



















































M4L18 Unsupervised and Semi-Supervised Learning - Slides v2.pdf
- 1. Introduction
- 2. Spectrum of Low-Labeled Learning Supervised Learning ⬣ Train Input: 𝑋, 𝑌 ⬣ Learning output: 𝑓 ∶ 𝑋 → 𝑌, 𝑃(𝑦|𝑥) ⬣ e.g. classification Sheep Dog Cat Lion Giraffe Unsupervised Learning ⬣ Input: 𝑋 ⬣ Learning output: 𝑃 𝑥 ⬣ Example: Clustering, density estimation, etc. Less Labels Semi-Supervised Learning (10+ labels/category + unlabeled data) Few-Shot Learning (1-5/category) (no unlabeled data) Self-Supervised Learning (No labels for representation learning) These are just common settings, can be combined! ⬣ E.g. semi-supervised few-shot learning
- 3. What to Learn? Traditional unsupervised learning methods: Similar in deep learning, but from neural network/learning perspective Modeling 𝑷 𝒙 Comparing/ Grouping Representation Learning Principal Component Analysis Clustering Density estimation Almost all deep learning! Metric learning & clustering Deep Generative Models
- 4. Dealing with Unlabeled Data Labeled data Cross Entropy Unlabeled data ? Several considerations: ⬣ Loss function (especially for unlabeled data) ⬣ Optimization / Training Procedure ⬣ Architecture ⬣ Transfer learning?
- 5. Common Key Ideas Pseudo-labeling for Unlabeled Data (Semi-Supervised Learning) Figures Adapted from: Sohn et al., FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence Cross-View/Augmentation & Consistency Surrogate Tasks (Self-Supervised Learning) Meta-Learning (Few-Shot Learning) Figure from Meta-Learning: from Few-Shot Learning to Rapid Reinforcement Learning, ICML 2019 Tutorial. Gidaris et al., Unsupervised Representation Learning by Predicting Image Rotations ⬣ Cross- entropy ⬣ (Soft) Knowledge Distillation
- 7. Semi-Supervised Learning Key question: Can we overcome small amount of labeled data using unlabeled data? It is often much cheaper (in terms of cost, time, etc.) to get large-scale unlabeled datasets Somewhat Few Labeled Lots of Unlabeled
- 8. Ideal Performance of Semi-Supervised Learning Past Work Recent Methods (sometimes) It is often much cheaper (in terms of cost, time, etc.) to get large-scale unlabeled datasets Ideally would like to improve performance all the way to highly-labeled case
- 9. An Old Idea: Predictions of Multiple Views ⬣ Simple idea: Learn model on labeled data, make predictions on unlabeled data, add as new training data, repeat ⬣ Combine idea with co-training: Predicting across multiple views ⬣ Avrim & Mitchell, Combining Labeled and Unlabeled Data with Co- Training, 1998! Somewhat Few Labeled Lots of Unlabeled
- 10. Pseudo-Labeling Sohn et al., FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence Pseudo-labeling for Unlabeled Normal Training for Labeled Data Cross Entropy Somewhat Few Labeled Lots of Unlabeled
- 11. Pseudo-Labeling in Practice Sohn et al., FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence Cross Entropy (Labeled Data) Prediction (Pseudo-Label) Labeled Examples Unlabeled Examples Cross Entropy (Pseudo-Labeled Data) Weakly Augmented Weakly Augmented Strongly Augmented
- 12. Details and Hyper-Parameters Several details: ⬣ Labeled batch size of 64 ⬣ Unlabeled batch size of 448 ⬣ Key is large batch size ⬣ Confidence threshold of 0.95 ⬣ Cosine learning rate schedule ⬣ Differs for more complex datasets like ImageNet ⬣ Batch sizes 1024/5120 (!) ⬣ Confidence threshold 0.7 ⬣ Inference with exponential moving average (EMA) of weights Sohn et al., FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
- 13. Results Sohn et al., FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
- 14. Scaling Semi-Supervised Learning Sohn et al., FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
