Lessons learned from embedding Cassandra in xPatterns
3 likes1,149 views

The document discusses lessons learned from embedding Cassandra in the xPatterns big data analytics platform. It provides an agenda that includes discussing Cassandra usage in xPatterns, the necessary developments like data modeling optimizations, robust REST APIs, geo-replication, and a demo of exporting to NoSQL APIs. Key lessons learned since Cassandra versions 0.6 to 2.0.6 are also summarized, such as the need for consistent clocks, reducing column families, and monitoring.
















Lessons learned from embedding Cassandra in xPatterns
- 1. 1 Atigeo Confidential Lessons learned from embedding Cassandra in the xPatterns Platform Seattle Cassandra Users April 2014
- 2. 2 Atigeo Confidential • Cassandra use within xPatterns • What we had to build • Data model optimization • Robust REST API’s • Geo-Replication • Demo: Export to NoSql API Agenda
- 3. 3 Atigeo Confidential xPatterns The Cloud-based, Big Data Analytics Platform Benefits Intelligent apps in man-days Differentiators End-to-End Big Data Platform Cutting-Edge Intelligence Real-time unsupervised analyticsHybrid Intelligence System Learning & Feedback Automated repair & inductive reasoning Measurably, best-ever analytical performance
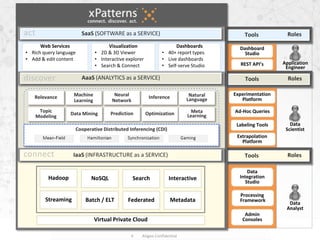
- 4. 4 Atigeo Confidential Tools Roles Tools Roles Data Scientist Tools Rolesconnect IaaS (INFRASTRUCTURE as a SERVICE) Cooperative Distributed Inferencing (CDI) Neural Network Inference Natural Language Topic Modeling Data Mining Prediction Optimization Machine Learning Relevance Meta Learning AaaS (ANALYTICS as a SERVICE)discover Dashboards • 40+ report types • Live dashboards • Self-serve Studio Visualization • 2D & 3D Viewer • Interactive explorer • Search & Connect Web Services • Rich query language • Add & edit content act SaaS (SOFTWARE as a SERVICE) Admin Consoles Data Integration Studio Data Analyst Application Engineer Dashboard Studio REST API’s Experimentation Platform Ad-Hoc Queries Virtual Private Cloud Hadoop NoSQL Search Streaming Batch / ELT Federated Interactive Metadata Processing Framework Labeling Tools Extrapolation Platform
- 5. 5 Atigeo Confidential Provider Referral Network: An interactive big data visualization tool for investigating upstream and downstream referral patterns among physicians, connecting physicians to specialties and to other physicians’ practice details.
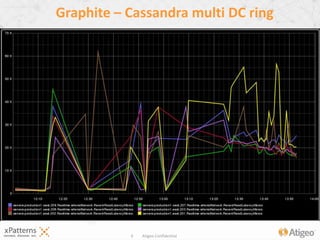
- 6. 6 Atigeo Confidential Cassandra multi DC ring – read latency
- 7. 7 Atigeo Confidential Cassandra multi DC ring – read latency
- 8. 8 Atigeo Confidential • Export to NoSQL demo • Data model optimization Publishing from HDFS/Hive/Shark to Cassandra • Robust REST API’s Instrumentation Throttling & auto-retries • Geo-Replication Cross-data-center replication, encryption & failover • Lessons Learned since 0.6 till 2.0.6 What we’d like to share tonight
- 11. 11 Atigeo Confidential VPC-to-VPC IPSEC Tunnel
- 12. 12 Atigeo Confidential Export to NoSql API • Datasets in the warehouse need to be exposed to high-throughput low-latency real-time APIs. Each application requires extra processing performed on top of the core datasets, hence additional transformations are executed for building data marts inside the warehouse • Exporter tool builds the efficient data model and runs an export of data from a Shark/Hive table to a Cassandra Column Family, through a custom Spark job with configurable throughput (configurable Spark processors against a Cassandra ring) (instrumentation dashboard embedded, logs, progress and instrumentation events pushed though SSE) • Data Modeling is driven by the read access patterns provided by an application engineer building dashboards and visualizations: lookup key, columns (record fields to read), paging, sorting, filtering • The end result of a job run is a REST API endpoint (instrumented, monitored, resilient, geo- replicated) that uses the underlying generated Cassandra data model and fuels the data in the dashboards • Configuration API provided for creating export jobs and executing them (ad-hoc or scheduled).
