







![Cache Example
Word addr Binary addr Hit/miss Cache block
22 10 110 Miss 110
Index V Tag Data
000 N
001 N
010 N
011 N
100 N
101 N
110 Y 10 Mem[10110]
111 N
Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 10](https://image.slidesharecdn.com/lecture6memoryhierarchy-130130112743-phpapp01/85/Lecture6-memory-hierarchy-10-320.jpg)
![Cache Example
Word addr Binary addr Hit/miss Cache block
26 11 010 Miss 010
Index V Tag Data
000 N
001 N
010 Y 11 Mem[11010]
011 N
100 N
101 N
110 Y 10 Mem[10110]
111 N
Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 11](https://image.slidesharecdn.com/lecture6memoryhierarchy-130130112743-phpapp01/85/Lecture6-memory-hierarchy-11-320.jpg)
![Cache Example
Word addr Binary addr Hit/miss Cache block
22 10 110 Hit 110
26 11 010 Hit 010
Index V Tag Data
000 N
001 N
010 Y 11 Mem[11010]
011 N
100 N
101 N
110 Y 10 Mem[10110]
111 N
Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 12](https://image.slidesharecdn.com/lecture6memoryhierarchy-130130112743-phpapp01/85/Lecture6-memory-hierarchy-12-320.jpg)
![Cache Example
Word addr Binary addr Hit/miss Cache block
16 10 000 Miss 000
3 00 011 Miss 011
16 10 000 Hit 000
Index V Tag Data
000 Y 10 Mem[10000]
001 N
010 Y 11 Mem[11010]
011 Y 00 Mem[00011]
100 N
101 N
110 Y 10 Mem[10110]
111 N
Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 13](https://image.slidesharecdn.com/lecture6memoryhierarchy-130130112743-phpapp01/85/Lecture6-memory-hierarchy-13-320.jpg)
![Cache Example
Word addr Binary addr Hit/miss Cache block
18 10 010 Miss 010
Index V Tag Data
000 Y 10 Mem[10000]
001 N
010 Y 10 Mem[10010]
011 Y 00 Mem[00011]
100 N
101 N
110 Y 10 Mem[10110]
111 N
Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 14](https://image.slidesharecdn.com/lecture6memoryhierarchy-130130112743-phpapp01/85/Lecture6-memory-hierarchy-14-320.jpg)
















![Associativity Example
Compare 4-block caches
Direct mapped, 2-way set associative,
fully associative
Block access sequence: 0, 8, 0, 6, 8
Direct mapped
Block Cache Hit/miss Cache content after access
address index 0 1 2 3
0 0 miss Mem[0]
8 0 miss Mem[8]
0 0 miss Mem[0]
6 2 miss Mem[0] Mem[6]
8 0 miss Mem[8] Mem[6]
Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 31](https://image.slidesharecdn.com/lecture6memoryhierarchy-130130112743-phpapp01/85/Lecture6-memory-hierarchy-31-320.jpg)
![Associativity Example
2-way set associative
Block Cache Hit/miss Cache content after access
address index Set 0 Set 1
0 0 miss Mem[0]
8 0 miss Mem[0] Mem[8]
0 0 hit Mem[0] Mem[8]
6 0 miss Mem[0] Mem[6]
8 0 miss Mem[8] Mem[6]
Fully associative
Block Hit/miss Cache content after access
address
0 miss Mem[0]
8 miss Mem[0] Mem[8]
0 hit Mem[0] Mem[8]
6 miss Mem[0] Mem[8] Mem[6]
8 hit Mem[0] Mem[8] Mem[6]
Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 32](https://image.slidesharecdn.com/lecture6memoryhierarchy-130130112743-phpapp01/85/Lecture6-memory-hierarchy-32-320.jpg)








Lecture6 memory hierarchy
- 1. Memor y Hierarchy Dr. Ahmed Abdelgawad
- 2. §5.1 Introduction Memory Technology Static RAM (SRAM) 0.5ns – 2.5ns, $2000 – $5000 per GB Dynamic RAM (DRAM) 50ns – 70ns, $20 – $75 per GB Magnetic disk 5ms – 20ms, $0.20 – $2 per GB Ideal memory Access time of SRAM Capacity and cost/GB of disk Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 2
- 3. Principle of Locality Programs access a small proportion of their address space at any time Temporal locality Items accessed recently are likely to be accessed again soon e.g., instructions in a loop Spatial locality Items near those accessed recently are likely to be accessed soon E.g., sequential instruction access, array data Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 3
- 4. Taking Advantage of Locality Memory hierarchy Store everything on disk Copy recently accessed (and nearby) items from disk to smaller DRAM memory Main memory Copy more recently accessed (and nearby) items from DRAM to smaller SRAM memory Cache memory attached to CPU Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 4
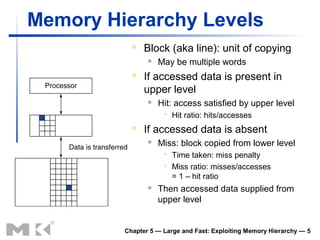
- 5. Memory Hierarchy Levels Block (aka line): unit of copying May be multiple words If accessed data is present in upper level Hit: access satisfied by upper level Hit ratio: hits/accesses If accessed data is absent Miss: block copied from lower level Time taken: miss penalty Miss ratio: misses/accesses = 1 – hit ratio Then accessed data supplied from upper level Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 5
- 6. §5.2 The Basics of Caches Cache Memory Cache memory The level of the memory hierarchy closest to the CPU Given accesses X1, …, Xn–1, Xn How do we know if the data is present? Where do we look? Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 6
- 7. Direct Mapped Cache Location determined by address Direct mapped: only one choice (Block address) modulo (#Blocks in cache) #Blocks is a power of 2 Use low-order address bits Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 7
- 8. Tags and Valid Bits How do we know which particular block is stored in a cache location? Store block address as well as the data Actually, only need the high-order bits Called the tag What if there is no data in a location? Valid bit: 1 = present, 0 = not present Initially 0 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 8
- 9. Cache Example 8-blocks, 1 word/block, direct mapped Initial state Index V Tag Data 000 N 001 N 010 N 011 N 100 N 101 N 110 N 111 N Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 9
