Load Balancing In Distributed Computing
Download as PPTX, PDF18 likes11,960 views

The document discusses load balancing strategies in distributed computing systems, emphasizing their importance for enhancing processing speed and overall system performance. It covers static and dynamic load balancing approaches, detailing various algorithms and their characteristics, including optimal and sub-optimal mechanisms. The conclusion highlights the ongoing research in load balancing due to the increasing demand for efficient computing in heterogeneous environments.



















Load Balancing In Distributed Computing
- 1. THE STUDY ON LOAD BALANCING STRATEGIES IN DISTRIBUTED COMPUTING SYSTEM
- 2. INTRODUCTION • Processing speed of a system is always highly intended. • Distributed computing system provides high performance environment that are able to provide huge processing power. • In distributed computing thousand of processors can be connected either by wide area network or across a large number of systems which consists of cheap and easily available autonomous systems like workstations or PCs. • The distribution of loads to the processing elements is simply called the load balancing. • The goal of the load balancing algorithms is to maintain the load to each processing element such that all the processing elements become neither overloaded nor idle that means each processing element ideally has equal load at any moment of time during execution to obtain the maximum performance (minimum execution time) of the system.
- 3. LOAD BALANCING • Load balancing is the way of distributing load units (jobs or tasks) across a set of processors which are connected to a network which may be distributed across the globe. • The excess load or remaining unexecuted load from a processor is migrated to other processors which have load below the threshold load. • Threshold load is such an amount of load to a processor that any load may come further to that processor. • By load balancing strategy it is possible to make every processor equally busy and to finish the works approximately at the same time.
- 4. LOAD BALANCING OPERATION A Load Balancing Operation is defined by three rules:
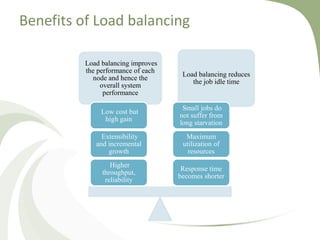
- 5. Benefits of Load balancing Load balancing improves the performance of each node and hence the overall system performance Load balancing reduces the job idle time Response time becomes shorter Maximum utilization of resources Small jobs do not suffer from long starvation Higher throughput, reliability Extensibility and incremental growth Low cost but high gain
- 6. Quality of a load balancing algorithm • Quality of a load balancing algorithm is dependent on two factors. • Firstly number of steps that are needed to get a balanced state. • Secondly the extent of load that moves over the link to which nodes are connected.
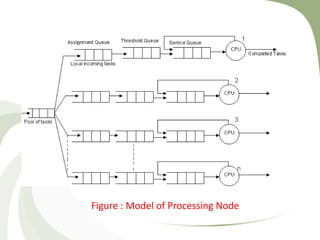
- 7. Static Load Balancing • In static algorithm the processes are assigned to the processors at the compile time according to the performance of the nodes. • Once the processes are assigned, no change or reassignment is possible at the run time. • Number of jobs in each node is fixed in static load balancing algorithm. Static algorithms do not collect any information about the nodes . • The assignment of jobs is done to the processing nodes on the basis of the following factors: incoming time, extent of resource needed, mean execution time and inter-process communications. • Since these factors should be measured before the assignment, this is why static load balance is also called probabilistic algorithm.
- 8. Figure : Model of Processing Node
- 9. Sub classes of SLB The static load balancing algorithms can be divided into two sub classes: •Optimal static load balancing. •Sub optimal static load balancing. Optimal Static Load Balancing Algorithms. •If all the information and resources related to a system are known optimal static load balancing can be done. •It is possible to increase throughput of a system and to maximize the use of the resources by optimal load balancing algorithm.
- 10. Sub-Optimal Static Load Balancing Algorithm •Sub-optimal load balancing algorithm will be mandatory for some applications when optimal solution is not found. •The thumb-rule and heuristics methods are important for sub-optimal algorithm.
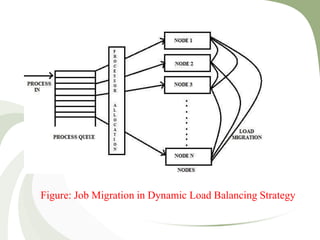
- 11. Dynamic Load Balancing • In dynamic load balancing algorithm assignment of jobs is done at the runtime. • In DLB jobs are reassigned at the runtime depending upon the situation that is the load will be transferred from heavily loaded nodes to the lightly loaded nodes. • In this case communication over heads occur and becomes more when number of processors increase. • In dynamic load balancing no decision is taken until the process gets execution.
- 12. • This strategy collects the information about the system state and about the job information. • As more information is collected by an algorithm in a short time, potentially the algorithm can make better decision. • Dynamic load balancing is mostly considered in heterogeneous system because it consists of nodes with different speeds, different communication link speeds, different memory sizes, and variable external loads due to the multiple.
