Lessons Learned in the Development of a Web-scale Search Engine: Nutch2 and beyond
Download as PPT, PDF5 likes3,966 views

This document summarizes the history and development of the Nutch web search engine project. It discusses how Nutch evolved from its original version to incorporate Hadoop and become more modular by delegating functions like indexing and parsing to other Apache projects like Solr and Tika. The current version, Nutch 2.0, aims to have a slimmed down architecture where it acts as a delegator to these other frameworks rather than handling these functions itself. The document also reflects on lessons learned from earlier stages of the project around community engagement, maintenance, and configuration challenges.












































Lessons Learned in the Development of a Web-scale Search Engine: Nutch2 and beyond
- 1. Lessons Learned in the Development of a Web-scale Search Engine: Nutch2 and beyond Chris A. Mattmann Senior Computer Scientist, NASA Jet Propulsion Laboratory Adjunct Assistant Professor, Univ. of Southern California Member, Apache Software Foundation
- 2. Roadmap • What is Nutch? • What are the current versions of Nutch? • What can it do? • What did we do right? • What did we do wrong? • Where is Nutch going?
- 3. And you are? • Apache Member involved in – Tika (VP,PMC), Nutch (PMC), Incubator (PMC), OODT (Mentor), SIS (Mentor), Lucy (Mentor) and Gora (Champion) • Architect/Developer at NASA JPL in Pasadena, CA • Software Architecture/Engineeri ng Prof at USC
- 4. is… • A project originally started by Doug Cutting • Nutch builds upon the lower level text indexing library and API called Lucene • Nutch provides crawling services, protocol services, parsing services, content management services on top of the indexing capability provided by Lucene • Allows you to sand up a web-scale infra.
- 5. Community • Mailing lists – User: 972 peeps – Dev: 520 peeps • Committers/PMC – 8 peeps – All 8 active: SERIOUSLY • Releases – 11 releases so far – Working on 2.0 Credit: svnsearch.org
- 6. What Currently Exists? • Version 0.6.x – First easily deployable version • Version 0.7.x – Added several new features including several new parsers (MS-WORD, PowerPoint), URLFilter extension point, first Apache release after Incubation, mime type system • Version 0.8.x – Completely new underlying architecture based on Hadoop – Parse plugins framework, multi-valued metadata container – Parser Factory enhancement • Version 0.9.x – Major bug fixes – Hadoop, and Lucene library upgrades • Version 1.0 – Flexible filter framework – Flexible scoring – Initial integration with Tika – Full Search Engine functionality and capabilities, in production at large scale (Internet Archive)
- 7. What are the recent versions? • Version 1.1, upgrade all Nutch library deps (Hadoop, Tika, etc.) and make Fetcher faster • Version 1.2, fix some big time bugs (NPE in distributed search), lots of feature upgrades – You should be using this version
- 8. Some active dev areas • Plenty! • Bug fixes (> 200 issues in JIRA right now with no resolution) • Nutch 2.0 architecture – http://search-lucene.com/m/gbrBF1RMWk9 – Refactored Nutch architecture, delegating to Solr, HBase, Tika, and ORM
- 9. Why Nutch? • Observation: Web Search is a commodity – Why can’t it be provided freely? • Allows tweaking of typically “hidden” ranking algorithms • Allows developers to focus less on the infrastructure (since Brin & Page’s paper, the infrastructure is well-known), and more on providing value-added capabilities
- 10. Why Nutch? • Value-added capabilities – Improving fetching speed – Parsing and handling of the hundreds of different content types available on the internet – Handling different protocols for obtaining content – Better ranking algorithms (OPIC, PageRank) • More or less, in Nutch, these capabilities all map to extension points available via Nutch’s plugin framework
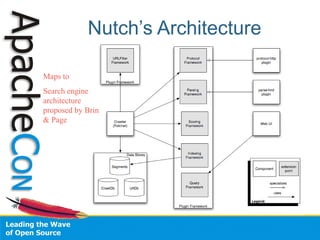
- 11. Nutch’s Architecture • Nutch Core facilities – Parsing – Indexing – Crawling – Content Acquisition – Querying – Plugin Framework • Nutch’s extension points – Scoring, Parsing, Indexing, Querying, URLFiltering
- 12. Nutch’s Architecture Maps to Search engine architecture proposed by Brin & Page
- 13. Real world application of Nutch • I work at NASA’s Jet Propulsion Laboratory • NASA’s Planetary Data System – NASA’s archive for all planetary science data collected by missions over the past 30 years – Collected 20 TB over the past 30 years • Increasing to over 200 TB in the next 3 years! – Built up a catalog of all data collected • Where does Nutch fit in?
