Питер Мика "Making the web searchable"
1 like•732 views

The document discusses the evolution and importance of integrating semantic technologies into search mechanisms and online media. It covers various techniques for improving search relevance, such as RDF, RDFa, and microdata, highlighting their roles in data integration and enhancing user interaction. The document emphasizes the need for a shared understanding of data representation to optimize search experiences and behavior personalization.




































































Питер Мика "Making the web searchable"
- 1. Making the Web Searchable Peter Mika Senior Researcher and Data Architect Yahoo! Inc.
- 2. Agenda • Web Directions – Convergence of Search and Online Media • Semantic technologies (th)at work – Semantics for search • RDFa, microdata – Semantics for data integration • RDF, OWL, SPARQL • Take home: use what works! -2-
- 3. More than just ten blue links
- 4. It used to be pretty simple… -4-
- 5. Yahoo! today is a global network of online media sites -5-
- 6. ... with search as an important entry point to content Points of Faceted interest in Information search for Information box with Vienna, from the Shopping content from and Austria Knowledgeresults links to Yahoo! Graph Travel Since Aug, 2010, regular search results are Powered by Bing -6-
- 7. Conversely, online media as an entry point to search Hovering over an underlined phrase triggers a search for related news items. -7-
- 8. Aggregation across space: hyperlocal pages Hyperlocal: showing content from across Yahoo that is relevant to a particular neighbourhood. -8-
- 9. Aggregation across entity types: special events -9-
- 10. Personalization Yahoo s Content Optimization Relevance Engine (CORE) technology uses machine learning to predict click behavior based on user profile Display advertizing is also personalized by default. Users can opt-out of behavioral targeting through AdChoices. - 10 -
- 11. Show related content Contextualization Social discovery: connect with friends watching the same - 11 -
- 12. Convergence of search and online media • Complex answers in search – Using structured data, not just text – Search over owned content and the best of the Web • Aggregation – Content aggregation around events, persons, other entities – From creating topic pages to creating entire new websites • Personalization and contextualization – Understand user interests at a fine grained level – Build and carry user profiles across search and media • Common to these is a need for a more advanced understanding of the Web and our content - 12 -
- 13. Semantic technologies for Search
- 14. Search is really fast, without necessarily being intelligent - 14 -
- 15. State of Search • Improvements in search are harder and harder to come by – Machine learning using hundreds of signals • From text to the web graph – Heavy investment in computational power • e.g. real-time indexing and instant search • Remaining challenges are not computational, but in modeling human understanding – A machine is intelligent if it reasons and acts the way we would – But could Watson explain why the answer is Toronto? • How do we teach the computer about our world? – How do we give meaning to documents and data? - 15 -
- 16. Not just search… - 16 -
- 17. What it s like to be a machine? Roi Blanco - 17 -
- 18. What it s like to be a machine? ë✜Θ♬♬ţğ√∞ñ§®ÇĤĪ✜★¤♬☐✓✓ ţğ★¤✜èééééñ u✪✚✜ΔΤΟŨŸÏĞÊϖυτρ℠≠⅛⌫¤Γ ≠=⅚©§★✓♪ΒΓΕññ¤℠ ¢✖Γ♫⅜ ⏎↵⏏v☐ģğğğμλκσςτn nnnu⏎ñ⌥°¶§ΥΦΦΦ✗✕☐vuwwwww ë✜Θ♬♬ţğ - 18 -
- 19. If machines are dumb, how to make their job easier? • HTML is intended for human consumption – A mix of text, data and styling • Let s make it easier to process for machines – Languages to publish data in HTML • Agree between publishers and search engines on the meaning of certain symbols (ontologies) • e.g. ⏎⅙¥ means that this page describes a Person – Annotate HTML pages using these symbols – (This is just an example… the actual markup is human readable) • For data in particular, agree on what the types of objects are in the world, and what their attributes are – e.g. between §℗ and §⌥⌘ is the age of the Person • Leverage this understanding for more precise matching and ranking - 19 -