- 14. 14 Atigeo Confidential Cassandra multi DC ring – write latency
- 15. 15 Atigeo Confidential Mesos/Spark cluster
- 16. 16 Atigeo Confidential Nagios monitoring
- 17. 17 Atigeo Confidential • NTP: synchronize ALL clocks (servers and clients) • Reduce the number of CFs (avoid OOM) • Rows not too skinny and not too wide (avoid OOM) o Less memory pressure during high-throughput writes o Reduced network I/O, less rows, more column slices o Key cache & bloom filter index size affects perf o Efficient compaction, avoid hot spots • Custom serialization and dynamic columns for maximum perf gain • Do not drop CFs before emptying them (truncate/compact first) • Monitoring, instrumentation, automatic restarts • ConsistencyLevel: ONE is best … for our use cases • Key cache, Snappy compression Lessons learned 0.6 - 2.0.6
- 18. 18 Atigeo Confidential Q & A
- 19. © 2013 Atigeo, LLC. All rights reserved. Atigeo and the xPatterns logo are trademarks of Atigeo. The information herein is for informational purposes only and represents the current view of Atigeo as of the date of this presentation. Because Atigeo must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Atigeo, and Atigeo cannot guarantee the accuracy of any information provided after the date of this presentation. ATIGEO MAKES NO WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, AS TO THE INFORMATION IN THIS PRESENTATION.
Editor's Notes
- #4: Introduce AtigeoWhy am I telling you about xPatterns?
- #5: Not repeat the last slide – jump to highlighting where Cassandra fits in.
- #6: Referral Provider Network: one of the applications we built for our healthcare customer using the xPatterns APIs and tools on the new beyond BDAS infrastructure: ELT Pipeline, Export to NoSQL API. The dashboard for the RPN application was built using D3.js and angular against the generic api published by the export tool. The application allows for building a graph of downstream and upstream referred and referring providers, grouped by specialty and with computed aggregates like patient counts, claim counts and total charged amounts. RPN is used for both fraud detection and for aiding a clinic buying decision, by following the busiest graph paths.The dataset behind the app consists of 6.5 billion medical records, from which we extracted 1.7 million providers (Shark warehouse) and built 53 million relationships in the graph (persisted in Cassandra)While we demo the graph building we will also look at the Graphite instrumentation dashboard for analyzing the runtime performance of the geo-replicated Cassandra read operations during the demo
- #7: Instrumentation dashboard showcasing the read latency measured during peak (40ms average, 60peak)
- #8: Instrumentation dashboard showcasing the read latency measured after a few runs of a stress test (key cache and OS Buffer cache hit rate are high ) (20ms max … spike indicating a slower node .. Compacting maybe?)
- #10: Cassandra is xPatterns: real-time database for user facing apis and dashboards applications, system of records for real-time analytics use-cases (Kafka/Storm/Cassandra), distribute in-memory cache store for configuration data, persistence store for user feedback in semantic search and dynamic ontology use cases (soldCloud/Cassandra/Zookeeper).
