Lightning-Fast Analytics for Workday Transactional Data with Pavel Hardak and Ned Borisov
3 likes1,191 views

The document details a presentation about Workday and its Prism Analytics platform for managing transactional data, highlighting business challenges like concurrency, reliability, security, and scalability. It explains the high-level architecture, including the integration of Apache Spark for data processing and query execution, which enhances performance and user experience. Future plans focus on improving query latency, integrating with cloud services, and ensuring better scalability and concurrency.































Lightning-Fast Analytics for Workday Transactional Data with Pavel Hardak and Ned Borisov
- 1. Pavel Hardak, Dir Product (Workday) Ned Borisov (Ph.D), Sr Eng Mgr (Workday) Lightning-Fast Analytics for Workday Transactional Data #ExpSAIS18
- 2. Agenda • Workday (Pavel H) – Introduction to Workday – Business challenges – Platform for Transactional Apps • Prism Analytics (Ned B) – High Level Architecture – Functional Modules – Problems encountered • Wrap-up (Pavel H) 2#ExpSAIS18
- 3. Workday • Pure SaaS company (founded in 2005) • Enterprise cloud apps – HCM and Finances – Named as “Leader” in Gartner Magic Quadrants • 2200+ customers, 175+ of Fortune 500 – Revenue: $2.1B, 36% YoY • 8600+ employees worldwide – #7 in FORTUNE "100 Best Companies to Work For” – Pleasanton (HQ), San Mateo, San Francisco – Boulder (CO), Dublin (Ireland), Victoria (BC), … 3#ExpSAIS18
- 5. Continuous Innovation in Cloud 5#ExpSAIS18
- 6. 6#ExpSAIS18
- 7. Enterprise SaaS Challenges • Concurrency – From small to huge companies - every ‘worker’ is Workday user • Reliability – All users add and change data, generating many transactions • Security – Customers trust us with very confidential and private information • Scalability – Import several years from the previous system(s) and keep growing • Speed – Everybody wants fast response time J 7#ExpSAIS18
- 8. Business Process Framework Object Data Model Reporting and Analytics Security Integration Cloud One Source for Data | One Security Model | One Experience | One Community Machine Learning One Platform #ExpSAIS18
- 9. Object Data Model One Source for Data | One Security Model | One Experience | One Community One Platform Object Data Model MetadataExtensibleDurable #ExpSAIS18
- 10. Reporting and Analytics One Source for Data | One Security Model | One Experience | One Community One Platform Reporting and Analytics Dashboards CollaborationDistribution
- 11. But we want more… • Import 3rd party data from external sources – Unknown schema, need validations and cleansing • Blend external data with Workday data – Self Service Data Preparation – Publish custom report sources – Leverage the same security paradigms • Data Discovery and Reporting – Visualize, slice and dice by any dimension – Perform faster than ever before 11#ExpSAIS18
- 12. 12#ExpSAIS18
- 13. Just add some … • Water (?) • Coffee (?) • Energy drink (?) • Apache Spark (!) 13#ExpSAIS18
- 14. Why Apache Spark • Wanted to standardize on ONE data processing technology which keeps evolving • Needed extensibility to handle diverse use cases • Scalability for on-disk views and in-memory processing • SQL processing is a HUGE plus #ExpSAIS18
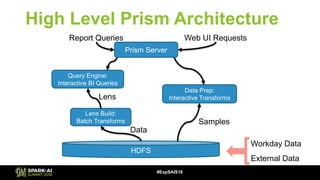
- 15. High Level Prism Architecture Report Queries Web UI Requests Data Prep: Interactive Transforms HDFS Workday Data External Data Samples #ExpSAIS18 Prism Server
- 16. Data Preparation • A dataset may import other datasets to transform them (think SQL View) • Transforms include: Filter, Join, Union, Group By, etc. • Example data are shown to help verify the transformation #ExpSAIS18
- 17. High Level Prism Architecture Report Queries Web UI Requests Data Prep: Interactive Transforms Lens Build: Batch Transforms HDFS Workday Data External Data Samples Data #ExpSAIS18 Prism Server