- 13. Figure: Job Migration in Dynamic Load Balancing Strategy
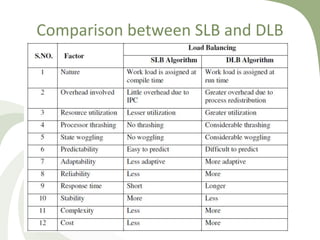
- 14. Comparison between SLB and DLB
- 15. COMPARISON of SOME DYNAMIC LOAD BALANCING ALGORITHMS 1. Nearest Neighbour Algorithm: With nearest neighbour algorithm each processor considers only its immediate neighbour processors to perform load balancing operations. A processor takes the balancing decision depending on the load it has and the load information to its immediate neighbours. 2. Random (RAND) Algorithm: As soon as a workload (greater than threshold load) is generated in a processor, it is migrated to a randomly selected neighbour. It does not check state information of anode. This algorithm neither maintains any local load information nor sends any load information to other processors . Furthermore, it is simple to design and easy to implement. But it causes considerable communication overheads due to the random selection of lightly loaded processor to the nearest neighbours.
- 16. 3. Adaptive Contracting with Neighbor (ACWN):As soon as the workload is newly generated, it is migrated to the least loaded nearest neighbor processor. The load accepting processor keeps the load in its local heap. If the load in its heap is less than to its threshold load then no problem otherwise it sends the load to the neighbor processor which has load below the threshold load. So, ACWN does require maintaining the local load information and also the load information of the neighbors for exchanging the load periodically. Hence, RAND is different form the ACWN in a respect that ACWN always finds the target node which is least loaded in neighbors. 4. CYCLIC Algorithm: This is the outcome of RAND algorithm after slight modification. The workload is assigned to a remote system in a cyclic fashion. This algorithm remembers always the last system to which a process was sent.
- 17. 5. PROBABILISTIC: Each node keeps a load vector including the load of a subset of nodes. The first half of the load vector holding also the local load is sent periodically to a randomly selected node. Thus information is revised in this way and the information may be spread in the network without broadcasting. However, the quality of this algorithm is not ideal, its extensibility is poor and insertion is delayed. 6. Prioritized Random (PRAND) Algorithm: Modification is done on RAND and ACWN for the non-uniform workload to get prioritized RAND (PRAND) and prioritized ACWN (PACWN) respectively. In these algorithms the work loads are assigned index numbers on the basis of the weight of their heaps. PRAND is similar to RAND except that it selects the second largest weighted load from the heap and transfers it to a randomly selected neighbor. On the other hand, PACWN selects the second largest weighted workload and transfer it to the least loaded neighbor .
- 18. 7. THRESHOLD and LEAST: They both use a partial knowledge obtained by message exchanges. A node is randomly selected for accepting a migrated load in THRESHOLD. If the load is below threshold load, the load accepted by there. Otherwise, polling is repeated with another node for finding appropriate node for transferring the load. After a maximum number of attempts if no proper recipient has been reported, the process is executed locally. LEAST is an instant of THRESHOLD and after polling least loaded machine is chosen for receiving the migrated load. THRESHOLD and LEAST have good performance and are of simple in nature. Furthermore, up-to-date load values are used by these algorithms. 8. RECEPTION: In this algorithm, nodes having below the threshold load find the overloaded node by random polling for migrating load from overloaded node.
- 19. 9. Centralized Information and Centralized Decision: CENTRAL is a subclass of this algorithm. When a heavily loaded node wants to migrate a job, it requests a server for a lightly loaded node. Every node in the system informs the server machine whether a lightly loaded node is available or not. 10. Centralized Information and Distributed Decision: In GLOBAL, collection of information is centralized while decision making is distributed. The load situation on the nodes is broadcasted by the server. Through this information an overloaded processor finds the lightly loaded node from its load vector without going through the server.
- 20. 11. Distributed information and Distributed Decision: Each node in OFFER broadcasts its load situation periodically and each node keeps a global load vector. Performance of this algorithm is poor. 12. RADIO: In RADIO, both the information and decision are distributed and there is no broadcasting without compulsion. In this algorithm, a distributed list consisting of lightly loaded nodes in which each machine is aware of its successor and predecessor. Furthermore, each node is aware of the head of the available list that is called manager. The migration of a process from a heavily loaded node to the lightly loaded node is done directly or indirectly through the manager.
- 21. 13. The Shortest Expected Delay (SED) Strategy: These strategy efforts to minimize the expected delay of each job completion so the destination node will be selected in such a way that the delay becomes minimal. This is a greedy approach in which each job does according to its best interest and joins the queue which can minimize the expected delay of completion. 14. The Never Queue (NQ) Strategy: NQ policy is a separable strategy in which the sending server estimates the cost of sending a job to each final destination or a subset of final destinations and the job is placed on the server with minimal cost . This algorithm always places a job to a fastest available server. 15. Greedy Throughput (GT) Strategy: This strategy is different from SED and NQ strategies. GT strategy deals with the throughput of the system that is the number of jobs completed per unit time would be maximum before the arrival of new job instead of maximizing only the throughput rate at the instant of balancing. This is why it is called Greedy Throughput (GT) policy.
- 23. CONCLUSION • we studied the load balancing strategies lucidly in detail. • Load balancing in distributed systems is the most thrust area in research today as the demand of heterogeneous computing due to the wide use of internet. • More efficient load balancing algorithm more is the performance of the computing system. • Finally, we studied some important dynamic load balancing algorithms and made their comparison to focus their importance in different situations. • There exists no absolutely perfect balancing algorithm but one can use depending one the need.