Large-Scale Text Processing Pipeline with Spark ML and GraphFrames: Spark Summit East talk by Alexey Svyatkovskiy
12 likes4,013 views

The document outlines a large-scale text processing pipeline utilizing Apache Spark and GraphFrames to address policy diffusion detection in U.S. legislatures. It details the methodologies applied for text processing, feature extraction, and all-pairs similarity calculations among legislative bills using techniques like clustering and locality sensitive hashing. The research aims to provide a scalable framework for analyzing similarities in bill texts and understanding the influences of policy diffusion across states.












![Similarity measures
• The Jaccard similarity between two sets is the size of their intersection divided by the size
of their union:
J(𝐴, 𝐵) =
|-∩/|
|-∪/|
=
|-∩/|
- 1 / 2|-∩/|
– Key distance: consider feature vectors as sets of indices
– Hash distance: consider dense vector representations
• Cosine distance between feature vectors
C(A,B)=
(-6/)
|-|6|/|
– Convert distances to similarities assuming inverse proportionality,
rescaling it to [0,100] range, adding a regularization term
Feature type Similarity measure
Workflow1: K-means
clustering
Unigram, TF-IDF, truncated
SVD
Cosine, Euclidean
Workflow2: LSH N-gram with N=5, MinHash Jaccard
𝐴
𝐵](https://image.slidesharecdn.com/3312alexeysvyatkovskiy-170215225218/85/Large-Scale-Text-Processing-Pipeline-with-Spark-ML-and-GraphFrames-Spark-Summit-East-talk-by-Alexey-Svyatkovskiy-14-320.jpg)













Large-Scale Text Processing Pipeline with Spark ML and GraphFrames: Spark Summit East talk by Alexey Svyatkovskiy
- 1. Large scale text processing pipeline with Spark ML and GraphFrames Alexey Svyatkovskiy, Kosuke Imai, Jim Pivarski Princeton University
- 2. Outline • Policy diffusion detection in U.S. legislature: the problem • Solving the problem at scale • Apache Spark • Text processing pipeline: core modules • Text processing workflow • Data ingestion • Pre-processing and feature extraction • All-pairs similarity calculation • Reformulating problem as a network graph problem • Interactive analysis • All-pairs similarity join • Candidate selection: clustering, hashing • Policy diffusion detection modes • Interactive analysis with Histogrammar tool • Conclusion and next steps
- 3. Policy diffusion detection: the problem • Policy diffusion detection is a problem from a wider class of fundamental text mining problems of finding similar items • Occurs when government decisions in a given jurisdiction are systematically influenced by prior policy choices made in other jurisdictions, in a different state on a different year • Example: “Stand your ground” bills first introduced in Florida, Michigan and South Carolina 2005 – A number of states have passed a form of SYG bills in 2012 after T. Martin’s death • We focus on a type of policy diffusion that can be detected by examining similarity of bill texts States that have passed SYG laws States that have passed SYG laws since T. Martin’s death States that have proposed SYG laws after T. Martin’s death Source: LCAV.org
- 4. Anatomy of Spark applications • Spark uses master/worker architecture with central coordinators (drivers) and many distributed workers (executors) • We choose Scala for our implementation (both driver and executors) because unlike Python and R it is statically typed, and the cost of JVM communication is minimal Cluster manager Driver program Worker node/container Worker node/container SparkContext Executor Cache Task Task Executor Cache Task Task • A 10 node SGI Linux Hadoop cluster • Intel Xeon CPU E5-2680 v2 @ 2.80GHz CPU processors, 256 GB RAM • All the servers mounted on one rack and interconnected using a 10 Gigabit Ethernet switch • Cloudera distribution of Hadoop configured in high- availability mode using two namenodes • Schedule Spark applications using YARN • Distributed file system (HDFS) • Alternative configuration uses SLURM resource manager deploying Spark in a standalone mode Hardware specifications
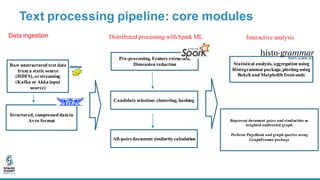