- 18. Lens Build Lens • Materializing all transforms • Columnar format with further split into small blocks Spark Jobs #ExpSAIS18
- 19. High Level Prism Architecture Report Queries Web UI Requests Query Engine: Interactive BI Queries Data Prep: Interactive Transforms Lens Build: Batch Transforms HDFS Workday Data External Data Samples Lens Data #ExpSAIS18 Prism Server
- 20. Query Engine • Analyst-driven Analysis • Drag & drop chart creation • Analyst defined computed fields • Quick measurement aggregates • Execution • Query Engine executes the queries • Interactive response is required #ExpSAIS18
- 21. High Level Prism Architecture Report Queries Web UI Requests Query Engine: Interactive BI Queries Data Prep: Interactive Transforms Lens Build: Batch Transforms HDFS Workday Data External Data Samples Lens Data #ExpSAIS18 Prism Server
- 22. Spark in Prism Architecture Prism Analytics launches and maintains lifecycle of three types of Spark Applications • Data Prep: a single (smaller) always-on Spark Application – executes dataset transformations over small samples of data • Lens Build: on-demand batch Application – one per Lens Build process – executes dataset transformations over full datasets • Query Engine: a single (larger) always-on Application – executes reporting queries over Lens data – caches columns of Lenses in memory #ExpSAIS18
- 23. Query Engine & Spark Query Engine Prism Spark Server Spark Driver Prism Server Data Prep . . . Spark Executor Spark Executor Spark Executor Spark Executor Spark Executor Spark Executor Spark Executor Spark Executor Spark Executor Spark Executor Spark Executor Spark Executor #ExpSAIS18
- 24. Notable Observations • Memory Allocation Strategy • Row Level Security #ExpSAIS18
- 25. Memory Allocation Strategy • Executors • Driver Column Data Cache 30% Execution 60% 10% Buffer Accumulators 20% Streaming 60% 20% Buffer Executor JVM Driver JVM #ExpSAIS18 à 20% faster queries
- 26. Row-Level Security • Implemented as a dimension predicate. For example: • In-List for supervisory_org could be very large • More than one In-List • Complex list values (e.g. nested conjunctions) SELECT employee, SUM(quantity) FROM Employee_Stock_Grants WHERE supervisory_org IN (org1, org33, org_508) GROUP BY employee; #ExpSAIS18
- 27. Scenario Details • Customer Use Case – Predicates with 10+ In-Lists – Values between 6K and 12K – Additional mix of conjunctions and disjunctions • The Same Query With Security = 100X Without Security #ExpSAIS18
- 28. Analysis • Finding 1 – Parsing, planning and optimizing was taking ~27 seconds – We did it 4 times • Finding 2 – Major cause is the number of times the Catalyst expressions (In and InSet) and their arguments were being traversed and copied during plan analysis and optimization. – Minor cause is the amount of time spent in serializing Scala’s TrieSet when shipping the plan to executors #ExpSAIS18
- 29. Solution • Custom InSet-Like expressions (case classes) – Hide the large literals sets through a curried-argument – Resulted in queries going from 27 sec to 4 sec. • Further Optimizations – Our InSet-Like expression did not materialize the target in-sets until after the plan was de-serialized on the executors – Resulted in improvement from 4 sec to 2 sec. #ExpSAIS18
- 30. Future Plans • Better query latency for big datasets • Deeper integration with reports and apps • Integration with Kubernetes and AWS • Improved scalability and concurrency • Achieve ‘Zero DownTime’ …and much more I can not share here J 30#ExpSAIS18
- 31. Questions? • IF ( you are looking for … Great work culture && Technology challenges && Lots of fun and perks ) • THEN Come to work with us!!! workday.com/jobs 31#ExpSAIS18
- 32. More Info • Building a modern data discovery and BI platform using Apache Spark and Catalyst by Kevin Beyer • Data Preparation in Workday Prism Analytics: Solving Complex Problems the Workday Way by Jianneng Li • Exploring Workday’s Architecture by James Pasley 32#ExpSAIS18