- 15. Other Methods Large number of methods: ⬣ MixMatch/ReMixMatch (Berthelot et al.): More complex variations prior to FixMatch ⬣ Temperature scaling and entropy minimization ⬣ Multiple augmentations and ensembling to improve pseudo-labels ⬣ Virtual Adversarial Training (Miyato et al.): Augmentation through adversarial examples (via backprop) ⬣ Mean Teacher – Student/teaching distillation consistency method (Tarveinen et al.) with exponential moving average Miyatio et al., Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning Berthelot et al., MixMatch: A Holistic Approach to Semi-Supervised Learning Berthelot et al., ReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring Tarveinen et al., Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning
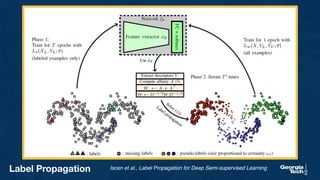
- 16. Label Propagation Iscen et al., Label Propagation for Deep Semi-supervised Learning
- 17. Summary Unlabeled data can be used successfully to improve supervised learning Methods are relatively simple: ⬣ Data augmentation ⬣ Pseudo-labeling ⬣ (Less necessary) Label Propagation Methods scale to large unlabeled sets: ⬣ Not clear how many labels each unlabeled data is “worth”
- 19. Few-Shot Learning Chen et al., A Closer Look at Few-Shot Learning Lots of Labels (Base categories) Very Few Labels (New categories)
- 20. Finetuning Baseline Chen et al., A Closer Look at Few-Shot Learning Dhillon et al., A Baseline for Few-Shot Image Classification Tian et al., Rethinking Few-Shot Image Classification: a Good Embedding Is All You Need? ⬣ Do what we always do: Fine-tuning ⬣ Train classifier on base classes ⬣ Optionally freeze feature extractor ⬣ Learn classifier weights for new classes using few amounts of labeled data (during “query” time) ⬣ Surprisingly effective compared to more sophisticated approaches (Chen et al., Dhillon et al., Tian et al.)
- 21. Cosine Classifier Chen et al., A Closer Look at Few-Shot Learning https://en.wikipedia.org/wiki/Cosine_similarity We can use a cosine (similarity-based) classifier rather than fully connected linear layer
- 22. Cons of Normal Approach ⬣ The training we do on the base classes does not factor the task into account ⬣ No notion that we will be performing a bunch of N- way tests ⬣ Idea: simulate what we will see during test time
- 23. Meta-Training Set up a set of smaller tasks during training which simulates what we will be doing during testing: N-Way K-Shot Tasks ⬣ Can optionally pre-train features on held-out base classes Testing stage is now the same, but with new classes Meta-Train Meta-Test
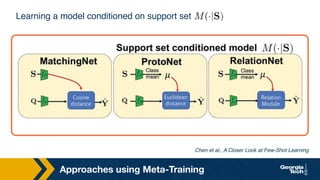
- 24. Approaches using Meta-Training Learning a model conditioned on support set Chen et al., A Closer Look at Few-Shot Learning
- 25. How to parametrize learning algorithms? Two approaches to defining a meta-learner: Take inspiration from a known learning algorithm kNN/kernel machine: Matching networks (Vinyals et al. 2016) Gaussian classifier: Prototypical Networks (Snell et al. 2017) Gradient Descent: Meta-Learner LSTM (Ravi & Larochelle, 2017) , Model-Agnostic Meta-Learning MAML (Finn et al. 2017) Derive it from a black box neural network MANN (Santoro et al. 2016) SNAIL (Mishra et al. 2018) 25 Meta-Learner Slide Credit: Hugo Larochelle
- 26. Learn gradient descent: Parameter initialization and update rules Output: Parameter initialization Meta-learner that decides how to update parameters Learn just an initialization and use normal gradient descent (MAML) Output: Just parameter initialization! We are using SGD 26 Slide Credit: Hugo Larochelle More Sophisticated Meta-Learning Approaches
- 27. 27 Meta-Learner LSTM Slide Credit: Hugo Larochelle
- 28. 28 Meta-Learner LSTM Slide Credit: Hugo Larochelle
- 29. 29 Meta-Learner LSTM Slide Credit: Hugo Larochelle
- 30. 30 Meta-Learner LSTM Slide Credit: Hugo Larochelle
- 31. 31 Meta-Learner LSTM Slide Credit: Hugo Larochelle
- 32. 32 Meta-Learner LSTM Slide Credit: Hugo Larochelle
- 33. 33 Model-Agnostic Meta-Learning (MAML) Slide Credit: Hugo Larochelle
- 34. 34 Slide Credit: Hugo Larochelle Model-Agnostic Meta-Learning (MAML) Slide Credit: Hugo Larochelle
- 35. 35 Slide Credit: Hugo Larochelle Model-Agnostic Meta-Learning (MAML)
- 36. 36 Comparison Slide Credit: Hugo Larochelle