- 5. Text processing pipeline: core modules All-pairs document similaritycalculation Represent document pairs and similarities as weighted undirected graph. Perform PageRank and graph queries using GraphFrames package Raw unstructured text data from a static source (HDFS), orstreaming (Kafka or Akkainput source) Structured, compressed datain Avro format Pre-processing, Feature extraction, Dimension reduction Candidate selection:clustering, hashing Data ingestion Distributed processing withSpark ML Statistical analysis, aggregation using Histogrammarpackage,plottingusing Bokeh and Matplotlib front-ends Interactive analysis
- 6. Data ingestion • Our dataset is based on the LexisNexis StateNet dataset which contains a total of more than 7 million legislative bills from 50 US states from 1991 to 2016 • The initial dataset contains unstructured text documents sub-divided by year and state • We use Apache Avro serialization framework to store the data and access it efficiently in Spark applications – Binary JSON meta-format with schema stored with the data – Row-oriented, good for nested schemas. Supports schema evolution Unique identifier of the bill Used to construct predicates and filter the data before calculating joins Entire contents of the bill as a string, not read into memory during candidate selection and filtering steps, thanks to the Avro schema evolution property Example raw bill
- 7. Analysis workflow1 Extract candidate documents: those feature vectors that we need to test for similarity Prepare multisets of tokens. N consecutive words, optionally add bag-of-word features. Feature vectors are so high dimension,or so many that they cannot all fit in memory. SVD performs semantic decomposition of TF-IDF matrix and extracts concepts which are most relevant for clustering Cleaning, normalization, stopword removal Tokenization, n-gram TF-IDF K-means clustering All-pairs similarity in each cluster Truncated SVD Feature weighting to reflect importance of a term t to a document d in corpus D Words appearing very frequently across the corpus bare little meaning Raw text of legislative proposals contains spurious white spaces and non- alphanumeric characters, which bare no meaning for analysis and often represent an obstacle for tokenization Dataframe API RDD-based (linear algebra, BLAS) RDD-based
- 8. Analysis workflow2 Extract candidate documents: a pair of documents that hashes into the same bucket for a fraction of bands makes a candidate pair Prepare sets of tokens or shingles. N consecutive words /or characters N-gram/N- shingle Min hashing Locality sensitive hashing All-pairs similarity in each cluster Extract minhash signatures: integer vectors that represent the sets, and reflect their similarity Dataframe API (optional) Cleaning, normalization, stopword removal
- 9. Spark ML: a quick review • Spark ML provides standardized API for machine learning algorithms to make it easier to combine multiple algorithms into a single pipeline or workflow – Similarly to scikit-learn Python library Basic components of a Pipeline are: • Transformer: an abstract class to apply a transformation to dataset/dataframes – UnaryTransformer abstract class: takes an input column, applies transformation, and output the result as a new column – Has a transform() method • Estimator: implements an algorithm which can be fit on a dataframe to produce a Transformer. For instance: a learning algorithm is an Estimator which is trained on a dataframe to produce a model. – Has a fit() method • Parameter: an API to pass parameters to Transformers and Estimators
- 10. Putting it all into Pipeline • Preprocessing and feature extraction steps – Use StopWordsRemover, RegexTokenizer, MinHashLSH, HashingTF transformers – IDF estimator • Prepare custom transformers to plug into Pipeline – Ex: extend UnaryTransformer, override createTransformerFunc using custom UDF • Clustering KMeans and LSH • Ability to perform hyper-parameter search and cross-validation Example ML pipeline (see backup for a full snippet) Example custom transformer
- 11. All-pairs similarity: overview • Our goal is to go beyond identifying the diffusion topics: “stand your ground bills”, cyberstalking, marijuana laws. But also to perform an all-pairs comparison • Previous work in policy diffusion has been unable to make an all-pairs comparison between bills for a lengthy time period because of computational intensity – Brute-force all-pairs calculation between the texts of the state bills requires calculating a cross-join, yielding O(10#$) distinct pairs on the dataset considered – As a substitute, scholars studied single topic areas • Focusing on the document vectors which are likely to be highly similar is essential for all-pairs comparison at scale • Modern studies employ variations of nearest-neighbor search, locality sensitive hashing (LSH), as well as sampling techniques to select a subset of rows of TF-IDF matrix based on the sparsity (DIMSUM) • Our approach utilizes clustering and hashing methods (details on the next slide)
