



























Learn about SPARK tool and it's componemts
- 2. Topics Why SPARK Evolvement of PIG Why PIG PIG vs Map reduce PIG vs SQL Processing Flow Data Model Execution modes Properties of PIG Practice Sessions
- 3. Need of SPARK Why there was a need of new SYSTEM ? Map reduce was used extensively to analyze the large data sets in batch processing. The latency time was high on map reduce jobs. They needed a system which can run the batch jobs faster than map-reduce. Industry needed a single framework for batch, interactive, SQL, Graph, Streaming and machine learning processing engines natively. Map reduce supported only batch processing. It cannot do any interactive or real time processing which sometimes needed for quick analysis and fast analytics.
- 4. YARN View
- 5. SPARK Components This is a SINGLE SPARK framework with all these components supported natively.
- 6. Contd.. Apache Spark Core Spark Core is the underlying general execution engine for spark platform that all other functionality is built upon. It provides In-Memory computing and referencing datasets in external storage systems. When we run also run batch jobs on top of core using SPARK APIs. Spark SQL Spark SQL is a component on top of Spark Core that introduces a new data abstraction called SchemaRDD, which provides support for structured and semi- structured data. Spark Streaming Spark Streaming leverages Spark Core's fast scheduling capability to perform streaming analytics. It ingests data in mini-batches and performs RDD (Resilient Distributed Datasets) transformations on those mini-batches of data.
- 7. Contd.. MLlib (Machine Learning Library) MLlib is a distributed machine learning framework above Spark because of the distributed memory-based Spark architecture. Spark MLlib is nine times as fast as the Hadoop disk-based version of Apache Mahout. GraphX Graph is a distributed graph-processing framework on top of Spark. It provides an API for expressing graph computation that can model the user- defined graphs by using Pregel abstraction API. It also provides an optimized runtime for this abstraction.
- 8. Why SPARK Apache Spark™ is a fast and general engine for large-scale data processing in memory. Key is in memory processing. SPARK is 10X to 100X faster than map reduce based on in memory and disk operation. Provides high level APIs to interact with JAVA, Python, Scala and R programing languages so you can work on any language in SPARK. SPARK provided a single and unified framework for batch, interactive, SQL, Graph, Streaming and machine learning processing engines natively. All these functionalities were distributed in HADOOP as specialized tools on top of HADOOP.
- 9. Why SPARK It provided real time stream processing system. Faster decision making due to interactive shell processing. This was a general purpose computing engine which supported most type of computation in single framework.
- 10. Map reduce vs SPARK
- 11. Replacing Hadoop ? SPARK is not a REPLACEMENT of Hadoop. You can learn about SPARK framework without learning HADOOP. What does it mean ? HADOOP has STORAGE and PROCESSING both whereas SPARK does not have its own storage system so it can use storage of any file system including HDFS and deployed on top of HADOOP/YARN same as any other YARN supported tool system. SPARK may use file system of amazon S3, HBASE, HADOOP, CASSANDRA and Local file system too. Though, it will work BEST with HDFS because it will get all the flexibilities and properties of HDFS like replication, fault tolerance etc. You may compare Map-reduce with SPARK batch processing system but not with HADOOP as both are separate framework for different purposes though there is some overlap.
- 12. Evolution of SPARK Spark is one of Hadoop’s sub project developed in 2009 in UC Berkeley’s AMPLab by Matei Zaharia. It was Open Sourced in 2010 under a BSD license. It was donated to Apache software foundation in 2013, and now Apache Spark has become a top level Apache project from Feb-2014. This is written in Scala with 2-3% in python but supports APIs for JAVA, Scala, python and R. There are still lot of research and work going on SPARK and upgraded version come anytime.
- 13. Modes of running SPARK
- 14. Contd.. Standalone − Spark Standalone deployment means Spark occupies the place on top of HDFS(Hadoop Distributed File System) and space is allocated for HDFS, explicitly. Here, Spark and Map Reduce will run side by side to cover all spark jobs on cluster. This mode run on cluster. Hadoop Yarn − Hadoop Yarn deployment means, simply, spark runs on Yarn. It helps to integrate Spark into Hadoop ecosystem or Hadoop stack. It allows other components to run on top of stack. This can be run in client mode and cluster mode. Client means interactive and cluster means submitting the jar to Hadoop cluster. This mode run on cluster. Local Mode – Spark runs on your local system and all SPARK processes run on single JVM process on your client machine. This mode is used to test your SPARK jobs. This mode cannot run on cluster. Its for single client machine.