- 38. Unsupervised Learning Density Estimation Classification Regression Clustering Dimensionality Reduction x y x y Discrete Continuous x c Discrete x z Continuous Supervised Learning Unsupervised Learning x p(x) On simplex
- 39. Spectrum of Low-Labeled Learning What can we do with no labels at all? Supervised Learning ⬣ Train Input: 𝑋, 𝑌 ⬣ Learning output: 𝑓 ∶ 𝑋 → 𝑌, 𝑃(𝑦|𝑥) ⬣ e.g. classification Sheep Dog Cat Lion Giraffe Unsupervised Learning ⬣ Input: 𝑋 ⬣ Learning output: 𝑃 𝑥 ⬣ Example: Clustering, density estimation, etc. Less Labels
- 40. Autoencoders Encoder Decoder Low dimensional embedding Minimize the difference (with MSE) Linear layers with reduced dimension or Conv-2d layers with stride Linear layers with increasing dimension or Conv-2d layers with bilinear upsampling
- 42. Clustering Assumption Clustering Assumption ⬣ High density region forms a cluster while low density region separate clusters which hold a coherent semantic meaning. We hope: DNN K-Means Original feature space Learned feature space (The assumption)
- 43. Deep Clustering The clustering assumption leads to good feature learning with a careful engineering to avoid: ⬣ Empty cluster ⬣ Trivial parameterization Caron et al., Deep Clustering for Unsupervised Learning of Visual Features
- 44. Surrogate Tasks There are a lot of other surrogate tasks! ⬣ Reconstruction ⬣ Rotate images, predict if image is rotated or not ⬣ Colorization ⬣ Relative image patch location (jigsaw) ⬣ Video: Next frame prediction ⬣ Instance Prediction ⬣ …
- 45. Colorization ⬣ Input: Grayscale image ⬣ Output: Color image ⬣ Objective function: MSE Zhang et al., Colorful Image Colorization
- 46. Jigsaw ⬣ Input: Image patches ⬣ Output: Prediction of discrete image patch location relative to center ⬣ Objective function: Cross-Entropy (classification) Doersch al., Unsupervised Visual Representation Learning by Context Prediction
- 47. Rotation Prediction ⬣ Input: Image with various rotations ⬣ Output: Prediction rotation amount ⬣ Objective function: Cross- Entropy (classification) Gidaris et al., Unsupervised Representation Learning by Predicting Image Rotations
- 48. Evaluation Gidaris et al., Unsupervised Representation Learning by Predicting Image Rotations ⬣ Train the model with a surrogate task ⬣ Extract the ConvNet (or encoder part) ⬣ Transfer to the actual task ⬣ Use it to initialize the model of another supervised learning task ⬣ Use it to extract features for learning a separate classifier (ex: NN or SVM) ⬣ Often classifier is limited to linear layer and features are frozen
- 49. Instance Discrimination Augmentation 1 Augmentation 2 Augmented Negative Examples Positive Example Key question: Where should the negatives come from? Considerations: ⬣ Efficiency (feature extraction) ⬣ Characteristics of negative examples Contrastive Loss: E.g. dot product (similarity) between augmentation 1 and positive & negative examples
- 50. Momentum Encoder He et al., Momentum Contrast for Unsupervised Visual Representation Learning
- 51. Memory Banks ⬣ We can use a queue that comes from the previous mini-batches to serve as negative examples ⬣ This means no extra feature extraction needed! ⬣ Feature may be stale (since the encoder weights have been updated) but still works Queue Pop Mini- Batch
- 52. Momentum Encoder He et al., Momentum Contrast for Unsupervised Visual Representation Learning
- 53. Results Unlabeled Examples Augmented Augmented Augmented He et al., Momentum Contrast for Unsupervised Visual Representation Learning ⬣ Linear layers learned from learned frozen encoder ⬣ Similar or even better results than supervised! ⬣ Features generalize to other tasks (object detection)
- 54. Large number of surrogate tasks and variations! ⬣ E.g. contrastive across image patches or context ⬣ Different types of loss functions and training regimes Two have become dominant as extremely effective: ⬣ Contrastive losses (e.g. instance discrimination with positive and negative instances) ⬣ Pseudo-labeling (hard pseudo-label) and knowledge distillation (soft teacher/student) Data augmentation is key ⬣ Methods tend to be sensitive to choice of augmentation Summary