Lessons learned processing 70 billion data points a day using the hybrid cloud
Download as PPTX, PDF0 likes515 views

The document discusses NetApp's Active IQ platform for predictive analytics in storage systems, processing 70 billion data points daily. It outlines data management challenges in Hadoop, emphasizing the need for hybrid cloud architecture, NFS benefits, and a unified data lake to enhance performance and manageability. Key solutions include disaggregating compute from storage and leveraging in-place analytics for efficient data handling and lower total cost of ownership.























Lessons learned processing 70 billion data points a day using the hybrid cloud
- 1. Lessons learned processing 70 billion data points a day © 2018 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL --- Shankar Pasupathy Pranoop Erasani Technical Director Senior Technical Director Active IQ Data Science ONTAP NFS DataWorks Summit, San Jose June 2018
- 2. Agenda o What is Active IQ ? o 5 Data Management challenges with Hadoop o Hybrid cloud analytics architecture o Why NFS for Hadoop and AI ? o Performance and Scale of shared storage o NetApp’s In-Place Analytics Module o Summary © 2018 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL ---2
- 3. What is Active IQ ? © 2018 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL ---3 Active IQ platform AutoSupport (ASUP) • Configuration data • Performance counters • System logs
- 4. Active IQ: Predictive Analytics for NetApp storage systems 4 © 2018 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL --- Use cases Active IQ Predict disk drive failures Predict outages, performance problems Detect misconfigured storage (ARS) Automate problem diagnosis Use community wisdom to guide best practices Guide future product design
- 5. The NetApp Active IQ Ecosystem 5 © 2018 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL --- Data growth: 2x every 8 months 300,000 Storage controllers 70 Billion Data points processed daily 135 TB Data processed per month 3.7 PB Data lake Large # of Users 6+ Hadoop clusters
- 6. 5 data management challenges 1. Storage for Hadoop doubling year over year 2. The need to use the cloud in a cost-effective and secure manner 3. Separate storage architectures for AI and Hadoop 4. Multiple sources of data, each with their own access rights 5. The need for data provenance © 2018 NetApp, Inc. All rights reserved. — NETAPP CONFIDENTIAL —6
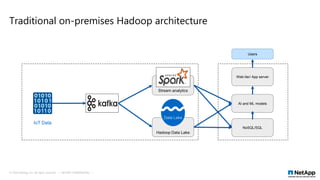
- 7. Traditional on-premises Hadoop architecture Stream analytics Users Hadoop Data Lake NoSQL/SQL AI and ML models Web tier/ App server IoT Data Data Lake © 2018 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL ---
- 8. Challenge 1: Problems caused by storage growth o Poor utilization of compute o Disk failures at scale o Too many copies of the data o Tiers of storage and QoS o (HDFS 3.0) © 2018 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL --- Batch processing QA Realtime cluster CPU Disks CPU Disks CPU Disks Switch 3x data copies POC 8
- 9. Our solution: Separation of compute and storage © 2018 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL ---9 Not a new idea LADDIS 2009, Usenix 2012, IEEE Big Data 2013, IDC 2018 Hadoop in the cloud Rack space and throughput Modern all flash shared storage ~ 25 GB/s in 4U (4PB effective space) Need 350 traditional DAS servers for 25 GB/s aggregate bandwidth Network Latency 40 Gbit/Ethernet in 2018: 1 – 5 microseconds iWARP/RDMA
- 10. Cloud Freedom from IT – ease of use Remove operations pain (Hadoop as a service) Provision compute instantly Cost effective ? Inhibitors Security and fear: “Data is my most valuable asset” Regulations – GDPR, HIPAA, … Prohibitive cost for storage (60 PB of data ?) Cloud lock in and egress costs Challenge 2: Hadoop on-premises vs the cloud ? © 2018 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL ---10
- 11. Our solution: Cloud connected storage © 2018 NetApp, Inc. All rights reserved. NetApp Internal Use Efficient Data Copy NetApp Storage Hadoop On-premise NetApp Cloud Volumes Google Latency: 1-2 ms Bandwidth: Links x 10 Gbps