- 14. Where does Nutch fit into the PDS? • PDS Management Council decide they want “Google-like” search of the PDS catalog • Our plan: use Nutch to implement capability for PDS
- 15. PDS Google-like Search Architecture Search Engine Architecture (e.g. Nutch, Google) PDS Catalog P D S - D Existing PDS Query Indexer Index Lucene Crawler PDS Extract Parser PDS Parser pds.war Tomcat Web Server Catalog Metadata Credit: D. Crichton, S. Hughes, P. Ramirez, R. Joyner, S. Hardman, C. Mattmann
- 16. Approach • Export PDS catalog datasets in RDF format (flat files) • Use nutch to crawl RDF files – protocol-file plugin in Nutch • Wrote our own parse-pds plugin – Parse the RDF files, and then extract the metadata • Wrote our own index-pds plugin – Index the fields that we want from the parsed metadata • Wrote our own query-pds plugin – Search the index on the fields that we want
- 17. Search Interface
- 18. Results
- 19. Some Nutch History • In the next few slides, we’ll go through some of Nutch’s history, including my involvement, the history of Nutch dev, and how we came to today
- 20. How I got involved • In CS72: Seminar on Search Engines at USC – Okay well it used to be called CS599, but you get the picture • Started out by contributing RSS parsing plugin – My final project in 599 • Moved on from there to – NUTCH-88, redesign of the parsing framework – NUTCH-139, Metadata container support – NUTCH-210, Web Context application file – And various other bug fixes, and contributions here and there – Mailing list support – Wiki support • Became committer in October 2006 • Helped spin Nutch into Apache TLP, March 2010, Nutch PMC member
- 21. The Big Yellow Elephant • Before this guy was born • Lots of folks interested in Nutch Hadoop is born (January 2008) Credit: svnsearch.org
- 22. Post Hadoop Life • Nutch project kind of withered – Well more than “kind of” it did wither – Went years in-between a release • 0.8 to 1.0 took a while • Dev Community went into maintenance mode – Many committers simply went inactive • User Community deteriorated
- 23. Some Observations • It was pretty difficult to attract new committers – Took too long to VOTE them in – They were only interested in Hadoop type stuff – Not many organizations were doing web- scale search • Existing active committers dwindled • I was one of them!
- 24. Some Observations • There wasn’t a plan for what to do next – What features to work on? – What bugs to fix? – Many considered Nutch to be “production” worthy in its current form and not a huge number of internet-scale users so people just “put up” with its existing issues, e.g., difficult to configure ?
- 25. Hadoop wasn’t the only spinoff • A lot of us interested in content detection and analysis, another major Nutch strength, went off to work on that in some other Apache project that I can’t remember the name of
- 26. How can Nutch reorganize? • Strong feeling from Nutch community that we should take whomever is left and think about what the “next generation” Nutch (Nutch2) would look like • (Several cycles of) Mailing threads started by Andrzej Bialecki, Dennis Kubes, Otis Gospondetic
- 27. Initial Nutch2 fizzles • Ended up being a lot of talk, but there wasn’t enough interest to pick up a shovel and help dig the hole • But…there were interesting things going on – Example: Nutchbase work from Dogacan, and Enis
- 28. What was “Nutchbase”? • Take the Apache implementation of Google’s “BigTable” – Col oriented storge, high scalability in columns and rows • Store Nutch Web page content +
- 29. Lots of interest in Nutchbase • But, sadly maintained as a patch for a year or more – NUTCH-650 Hbase integration • Brought about some interesting thoughts – If storage can be abstracted, what about? • Messaging layer (JMS Nutch?) • Parsing? • Indexing (Solr, Lucene, you-name-it)
- 30. Post Nutch 1.0 • Nutch 1.0 release was a true “1.”-oh! – Included production features – Those using it were happy, b/c they had bought into the model – Useable, tuneable • But, how do we get to Nutch 2.0?