- 12. All-pairs similarity, workflow1: clustering • First approach utilizes K-means clustering to identify groups of candidate documents which are likely to belong to the same diffusion topic, reducing the number of comparisons in the all-pairs similarity join calculation – Distance-based clustering using fast square distance calculation in Spark ML – Introduce a dataframe column with a cluster label. Perform all-pairs calculation within each cluster – Determine the optimum number of clusters empirically, by repeating the calculation for a range of values of k, scoring on a processing time versus WCSSE plane – 150 clusters for a 3 state subset, 400 clusters for the entire dataset – 2-3 orders of magnitude less combinatorial pairs to calculate compared to the brute-force approach Brute force solution is too slow…
- 13. All-pairs similarity, workflow2: LSH • N-shingle features with relatively large N > 5, hashed, converted to sets • Characteristic matrix instead of TF-IDF matrix (values 0 or 1) • Extract MinHash signatures for each column (document) using a family of hash functions h1(x), h2(x), h3(x), … hn(x) – Hash several times – The similarity of two signatures is the fraction of the hash functions in which they agree • LSH: focus on pairs of signatures which are likely to be from similar documents – Hash columns of signature matrix M to many buckets – Partition signature matrix into bands of rows. For each band, hash each column into k buckets – A pair of documents that hashes into the same bucket for a fraction of bands makes a candidate pair • Use MinHashLSH class in Spark 2.1 Characteristic matrix: N-shingles rows M-documents columns Signature matrix: K-number of hash functions rows M-documents columns Ex: Family of 4 hash functions
- 14. Similarity measures • The Jaccard similarity between two sets is the size of their intersection divided by the size of their union: J(𝐴, 𝐵) = |-∩/| |-∪/| = |-∩/| - 1 / 2|-∩/| – Key distance: consider feature vectors as sets of indices – Hash distance: consider dense vector representations • Cosine distance between feature vectors C(A,B)= (-6/) |-|6|/| – Convert distances to similarities assuming inverse proportionality, rescaling it to [0,100] range, adding a regularization term Feature type Similarity measure Workflow1: K-means clustering Unigram, TF-IDF, truncated SVD Cosine, Euclidean Workflow2: LSH N-gram with N=5, MinHash Jaccard 𝐴 𝐵
- 15. Interactive analysis with Histogrammar tool • Histogrammar is a suite of composable aggregators with – Language independent specification with implementations in Scala and Python – Grammar of composable aggregation routines – Draws plots in Matplotlib and Bokeh – Unlike RDD.histogram, Histogrammar let’s one build 2D, profiles, sum-of-squares statistics in an open-ended way http://histogrammar.org Contact Jim Pivarski or me to contribute! Example interactive session with Histogrammar
- 16. GraphFrames • GraphFrames is an extension of Spark allowing to perform graph queries and graph algorithms on Spark dataframes – A GraphFrame is constructed using two dataframes (a dataframe of nodes and an edge dataframe), allowing to easily integrate the graph processing step into the pipeline along with Spark ML – Graph queries: like a Cypher query on a graph database (e.g. Neo4j) – Graph algorithms: PageRank, Dijkstra – Possibility to eliminate joins bill1 bill2 similarity FL/2005/SB436 MI/2005/SB1046 91.38 FL/2005/SB436 MI/2005/HB5143 91.29 FL/2005/SB436 SC/2005/SB1131 82.89 Currently undirected, switch to directed by time SB346 SB1046 HB5143 SB1131 For similarity above threshold
