. 2016): 5420/12/2018
- 55. Julien Plu – PhD Thesis Defense20/12/2018 55 We did evaluate our deep learning approach over the (Ceccarelli et al., 2013) dataset for a learning-to-rank task: We did evaluate our deep learning approach over the AIDA dataset following the same linking approach than (Ceccarelli et al., 2013) with the nDCG score: nDCG@1 nDCG@5 nDCG@10 DSRM 0.81 0.73 0.74 DeepLink 0.83 0.80 0.79 Entity Linking DeepLink AIDA Independent formula 53.3 Best in Gerbil (Ganea O-E et al. 2016) 88.12 DeepLink 91.87 (Ganea O-E et al. 2017) 92.08
- 56. Julien Plu – PhD Thesis Defense Entity Linking DeepLink Advantages: Works better than other SOTA (mid of 2017) approaches Handle any knowledge bases Do not take into account the language Achieve current SOTA performance on entity similarity measure Disadvantages: Do not handle NIL entities Very long to train (around two weeks on 4 GPUs) Very long to run (around 5 days for AIDA) Current deep learning approaches work better because they use relations between entities (Ganea et al., 2017) 5620/12/2018
- 57. Julien Plu – PhD Thesis Defense Conclusion RQ1: How can entities be extracted and typed, using multiple taxonomy of entity types, for various kind of textual content? Contributions: – NER Combination … published at ESWC 2016 and in SWJ 2019 – DeepNER – Sanaphor++ … published at LREC 2018 RQ2: How can different knowledge bases and their corresponding index be used to leverage the linking of the extracted entities? Contributions: – Agnostic KB indexing and optimization … published at ESWC 2017, IC 2017 and in SWJ 2019 RQ3: How to adapt an entity linking pipeline to different contexts? Contributions: – Independent formula … published at ESWC 2015 and in SWJ 2019 – JeuxDeLiens … published at TALN 2018 – DeepLink 5720/12/2018
- 58. Julien Plu – PhD Thesis Defense Future Work Short term: Integrate DeepLink in our pipeline Finish to evaluate DeepLink over multiple benchmark datasets Enhance our codebase with better frameworks and architecture: – Spring (http://spring.io/) and IBM UIMA architectural approach (Ferrucci and Lally, 2004) – Clean Architecture (Martin, 2017) and Domain Driven Design (Evans, 2003) Middle term: Increase the number of datasets against which to evaluate our pipeline (AQUAINT, MSNBC, ACE 2004, clueweb, WNED-WIKI) Combine entity linking approaches as we combine NER extractors (Ferrucci and Lally, 2004). David Ferrucci and Adam Lally. UIMA: an architectural approach to unstructured information processing in the corporate research environment. Journal Natural Language Engineering, 2004 (Martin, 2017). Robert C. Martin. Clean Architecture: A Craftsman's Guide to Software Structure and Design. Prentice Hall, 2017 (Evans, 2003). Eric Evans. Domain Driven Design: Tackling Complexity in the Heart of Software. Addison-Wesley, 2003. 20/12/2018 58
- 59. Julien Plu – PhD Thesis Defense Future Work Long term: entity linking can be used for doing instance matching by generating candidates not from a single KB but from multiple ones and use this result to state that the final links found from different KBs can be related with an owl:sameAs relationship entity recognition and linking should be complemented with relation extraction: – relation extraction can be improved when using entity recognition an linking results (Feng et al. 2017) entity linking could take into account the temporality of the entities – A same entity can have more than one meaning depending on the date the text has been written (ex: President Bush can be either the father or the son) entity linking could be personalized – An entity can have multiple links, for example, the newspaper LeMonde can have (among many others): https://www.lemonde.fr/, https://fr.wikipedia.org/wiki/Le_Monde, https://en.wikipedia.org/wiki/Le_Monde, http://dbpedia.org/resource/Le_Monde improve intent classification for conversational agents: – intent classification can be improved with a NER process (Bocklisch et al. 2017) but also if we add an entity linking process. This is used in Google Home, but sometime the ambiguity is too difficult and the agent as to take a default answer. We can imagine to have a better personalized agent helped with a personalized entity linking process. 20/12/2018 59