- 20. Semantic Web • Publish information in a way that is easier to process for machines • Web of Data instead of Web of Documents • Two main architectural challenges – A common format for sharing data – Sharing the meaning of data • Through social means (shared schemas) • By using powerful schema languages • Semantic Web standards from W3C – Languages (RDF, OWL, RIF) – Serializations (RDF/XML, RDFa) – Protocols (SPARQL, HTTP) • Semantic Web research into knowledge representation and reasoning, data integration, data quality and many other topics • Community efforts to publish data and develop schemas - 20 -
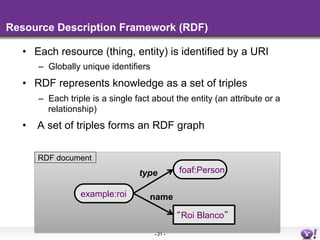
- 21. Resource Description Framework (RDF) • Each resource (thing, entity) is identified by a URI – Globally unique identifiers • RDF represents knowledge as a set of triples – Each triple is a single fact about the entity (an attribute or a relationship) • A set of triples forms an RDF graph RDF document type foaf:Person example:roi name Roi Blanco - 21 -
- 22. Linking across the Web Roi s homepage Friend-of-a-Friend ontology type example:roi foaf:Person name Roi Blanco knows sameAs Yahoo! s website type worksWith #roi2 #peter email [email protected] - 22 -
- 23. History of metadata in HTML • 1995: HTML meta tags • 1998: RDF/XML – RDF/XML in HTML – RDF linked from HTML • 2003: Web 2.0 – Tagging, machine tags – Microformats • 2005: eRDF • 2008: RDFa 1.0 • 2011: RDFa 1.1, Microdata - 23 -
- 24. HTML meta tags <HTML> <HEAD profile="http://dublincore.org/documents/dcq-html/"> <META name="DC.author" content="Peter Mika"> <LINK rel="DC.rights copyright" href="http:// www.example.org/rights.html" /> <LINK rel="meta" type="application/rdf+xml" title="FOAF" href= "http://www.cs.vu.nl/~pmika/foaf.rdf"> </HEAD> … </HTML> - 24 -
- 25. Microformats (µf) • Agreements on the way to encode describe certain objects in HTML (persons, events, recipes…) – Reuse of semantic-bearing HTML elements, e.g. class – Based on existing standards, e.g. hCard – Minimal: small number of types, most common attributes • Community centered around microformats.org – Centralized process, but not a formal standards body – Wiki for specifications, mailing list - 25 -
- 26. Example: the hCard microformat <div class="vcard"> <a class="email fn" href="mailto:[email protected]">Joe Friday</a> <div class="tel">+1-919-555-7878</div> <div class="title">Area Administrator, Assistant</div> </div> <cite class="vcard"> <a class="fn url" rel="friend colleague met href="http://meyerweb.com/"> Eric Meyer</a> </cite> wrote a post (<cite> <a href="http://meyerweb.com/eric/thoughts/2005/12/16/tax-relief/"> Tax Relief</a></cite>) about an unintentionally humorous letter he received from the <span class="vcard > <a class="fn org url" href="http://irs.gov/"> Internal Revenue Service</a> </span>. - 26 -
- 27. Microformats: limitations • Syntax shared with HTML – You need to implement extraction for each microformat separately • Lack of formal schemas – Limited reuse, extensibility of schemas – Unclear which combinations are allowed • Lack of a datatype system • No unique identifiers (URIs) – No linking, e.g. sameAs • Always appears in the HTML <body> – Not always clear how it relates to the main topic of the page • Instability • Everything is a draft… • Varying degrees of support - 27 -
- 28. RDFa • W3C recommendation for embedding RDF data in HTML – A set of new HTML attributes to be used in head or body – A specification of how to extract the data from these attributes – RDFa is just a syntax, you have to choose (or create) a vocabulary separately • Addresses the limitations of microformats – Syntax different from HTML – Semantic Web schema languages (reuse, extend schemas) – Unique identifiers for objects (interlinking, sameAs) – Markup in head or body • Alternative to publishing data as RDF/XML (Linked Data) – Search engine friendly • See also – http://rdfa.info/ - 28 -