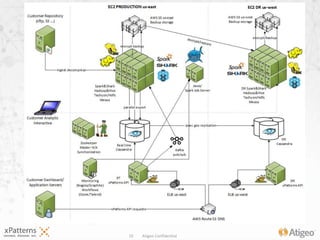
- #11: The physical architecture diagram for our largest customer deployment, demonstrating the enterprise-grade attributes of the platform: scalability, high availability, performance, resilience, manageability while providing means for geo-failover (warehouse), geo-replication (real-time DB), data and system monitoring, instrumentation, backup & restore.Cassandra rings are DC-replicated across EC2 east and west coast regions, data between geo-replicas synchronized in real time through an ipsec tunnel (VPC-to-VPC).Geo-replicated apis behind an AWS Route 53 DNS service (latency based resource records sets) and ELBs ensures users requests are served from the closest geographical location. Failure to an entire region (happened to us during a big conference!) does not affect our availability and SLAs.User facing dashboards are served from Cassandra (real-time store), with data being exported from a data warehouse (Shark/Hive) build on top a Mesos-managed Spark/Hadoop cluster.Export jobs are instrumented and provide a throttling mechanism to control throughput.Export jobs run on the east-coast only, data is synchronized in real time with the west coast ring. Generated apis are automatically instrumented (Graphite) and monitored (Nagios).
- #12: Security Architecture for the VPC-to-VPC hosting the DC-replicated rings.Openswan used on the VPN Instances in the public subnets for the ipsec tunnel encryptionhttp://aws.amazon.com/articles/5472675506466066
- #13: Datasets in the warehouse need to be exposed to high-throughput low-latency real-time APIs. Each application requires extra processing performed on top of the core datasets, hence additional transformations are executed for building data marts inside the warehousePre-optimization Shark/Hive queries required for building an efficient data model for Cassandra persistence: minimal number of column families, wide rows (50-100 MB compressed). Resulting data model is efficient for both read (dashboard/API) and write (export/updates) requestsExporter tool builds the efficient data model and runs an export of data from a Shark/Hive table to a Cassandra Column Family, through a custom Spark job with configurable throughput (configurable Spark processors against a Cassandra ring)Data Modeling is driven by the read access patterns: lookup key, columns (record fields to read), paging, sorting, filtering.The data access patterns is used for automatically publishing a REST api that uses the underlying generated Cassandra data model and it fuels the data in the dashboardsExecution logs behind workflows, progress report and instrumentation events for the dashboard are pushed to the browser through SSE (Zookeeper watchers used for synchronization)
- #14: Datasets in the warehouse need to be exposed to high-throughput low-latency real-time APIs. Each application requires extra processing performed on top of the core datasets, hence additional transformations are executed for building data marts inside the warehousePre-optimization Shark/Hive queries required for building an efficient data model for Cassandra persistence: minimal number of column families, wide rows (50-100 MB compressed). Resulting data model is efficient for both read (dashboard/API) and write (export/updates) requestsExporter tool builds the efficient data model and runs an export of data from a Shark/Hive table to a Cassandra Column Family, through a custom Spark job with configurable throughput (configurable Spark processors against a Cassandra ring)Data Modeling is driven by the read access patterns: lookup key, columns (record fields to read), paging, sorting, filtering.The data access patterns is used for automatically publishing a REST api that uses the underlying generated Cassandra data model and it fuels the data in the dashboardsExecution logs behind workflows, progress report and instrumentation events for the dashboard are pushed to the browser through SSE (Zookeeper watchers used for synchronization)
- #15: Instrumentation dashboard showcasing the write latency measured during the export to noSql job (7ms max). Writes are performed against the east-coast DC … they are propagated to the west coast, however the JMX metric exposed (Write.Latency.OneMinuteRate) does not reflect it … need to build a new dashboard with different metrics!
- #16: Mesos/Spark context (CoarseGrainedMode) with a fixed 120 cores spread out across 4 nodes
- #17: Nagios monitoring for the geo-replicated, instrumented generated apis. The APIs (readers) and the Spark executors (writers) have a retry mechanism (AOP aspects) that implement throttling when Cassandra is under siege …
- #18: Lessons learned over the past 3 years with operating Cassandra rings at scale.Custom serialization of objects instead of individually serializing column names/column values for object field names/field values, yields the most performance gains!Describe each tip in detail …