- 10. Cache Example Word addr Binary addr Hit/miss Cache block 22 10 110 Miss 110 Index V Tag Data 000 N 001 N 010 N 011 N 100 N 101 N 110 Y 10 Mem[10110] 111 N Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 10
- 11. Cache Example Word addr Binary addr Hit/miss Cache block 26 11 010 Miss 010 Index V Tag Data 000 N 001 N 010 Y 11 Mem[11010] 011 N 100 N 101 N 110 Y 10 Mem[10110] 111 N Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 11
- 12. Cache Example Word addr Binary addr Hit/miss Cache block 22 10 110 Hit 110 26 11 010 Hit 010 Index V Tag Data 000 N 001 N 010 Y 11 Mem[11010] 011 N 100 N 101 N 110 Y 10 Mem[10110] 111 N Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 12
- 13. Cache Example Word addr Binary addr Hit/miss Cache block 16 10 000 Miss 000 3 00 011 Miss 011 16 10 000 Hit 000 Index V Tag Data 000 Y 10 Mem[10000] 001 N 010 Y 11 Mem[11010] 011 Y 00 Mem[00011] 100 N 101 N 110 Y 10 Mem[10110] 111 N Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 13
- 14. Cache Example Word addr Binary addr Hit/miss Cache block 18 10 010 Miss 010 Index V Tag Data 000 Y 10 Mem[10000] 001 N 010 Y 10 Mem[10010] 011 Y 00 Mem[00011] 100 N 101 N 110 Y 10 Mem[10110] 111 N Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 14
- 15. Address Subdivision Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 15
- 16. Example: Larger Block Size 64 blocks, 16 bytes/block To what block number does address 1200 map? Block address = 1200/16 = 75 Block number = 75 modulo 64 = 11 31 10 9 4 3 0 Tag Index Offset 22 bits 6 bits 4 bits Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 16
- 17. Block Size Considerations Larger blocks should reduce miss rate Due to spatial locality But in a fixed-sized cache Larger blocks ⇒ fewer of them More competition ⇒ increased miss rate Larger miss penalty Can override benefit of reduced miss rate Early restart and critical-word-first can help Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 17
- 18. Cache Misses On cache hit, CPU proceeds normally On cache miss Stall the CPU pipeline Fetch block from next level of hierarchy Instruction cache miss Restart instruction fetch Data cache miss Complete data access Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 18
- 19. Write-Through On data-write hit, could just update the block in cache But then cache and memory would be inconsistent Write through: also update memory But makes writes take longer Solution: write buffer Holds data waiting to be written to memory CPU continues immediately Only stalls on write if write buffer is already full Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 19
- 20. Write-Back Alternative: On data-write hit, just update the block in cache Keep track of whether each block is dirty When a dirty block is replaced Write it back to memory Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 20
- 21. Example Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 21
- 22. Increasing Memory Bandwidth Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 22
- 23. DRAM Generations Year Capacity $/GB 300 1980 64Kbit $1500000 250 1983 256Kbit $500000 1985 1Mbit $200000 200 1989 4Mbit $50000 Trac 150 1992 16Mbit $15000 Tcac 1996 64Mbit $10000 100 1998 128Mbit $4000 50 2000 256Mbit $1000 2004 512Mbit $250 0 2007 1Gbit $50 '80 '83 '85 '89 '92 '96 '98 '00 '04 '07 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 23
- 24. §5.3 Measuring and Improving Cache Performance Measuring Cache Performance Components of CPU time Program execution cycles Includes cache hit time Memory stall cycles Mainly from cache misses With simplifying assumptions: Memory stall cycles Memory accesses = × Miss rate × Miss penalty Program Instructions Misses = × × Miss penalty Program Instruction Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 24
- 25. Cache Performance Example Given I-cache miss rate = 2% D-cache miss rate = 4% Miss penalty = 100 cycles Base CPI (ideal cache) = 2 Load & stores are 36% of instructions Miss cycles per instruction I-cache: 0.02 × 100 = 2 D-cache: 0.36 × 0.04 × 100 = 1.44 Actual CPI = 2 + 2 + 1.44 = 5.44 Ideal CPU is 5.44/2 =2.72 times faster Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 25
- 26. Average Access Time Hit time is also important for performance Average memory access time (AMAT) AMAT = Hit time + Miss rate × Miss penalty Example CPU with 1ns clock, hit time = 1 cycle, miss penalty = 20 cycles, I-cache miss rate = 5% AMAT = 1 + 0.05 × 20 = 2ns 2 cycles per instruction Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 26
- 27. Performance Summary When CPU performance increased Miss penalty becomes more significant Decreasing base CPI Greater proportion of time spent on memory stalls Can’t neglect cache behavior when evaluating system performance Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 27
- 28. Associative Caches Fully associative Allow a given block to go in any cache entry Requires all entries to be searched at once Comparator per entry (expensive) n-way set associative Each set contains n entries Block number determines which set (Block number) modulo (#Sets in cache) Search all entries in a given set at once n comparators (less expensive) Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 28
- 29. Associative Cache Example Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 29
- 30. Spectrum of Associativity For a cache with 8 entries Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 30