- 12. Choosing Hadoop in the cloud vs on-premises 12 © 2018 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL --- NetApp Data Fabric On-premise 24x7 real-time processing, high throughput jobs AWS/Azure/GCP QA, POCs, AI/ML Bursty workloads | Choose your Cloud Unified Data Lake Cloud Connected Storage Secure IoT Data 24x7 Edge Efficient
- 13. HDFS Sequential I/O Throughput oriented Large files AI Needs Random I/O IOPS oriented Shared file system for distributed training Challenge 3: What is the right storage architecture for AI ? 13 © 2018 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL ---
- 14. Tiered storage (SSD, SATA) Storage QoS for different workloads Ability to rapidly ”clone” data for QA In built compression Triple parity RAID hides disk failures For >4TB SATA disks Our solution: Build a unified, shared Datalake © 2018 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL ---14 Active IQ Unified Data Lake NFS
- 15. Active IQ analytics architecture using the hybrid cloud and NFS storage 12x reduction in storage space, 30x improvement in performance, 3x reduction in compute nodes In-place analytics module NFS On Premises HDInsight In-place analytics module Databricks/EMR In-place analytics module Cloud Connected Storage Archive Data Lake Unified Data Lake Active IQ Telemetry Data Cluster NetApp Cloud Volumes In the CloudEdge NetApp Data Fabric In-place analytics module © 2018 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL ---
- 16. Why NFS for Hadoop and AI ? 1. Performance 2. Scale 3. Manageability © 2018 NetApp, Inc. All rights reserved. NetApp Proprietary – Limited Use Only16
- 17. NFS Performance: High throughput at Low latency 17 © 2018 NetApp, Inc. All Rights Reserved≈ 500µs latency 25GB/s throughput 11.4M IOPS 300GB/s throughput 1M IOPS 24-node Cluster
- 18. NFS Scale: PB-scale data lake with high file count 18 © 2018 NetApp, Inc. All Rights Reserved≈ 20PB size 400B files Tested 10 nodes 172PB size 47T files Supported 24 nodes
- 19. NFS Manageability: NetApp In-Place Analytics Module © 2018 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL ---19 In-Place Analytics Module HDFS Amazon S3 GlusterFS Azure NFS Batch MapReduce Interactive TEZ Online HBase In-Memory Spark Graph Giraph YARN (Cluster Resource Management) FileSystem (Interfaces to interact with storage systems) (Computation Framework) Available as a drop-in JAR file Integrated with Hortonworks Ambari NFS Filesystem Implementation Buffered Input and Output stream 14 of 22 NFSv3 Operations Simplified configuration Set fs.defaultFS to NFS path (e.g. IP:/path) Tunables configured via a JSON file Integrated with LDAP directory services Roadmap Ranger, Kerberos and HCFS
- 20. Additional Benefits of NetApp In-Place Analytics Module © 2018 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL ---20 1. No changes to Hadoop applications Analytics Jobs run seamlessly over NFS 2. No copy sprawl Primary data copy is the data lake; Moreover,1x copy vs 3x HDFS copies 3. Leverage Data Management Snapshots, Data protection copies and Clones for point-in-time analytics 4. Optimized for streaming throughput NFS Multi-pathing, High concurrency, Prefetching, Data and Metadata caching 5. NFS and HDFS could co-exist E.g. HDFS as primary and NFS as secondary or vice-versa
- 21. 5 data management challenges 1. Storage for Hadoop doubling year over year 2. The need to use the cloud in a cost-effective and secure manner 3. Separate storage architectures for AI and Hadoop 4. Multiple sources of data, each with their own access rights 5. The need for data provenance © 2018 NetApp, Inc. All rights reserved. — NETAPP CONFIDENTIAL —21
- 22. Summary 1. Disaggregate compute from storage for analytics 2. Unified data lake for ease of management and Lower TCO 3. Hybrid cloud architecture for access to cloud innovation © 2018 NetApp, Inc. All rights reserved. — NETAPP CONFIDENTIAL —22
- 23. © 2018 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL ---23 Thank You
- 24. 4. NFS TCO: Ease of data lifecycle management at scale After • Automatic tiering • Zero-touch management • Preserves file system semantics • Preserves storage efficiencies • Data encrypted in-flight • 1 copy vs 3 HDFS copies On-PremisesFootprint FabricPool Inactive Data Object Storage Performance Tier CapacityTier 80% Before Active Data Inactive Data 24 © 2018 NetApp, Inc. All rights reserved. NETAPP CONFIDENTIAL