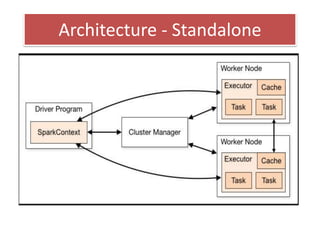
- 15. Standalone mode
- 18. RDD (Resilient Distributed Dataset) RDD is a collection of data having 5 properties, 1. Immutability. 2. Lazy Evaluation 3. Type inferred. 4. Cacheable Lets discuss each.
- 19. What is Immutability Immutability means once its created it will never change. Big Data by default is immutable as it provides streaming access. Immutability helps in, Parallelize Caching Because underneath data will never change so you can parallelize and cahce it easily. Immutability is about the value/object not about the reference. String name = “Siddharth”; name =“Siddharth ”+”Singh”;
- 20. What is Immutability Immutable programming, Here you create a new object anytime you want to do any transformations. Like, Val collection = {1,2,3,4} Val newcollection = collection. Map(value=>value+1) Both collections are different due to immutability. Same as each transformation would require a one more copy and so on.
- 21. What is Immutability Drawbacks, This is good for parallelism but not for space. Multiple transformations is causing multiple copies of data. Its causing multiple copies of data even for small transformations and we are passing through whole dataset for each transformation. This may cause poor performance in BIG data world. BUT This is overcome by Lazy feature.
- 22. What is Laziness Laziness means do not compute or transform until needed or action is called. Laziness just evaluate the statements but do not execute it. It separates the evaluation with execution. Does not do anything until some action is called on it.
- 23. What is Laziness Val collection = {1,2,3,4} Val c1 = collection. Map(value=>value+1) Val c2 = collection. Map(value=>value+2) Print c2//action Since its lazy, it will combine both in to one pass Val c2 = collection. Map(value=> { var result= value+1 var result = value +2 }) Since no one asked for c1, I do not need to create the object of it.
- 24. What is Laziness You can be only lazy when you are immutable otherwise laziness will have issues in combining and transforming the values. You cannot combine transformations if there are any errors in transformations due to data types. So laziness and immutability giving me parallelism and faster processing in distributed environment. MapReduce has immutability but lacks laziness.
- 25. Laziness Challenges Laziness may have problem in data type conversion errors. We do not want to run a Job and after 1 hr. it fails due to data type casting errors. PIG is also a lazy language. Sometimes its difficult to debug the lazy language because its not executing until action is called. Job may fail due to semantic issues if casting is not proper in lazy language and we do not want to do it. Like in MapReduce, sometimes job may fail when casting is not done properly and JAVA did not catch the data type casting during compilation and job failed at runtime. In SAPRK, you will never get data type casting error at run time. What we want ? We want a programming language which is type inferred means where program identifies the data types of variables and expressions and gives semantics error at evaluation/compiling time not at the run time.
- 26. Type Inferred It means compiler will decide the data type of a value/expressions without user declaring it. Eg, Val collection = {1,2,3,4} Val c1 = collection. Map(value=>value+1) Here ‘c1’ will always be an array because map function will always return an array if working on an array data type. Val c2=c1.count //inferred as int c2 is inferred as integer now and cannot change its data type now further in programming. This is fixed now based on return function of c1.count. Val c3=c2.map (value => value+1) This will give an error because you cannot apply map function over an integers. This is called static typing.
- 27. What is Cacheable Cacheable means the data which can be cached in memory (RAM) easily. Immutability helps here. If your underlying data is not changing then you can cache it easily without any problem as know that data will be same. Since its lazy and immutable, you can create the dataset easily through lineage which means that each transformations can be remembered for long and recreate at any point of time. Caching will off course improve the performance of any system. This the reason the SPARK is written in JAVA as these properties were not in JAVA. SCALA is combination of functional and OOPS programming and runs on JVM.
- 28. RDD (Resilient Distributed Dataset) What is RDD ? (It’s the heart of SPARK). This is the main abstraction in SPARK. Resilient Distributed Datasets (RDD) is a fundamental data structure of Spark. Its an interface to the data that how data will look like ? Each RDD is divided into logical partitions. RDD is logical collection of data but you can cache the actual data too in memory. It is fault tolerant due to lineage if any RDD or its partition is lost in transformations then it can rebuilt. RDD is memory computation which makes it faster execution on cluster.
- 29. Data Sharing in RDD Data Sharing using Spark RDD Data sharing is slow in Map Reduce due to replication, serialization, and disk IO. Most of the Hadoop applications, they spend more than 90% of the time doing HDFS read-write operations. Recognizing this problem, researchers developed a specialized framework called Apache Spark. The key idea of spark is Resilient Distributed Datasets (RDD); it supports in-memory processing computation. Data sharing in memory is 10 to 100 times faster than network and Disk.