- 29. RDFa evolution • RDFa 1.0 is a W3C Recommendation since October, 2008 • RDFa 1.1 is a small update on RDFa to reduce complexity, make it compatible with HTML5 – Recommendation (June 7, 2012) – Updated version of the RDFa Primer (June 7, 2012) – HTML+RDFa Working Draft (Sept 11, 2012) • New in RDFa 1.1 – New vocab attribute to define the default namespace for the document or subtree – The prefix attribute as a recommended replacement of xmlns – You can use URIs even where only CURIEs were allowed before • RDFa API for accessing RDFa data in a webpage in the browser from JavaScript – Currently Working Draft (April 19, 2011) - 29 -
- 30. RDFa intro: metadata in the header <html• More info in the prefix="og: http://ogp.me/ns#"> <head> <title>The Trouble with Bob</title> <meta property="og:title" content="The Trouble with Bob" /> <meta property="og:type" content="text" /> <meta property="og:image" content="http://example.com/alice/bob-ugly.jpg" /> ... </head> - 30 -
- 31. RDFa intro: links with a flavor • More info in the All content on this site is licensed under <a rel="license" href="http://creativecommons.org/licenses/by/3.0/"> a Creative Commons License </a>. - 31 -
- 32. RDFa links: talking about subjects other than the page The trouble with Bob is that he takes much better photos than me: • More info in the <div about="http://example.com/bob/photos/sunset.jpg"> <img src="http://example.com/bob/photos/sunset.jpg" /> <span property="og:title">Beautiful Sunset</span> by <span property="dc:creator">Bob</span>. </div> - 32 -
- 33. RDFa links: talking about subjects other than the page <div typeof= foaf:Person"> <p property= foaf:name"> Alice Birpemswick </p> <p> Email: <a rel=More info in the • foaf:mbox href="mailto:[email protected]"> [email protected] </a> </p> <p> Phone: <a rel= foaf:phone" href="tel:+1-617-555-7332">+1 617.555.7332</a> </p> </div> - 33 -
- 34. The process of annotating with RDFa • Find a vocabulary that fits your needs and supported by your consumers – A vocabulary describes a set of types and attributes within a given domain – If you don t find a good candidate, extend an existing one or create a new one • Annotate your page – Before you start, you might want to validate your page for (X)HTML conformance using the W3C s (X)HTML Validator to reduce the chance of errors. Choose Document Type XHTML + RDFa. – Use an HTML or XML editor that supports DTDs, or an RDFa editor such as RDFaCE – Use the RDFa Distiller to validate which data can be extracted from your page. – If you fancy, use the RDF Validator to graphically visualize the RDF graph that is outputted. • Put the annotated page online – The data will be extracted by your favorite search engine the next time your page is crawled and indexed – The data will be available to browser extensions, bookmarklets etc. • See http://rdfa.info/rdfa-implementations for new tools and APIs - 34 -
- 35. Example: Yahoo! Enhanced Results (was: SearchMonkey) • First major adopter of RDFa – Launched in May, 2008 • Guide for publishers to mark-up their pages for common types of objects – Product, Local, News, Video, Events, Documents, Discussion, Games • Using popular microformats and RDF vocabularies – Copy-paste code – Validator • Yahoo as a consumer – Enhanced Results - 35 -
- 36. Example: Google s Rich Snippets • Launched in May, 2009 • Google encourages publishers to use popular microformats and its own RDFa vocabulary – data-vocabulary.org • Validator to check if the markup is correct • Google displays enhanced results based on this metadata – Rich Snippets - 36 -