- 31. Associativity Example Compare 4-block caches Direct mapped, 2-way set associative, fully associative Block access sequence: 0, 8, 0, 6, 8 Direct mapped Block Cache Hit/miss Cache content after access address index 0 1 2 3 0 0 miss Mem[0] 8 0 miss Mem[8] 0 0 miss Mem[0] 6 2 miss Mem[0] Mem[6] 8 0 miss Mem[8] Mem[6] Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 31
- 32. Associativity Example 2-way set associative Block Cache Hit/miss Cache content after access address index Set 0 Set 1 0 0 miss Mem[0] 8 0 miss Mem[0] Mem[8] 0 0 hit Mem[0] Mem[8] 6 0 miss Mem[0] Mem[6] 8 0 miss Mem[8] Mem[6] Fully associative Block Hit/miss Cache content after access address 0 miss Mem[0] 8 miss Mem[0] Mem[8] 0 hit Mem[0] Mem[8] 6 miss Mem[0] Mem[8] Mem[6] 8 hit Mem[0] Mem[8] Mem[6] Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 32
- 33. How Much Associativity Increased associativity decreases miss rate But with diminishing returns Simulation of a system with 64KB D-cache, 16-word blocks, SPEC2000 1-way: 10.3% 2-way: 8.6% 4-way: 8.3% 8-way: 8.1% Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 33
- 34. Set Associative Cache Organization Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 34
- 35. Replacement Policy Direct mapped: no choice Set associative Choose among entries in the set Least-recently used (LRU) Choose the one unused for the longest time Simple for 2-way, manageable for 4-way, too hard beyond that Random Gives approximately the same performance as LRU for high associativity Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 35
- 36. Multilevel Caches Primary cache attached to CPU Small, but fast Level-2 cache services misses from primary cache Larger, slower, but still faster than main memory Main memory services L-2 cache misses Some high-end systems include L-3 cache Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 36
- 37. Multilevel Cache Example Given CPU base CPI = 1, clock rate = 4GHz Miss rate/instruction = 2% Main memory access time = 100ns With just primary cache Miss penalty = 100ns/0.25ns = 400 cycles Effective CPI = 1 + 0.02 × 400 = 9 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 37
- 38. Example (cont.) Now add L-2 cache Access time = 5ns Global miss rate to main memory = 0.5% Primary miss with L-2 hit Penalty = 5ns/0.25ns = 20 cycles CPI = 1 + 0.02 × 20 + 0.005 × 400 = 3.4 Performance ratio = 9/3.4 = 2.6 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 38
- 39. Multilevel Cache Considerations Primary cache Focus on minimal hit time L-2 cache Focus on low miss rate to avoid main memory access Hit time has less overall impact Results L-1 cache usually smaller than a single cache L-1 block size smaller than L-2 block size Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 39
- 40. Virtual Memory Use main memory as a “cache” for secondary (disk) storage Managed jointly by CPU hardware and the operating system (OS) Programs share main memory Each gets a private virtual address space holding its frequently used code and data Protected from other programs CPU and OS translate virtual addresses to physical addresses VM “block” is called a page VM translation “miss” is called a page fault Chapter 5 — Large and Fast: Exploiting Memory Hierarchy — 40
Editor's Notes
- #2: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #3: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #4: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #5: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #6: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #7: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #8: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #9: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #10: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #11: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #12: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #13: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #14: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #15: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #16: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #17: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #18: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #19: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #20: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #21: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #22: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #23: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #24: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #25: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #26: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #27: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #28: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #29: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #30: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #31: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #32: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #33: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #34: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #35: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #36: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #37: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #38: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #39: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #40: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy
- #41: Morgan Kaufmann Publishers 30 January 2013 Chapter 5 — Large and Fast: Exploiting Memory Hierarchy