- 31. A few things happen in parallel • 1.1 Release? – I had some free time and was willing to RM a Nutch 1.1 release to get things going • Dogacan, Enis, Julien and Andrzej got interested in moving Nutchbase forward – But took it to the next level…we’ll get back to this • We elected a new committer • Julien Nioche • Patches that had sat for years now got committed
- 32. Oh, and Nutch became TLP • Grabbed folks that were active in Nutch community • Decided to move forward with Nutch/HBase as the de-facto platform – No need to maintain home-grown storage formats – And, take it to the next level, to ORM-ness • Decided to make Nutch a “delegator” rather than a workhorse – In other words…
- 33. Nutch2: “Delegator” • Indexing/Querying? – Solr has a lot of interest and does tons of work in this area: let’s use it instead of vanilla Lucene • Parsing? – Tika: ditto • Storage – Let’s use the ORM layer that some of the Nutch committers were working on
- 34. Enter Gora: “that ORM technology” • Initially baked up at Github • Decided to move to the Incubator in Sept 2010 – I was contacted and asked to champion the effort • What is Gora? – Uses Apache Avro to specify objects and their schema – ORM middleware takes Avro specs, generates Java code – plugs for HBase, Cassandra, in-memory SQL store, etc.
- 35. Nutch and Gora • Throw out all code in Nutch that had to do with Writeable interface – Generated now by “Web Page” schema in Gora – Web Page is canonical Nutch object for storage • Parse text, parse data, etc. • No more web-db, crawl-db, etc.
- 36. Out with the old… • Throw out Nutch webapp – Solr provides REST-ful services to get at metadata/index – We’ll add the REST (pun) for storage/etc. • Throw out Lucene code • Slowly trash existing Nutch parsers
- 37. In with the new • Get rid of webapp – Nutch 2.x has seen contributions of REST web services for full crawl cycle, storage I/F • Delegate indexing to Solr – Nutch 1.x first appearance of SolrIndexer and Nutch Solr schema • Delegate parsing to Tika – Nutch 1.1 first appearance of parse-tika – Have been decommissioning existing parsers • Suggested improvements to Tika during this process
- 39. Learning from our mistakes • Maintenance – Checking in jars made the Nutch checkout huge (even of just the “source”) • Now using Ivy to manage dependencies – Patches sitting? • Not on my watch! Encouragement to find and commit patches that have been sitting for a while, or simply disposition them – People want to use Nutch code as “dep” • Build now includes ability for RM to push to Maven Central NOTE: CHRIS’S OPINION SLIDE
- 40. Learning from our mistakes • Community – Folks contributing patches? • Make em’ a committer – Folks providing good testing results? • Make em’ a committer – Folks making good documentation? • Make em’ a committer – It’s the sign of a healthy Apache project if new committers (and members) are being elected NOTE: CHRIS’S OPINION SLIDE
- 41. Learning from our mistakes • Configuration of Nutch is hard – It still is – Getting easier though – Anyone have any great ideas or patches to integrate with a DI framework? – Things like GORA, Solr, etc, are making this easier • Providing flexible service interfaces beyond Java APIs – Existing work on NUTCH-932, NUTCH-931 and NUTCH-880 is just the beginning
- 42. Interesting work going on • I taught a class on Search Engines this past summer • Some neat projects that I’m working with my students to contribute back to Apache – Implementation of Authority/Hub scoring – Deduplication improvements – Clustering plugin improvements – Work to improve Nutch-Solr-Drupal integration
- 43. Wrapup • Nutch has seen tremendous highs and lows over years – We’re still kicking • The newest version of Nutch (2.0) will have a vastly slimmed down footprint, and will use existing successful frameworks for heavy lifting – Solr, Tika, Gora, Hadoop • If you’re interested in our dev, check us out at http://nutch.apache.org
- 44. Alright, I’ll shut up now • Any questions? • THANK YOU! – [email protected] – @chrismattmann on Twitter
- 45. Acknowledgements • Nutch team • Some material inspired from Andrzej Bialecki’s talks here • OODT team at JPL