- 37. Example: Facebook s Like and the Open Graph Protocol • Launched April, 2010 • The Like button provides publishers with a way to promote their content on Facebook and build communities – Shows up in profiles and news feed – Site owners can later reach users who have liked an object – Facebook Graph API allows 3rd party developers to access the data • Open Graph Protocol is an RDFa-based format that allows to describe the object that the user Likes - 37 -
- 38. Example: Facebook s Open Graph Protocol • RDF vocabulary to be used in conjunction with RDFa – Simplify the work of developers by restricting the freedom in RDFa • Activities, Businesses, Groups, Organizations, People, Places, Products and Entertainment • Only HTML <head> accepted <html xmlns:og="http://opengraphprotocol.org/schema/"> <head> <title>The Rock (1996)</title> <meta property="og:title" content="The Rock" /> <meta property="og:type" content="movie" /> <meta property="og:url" content="http://www.imdb.com/title/ tt0117500/" /> <meta property="og:image" content="http://ia.media-imdb.com/ images/rock.jpg" /> … </head> ... - 38 -
- 39. Example: rNews • RDFa vocabulary for news articles – Easier to implement than NewsML – Easier to consume for news search and other readers, aggregators • Under development at the IPTC – Version 0.5 - 39 -
- 40. Microdata • Developed by the HTML5 working group at the W3C – RDFa was perceived as too complex and thus error prone • Currently a companion document to HTML5 (working draft) • Incompatible with RDFa <div itemscope itemid= http://www.yahoo.com/resource/person > <p>My name is <span itemprop="name">Neil</span>.</p> <p>My band is called <span itemprop="band">Four Parts Water</span>. I was born on <time itemprop="birthday" datetime="2009-05-10">May 10th 2009</time>. <img itemprop="image" src= me.png" alt= me > </p> </div - 40 -
- 41. Competing formats, competing schemas • Multiple incompatible formats: microformats, RDFa, microdata – Varying degrees of adoption – Not all formats are supported by all search engines • Multiple competing schemas (ontologies) – Different schemas for marking up the same information (RDFa and microdata) • Major search engines support different existing alternatives or create their own (Google, Facebook) – Not clear which schemas have adoption, who is responsible for maintaining them – Slow convergence - 41 -
- 42. schema.org • Agreement on a shared set of schemas for common types of web content – Bing, Google, and Yahoo! as initial founders (June, 2011) – Similar in intent to sitemaps.org • Use a single format to communicate the same information to all three search engines • schema.org covers areas of interest to all search engines – Business listings (local), creative works (video), recipes, reviews - 42 -
- 43. schema.org evolution • Yandex joins schema.org in Nov, 2011 – Yandex.Slovari, Yandex.Spravochnik, Yandex.Kartinki, Yandex.Video • RDFa Lite 1.1 – Subset of the features of RDFa 1.1 – W3C Recommendation since June, 2012 • Two W3C task forces within the SW Interest Group (SWIG) – Web schemas TF for ongoing collaborations on schema extensions, mappings, tooling etc. • schema.org discussions are at [email protected] – HTML Data TF finished in December, 2011 • HTML Data Guide • Microdata RDF: Transformation from HTML+Microdata to RDF • Growing number of 3rd party contributions – rNews (news) – GoodRelations (e-commerce) – Health and Life Sciences – Technical Publishing - 43 -
- 44. Documentation and OWL ontology - 44 -
- 45. Current state of semantic search • Limited usage in commercial search engines – Enhanced results – Faceted search • Google s Recipe Search – Navigation to related entities • Yahoo s Vertical Intent Search • Positive SEO effects – Enhanced results are clicked more – Enhanced results help users find relevant results • Increased adoption of data markup - 45 -
- 46. Semantic Search development • Research – RDF indexing and ranking – Searching over annotated web pages – Search result summarization – Question answering – Task completion – Semantic log analysis • Prototype pure RDF search engines – Sindice and Sig.ma from DERI - 46 -