- 60. Julien Plu – PhD Thesis Defense Thank You 20/12/2018 60
- 61. Julien Plu – PhD Thesis Defense Publications #1 1. Plu J., Rizzo G., Troncy R. (2019) ADEL: ADaptable Entity Linking. In: Semantic Web Journal (SWJ), Special Issue on Linked Data for Information Extraction 2. Plu J., Cousot K., Lafourcade M., Troncy R., Rizzo G. (2018) JeuxDeLiens: Word Embeddings and Path- Based Similarity for Entity Linking using the French JeuxDeMots Lexical Semantic Network. In: 25ème conférence sur le Traitement Automatique des Langues Naturelles (TALN) 3. Plu J., Prokofyev R., Tonon A., Cudré-Mauroux P., Difallah D. E., Troncy R., Rizzo G. (2018) Sanaphor++: A Combination of Deep Neural Networks and Semantics for Coreference Resolution. In 11th edition of the Language Resources and Evaluation Conference (LREC) 4. Troncy R., Rizzo G., Jameson A., Corcho O., Plu J., Palumbo E., Ballesteros Hermida J.C., Spirescu A., Kuhn K., Barbu C., Rossi M., Celino I., Agarwal R., Scanu C., Valla M., Haaker T. (2017) 3cixty: Building Comprehensive Knowledge Bases For City Exploration. In: Journal of Web Semantics (JWS) 5. Plu J., Troncy R., Rizzo G. (2017) ADEL : une méthode adaptative de désambiguïsation d'entités nommées. In: 28ème journées francophones d'Ingénierie des Connaissances (IC'17) 6. Plu J., Troncy R., Rizzo G. (2017) ADEL@OKE 2017: A Generic Method for Indexing Knowledge Bases for Entity Linking. In: 14th European Semantic Web Conference (ESWC'17), Open Extraction Challenge, Portoroz, Slovenia. 7. Plu J., Rizzo G., Troncy R. (2016) Enhancing Entity Linking by Combining NER Models. In: 13th European Semantic Web Conference (ESWC'16), Open Extraction Challenge, Heraklion, Crete, Greece. 8. Ilievski F., Rizzo G., Van Erp M., Plu J., Troncy R. (2016) Context-enhanced Adaptive Entity Linking. In: 10th Language Resources and Evaluation Conference, Portoroz, Slovenia. 20/12/2018 61
- 62. Julien Plu – PhD Thesis Defense Publications #2 9. Van Erp M., Mendez P. N., Paulheim H., Ilievski F., Plu J., Rizzo G., Waitelonis J. (2016) Evaluating Entity Linking: An Analysis of Current Benchmark Datasets and a Roadmap for Doing a Better Job. In: 10th Language Resources and Evaluation Conference, Portoroz, Slovenia. 10.Rizzo G., van Erp, Plu J., Troncy R. (2016) NEEL 2016: Named Entity rEcognition & Linking Challenge Report. In: 25th International World Wide Web Conference (WWW'16), 6th International Workshop on Making Sense of Microposts (#Microposts'16) Montréal, Canada. 11.Plu J. (2016) Knowledge Extraction in Web Media: At The Frontier of NLP, Machine Learning and Semantics. In: 25th International World Wide Web Conference (WWW'16) PhD Symposium, Montréal, Canada. 12.Rizzo G., Troncy R., Corcho O., Jameson A., Plu J., Ballesteros Hermida J.C., Assaf A., Barbu C., Spirescu A., Kuhn K., Celino I., Agarwal R., Nguyen C.K., Pathak A., Scanu C., Valla M., Haaker T., Verga E.S., Rossi M., Redondo Garcia J.L. (2015) 3cixty@Expo Milano 2015: Enabling Visitors to Explore a Smart City. In: 14th International Semantic Web Conference (ISWC'15) Semantic Web Challenge, Bethlehem, Pennsylvania, USA. 13.Plu J., Rizzo G., Troncy R. (2015) An Experimental Study of a Hybrid Entity Recognition and Linking System. In: 14th International Semantic Web Conference (ISWC'15) Poster Demo Session (see also the poster), Bethlehem, Pennsylvania, USA. 14.Plu J., Rizzo G., Troncy R. (2015) Revealing Entities from Textual Documents Using a Hybrid Approach. In (ISWC'15) 3rd International Workshop on NLP & DBpedia, Bethlehem, Pennsylvania, USA. 15.Rizzo G., Corcho O., Troncy R., Plu J., Ballesteros Hermida, J. C., Assaf A. (2015) The 3cixty Knowledge Base for Expo Milano 2015: Enabling Visitors to Explore the City. In: 8th International Conference on Knowledge Capture (K-CAP'15) (see also the poster), Palisades, NY, USA. 16.Plu J., Rizzo G., Troncy R. (2015) A Hybrid Approach for Entity Recognition and Linking. In: 12th European Semantic Web Conference (ESWC'15), Open Extraction Challenge, Portoroz, Slovenia. 20/12/2018 62