Machine Learning in 5 Minutes— Classification
7 likes4,948 views

The document provides an overview of various classification algorithms in machine learning, including examples like spam filters and the sorting hat. It discusses techniques such as linear discriminants, logistic regression, support vector machines (SVMs), k-nearest neighbors (KNN), decision trees, and ensemble models, highlighting their advantages and disadvantages. Each method is described with a focus on its operational principles and use cases, emphasizing the importance of labeled data for training.








































Machine Learning in 5 Minutes— Classification
- 1. classification edition Machine Learning in 5 Minutes Brian Lange
- 2. hi, i’m a data scientist
- 4. popular examples -spam filters -the Sorting Hat
- 5. things to know - you need data labeled with the correct answers to “train” these algorithms before they work - feature = dimension = attribute of the data - class = category = Harry Potter house
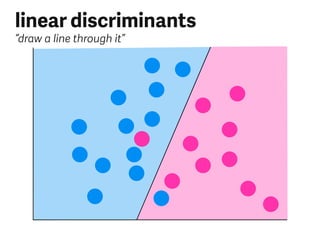
- 6. linear discriminants “draw a line through it”
- 7. linear discriminants “draw a line through it”
- 8. linear discriminants “draw a line through it”
- 9. linear discriminants “draw a line through it” 🎉
- 10. define what “shitty” means 6 wrong
- 11. define what “shitty” means 4 wrong
- 12. a map of shittiness to find the least shitty line shittiness slope intercept
- 13. probably don’t use these linear discriminants:
- 14. logistic regression “divide it with a log function”
- 15. logistic regression “divide it with a log function” 🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉 + gives you probabilities + the model is a formula + can “threshold” to make model more or less conservative 💩💩💩💩💩💩💩💩💩💩💩 - only works with linear decision boundaries
- 16. SVMs (support vector machines) “*advanced* draw a line through it” - better definition of “shitty” - lines can turn into non-linear shapes if you transform your data
- 19. 💩
- 21. 💩
- 25. SVMs (support vector machines) “*advanced* draw a line through it”
- 26. SVMs (support vector machines) “*advanced* draw a line through it” 🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉 works well on a lot of different shapes of data thanks to the kernel trick 💩💩💩💩💩💩💩💩💩💩💩 not super easy to explain to people can only kinda do probabilities
- 27. KNN (k-nearest neighbors) “what do similar cases look like?”
- 28. KNN (k-nearest neighbors) “what do similar cases look like?” k=1
- 29. KNN (k-nearest neighbors) “what do similar cases look like?” k=2
- 30. KNN (k-nearest neighbors) “what do similar cases look like?” k=1
- 31. KNN (k-nearest neighbors) “what do similar cases look like?” k=2
- 32. KNN (k-nearest neighbors) “what do similar cases look like?” k=3
- 33. KNN (k-nearest neighbors) “what do similar cases look like?”
- 34. KNN (k-nearest neighbors) “what do similar cases look like?” 🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉 + no training, adding new data is easy + you get to define “distance” 💩💩💩💩💩💩💩💩💩💩💩 - can be outlier-sensitive - you have to define “distance”
- 35. decision tree learners make a flow chart of it
- 36. decision tree learners make a flow chart of it x < 3? yes no 3
- 37. decision tree learners make a flow chart of it x < 3? yes no y < 4? yes no 3 4
- 38. decision tree learners make a flow chart of it x < 3? yes no y < 4? yes no x < 5? yes no 3 5 4
- 39. decision tree learners make a flow chart of it 🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉 + fit all kinds of arbitrary shapes + output is a clear set of conditionals 💩💩💩💩💩💩💩💩💩💩💩 - extremely prone to overfitting - have to rebuild when you get new data - no probability estimates
- 40. ensemble models make a bunch of models and combine them
- 41. ensemble models make a bunch of models and combine them 🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉 - don’t overfit as much as their component parts - Generally don’t require much parameter tweaking - If data doesn’t change very often, you can make them semi-online by just adding new trees - Can provide probabilities 💩💩💩💩💩💩💩💩💩💩💩 - Slower than their component parts (though if those are fast, it doesn’t matter)