- 17. Applications of policy diffusion detection tool • The policy diffusion detection tool can be used in a number of modes: – Identification of groups of diffused bills in the dataset given a diffusion topic (for instance, “Stand your ground” policy, cyberstalking, marijuana laws …) – Discovery of diffusion topics: consider top-similarity bills within each cluster, careful filtering of uniform bills and interstate compact bills is necessary as they would show high similarity as well – Identification of minimum cost paths connecting two specific legislative proposals on a graph – Identification of the most influential US states for policy diffusion • The political science research paper on applications of the tool is currently in progress
- 18. Performance summary, details on the Spark configuration • The policy diffusion analysis pipeline uses map, filter (narrow), join, and aggregateByKey (wide) transformations – Deterministic all-pairs calculation from approach1 involves a two-sided join: heavy shuffle with O(100 TB) intermediate data – Benefit from increasing spark.shuffle.memoryFraction to 0.6 • Spark applications have been deployed on Hadoop cluster with YARN – 40 executor containers, each using 3 executor cores and 15 GB of RAM per JVM – Use external shuffle service inside the YARN node manager to improve stability of memory-intensive jobs with larger number of executor containers – Custom partitioning to avoid struggler tasks • Calculate efficiency of parallel execution as 𝐸 = 89 :;<;=68> Single executor case
- 19. Conclusions • Evaluated Apache Spark framework for the case of data-intensive machine learning problem of policy diffusion detection in US legislature – Provided a scalable method to calculate all-pairs similarity based on K-means clustering and MinHashLSH – Implemented a text processing pipeline utilizing Apache Avro serialization framework, Spark ML, GraphFrames, and Histogrammar suite of data aggregation primitives – Efficiently calculate all-pairs comparison between legislative bills, estimate relationships between bills on a graph, potentially applicable to a wider class of fundamental text mining problems of finding similar items • Tuned Spark internals (partitioning, shuffle) to obtain good scaling up to O(100) processing cores, yielding 80% parallel efficiency • Utilized Histogrammar tool as a part of the framework to enable interactive analysis, allows a researcher to perform analysis in Scala language, integrating well with Hadoop ecosystem
- 20. Thank You. Alexey Svyatkovskiy email: [email protected] twitter: @asvyatko Kosuke Imai: [email protected] Jim Pivarski: [email protected]
- 21. Backup
- 22. Service node 1 Zookeeper Journal node Primary namenode httpfs Service node 2 Zookeeper Journal node Resource manager Hive master Service node 3 Zookeeper Journal node Standby namenode History server Datanodes Spark HDFS Datanode service Login node Spark Hue YP server LDAP … SSH • A 10 node SGI Linux Hadoop cluster • Intel Xeon CPU E5-2680 v2 @ 2.80GHz CPU processors, 256 GB RAM • All the servers mounted on one rack and interconnected using a 10 Gigabit Ethernet switch • Cloudera distribution of Hadoop configured in high-availability mode using two namenodes • Schedule Spark applications using YARN • Distributed file system (HDFS)
- 23. TF-IDF • TF-IDF weighting: reflect importance of a term t to a document d in corpus D – HashingTF transformer, which maps feature to an index by applying MurmurHash 3 – IDF estimator down-weights components which appear frequently in the corpus 𝐼𝐷𝐹(𝑡, 𝐷) = log 𝐷 + 1 𝐷𝐹 𝑡, 𝐷 + 1 𝑇𝐹𝐼𝐷𝐹 𝑡, 𝑑, 𝐷 = 𝑇𝐹 𝑡, 𝑑 ●𝐼𝐷𝐹(𝑡, 𝐷)
- 24. Dimension reduction: truncated SVD • SVD is applied to the TF-IDF document-feature matrix to perform semantic decomposition and extract concepts which are most relevant for classification • RDD-based API, implement RowMatrix transposition, matrix truncation method needed along with SVD • SVD factorizes the document-feature matrix 𝑀 (mx𝑛) into three matrices: 𝑈, Σ, and 𝑉, such that: 𝑀 = 𝑈 6 Σ 6 𝑉8 Here m is the number of legislative bills (order of 10O ), 𝑘 is the number of concepts, and 𝑛 is the number of features (2#R ) • The left singular matrix 𝑈 is represented as distributed row-matrix, while Σ and 𝑉 are sufficiently small to fit into Spark driver memory mx𝑘 𝑘x𝑘 𝑛x𝑘 𝑘 m ≫ 𝑛 ≫ 𝑘 𝑘
- 25. HistogrammarAggregator class: example An example of a custom dataset Aggregator class using fill and container from Histogrammar
- 26. Signature matrix r rows b bands Columns 2 and 6 Would make a candidate pair Columns 6 and 7 are rather different. Example: Hashing Bands Buckets
- 27. Example ML pipeline (simplified)