- 47. Current state of metadata on the Web • 31% of webpages, 5% of domains contain some metadata – Analysis of the Bing Crawl (US crawl, January, 2012) – RDFa is most common format • By URL: 25% RDFa, 7% microdata, 9% microformat • By eTLD (PLD): 4% RDFa, 0.3% microdata, 5.4% microformat – Adoption is stronger among large publishers • Especially for RDFa and microdata • See also – P. Mika, T. Potter. Metadata Statistics for a Large Web Corpus, LDOW 2012 – H.Mühleisen, C.Bizer. Web Data Commons - Extracting Structured Data from Two Large Web Corpora, LDOW 2012 - 47 -
- 48. Exponential growth in RDFa data Another five-fold increase between October 2010 and January, 2012 Five-fold increase between March, 2009 and October, 2010 Percentage of URLs with embedded metadata in various formats - 48 -
- 49. Semantic technologies for Data Integration
- 50. Today s world is a Web of Pages - 50 -
- 51. All these pages come from structured knowledge about people, places, and things MLB team 10% off tickets Is a for Chicago Cubs plays for plays in Chicago Carlos Zambrano from Barack Obama - 51 -
- 52. This underlying world is WOO—the Web of Objects MLB team 10% off tickets Is a for Chicago Cubs plays for plays in Chicago Carlos Zambrano from Barack Obama - 52 -
- 53. Today our knowledge of this world is siloed, incomplete, inconsistent, inaccurate, and hard to reuse MLB team 10% off tickets Entertainment isa for Upcoming Shopping Finance Sports Local Chicago Cubs plays for plays in Chicago Carlos Zambrano from Scott Roy - 53 -
- 54. Our vision is a single shared knowledge base—accurate, scalable, and easy to reuse MLB team 10% off tickets isa for Chicago Cubs plays in plays for Chicago Carlos Zambrano from Barack Obama - 54 -
- 55. Knowledge comes from many sources Show times and other information for US movies from source B Show times Attributes Show times for Harry Potter and the Deathly Hallows part II Harry Potter and the Deathly Hallows part II Entities - 55 -
- 56. Combining these requires working with complementary, parallel, and overlapping sources Cast information for US movies from source A Cast and show time Attributes information for global movies from licensed feeds Cast information for global movies from Wikipedia Entities - 56 -
- 57. There is a tremendous opportunity to do this directly from Web pages, reverse engineering the Web Attributes Information from structured data extraction on billions of Web pages Entities - 57 -
- 58. Semantic technologies for data integration • Semantic Web provides the basic technologies for Linked Data – URIs as unique identifiers • Retrieve data from the (internal) web • Follow links in the data that is returned – RDF as a common data format – OWL as a powerful schema language for validation and reasoning – SPARQL for queries, reasoning and transformations - 58 -
- 59. Components • Data is ingested from web extraction, feeds, editorial content (billions of objects) • Data integration using Hadoop clusters – Schema matching to the WOO ontology – Object reconciliation – Blending • Data quality assessment • Information extraction – Text, e.g. news content – Webpages • Enrichment – Feature computation based on user behavior, social signals and web content • Serving and ranking – Selecting the right objects to show by query, user, geography etc. - 59 -
- 60. WOO ontology • Primary use case is data validation – During information extraction and throughout the WOO platform – No reasoning • OWL2 ontology – Automatic documentation – Change management – Conversion to Yahoo internal schema language – Protégé OWL as editorial tool - 60 -
- 61. WOO ontology cntd. • Covers Yahoo s domains of interest – Movies, Music, TV, Business listings, Events, Finance, Sports, Autos, … – 250 classes and 800 properties (Sept, 2011) – Available only internally • Developed over 1.5 years by Yahoo s editorial team • Aligned with schema.org – schema.org covers only a subset of the WOO ontology - 61 -
- 62. Value #1 — Breadth, depth, and accuracy at scale We show many entities we shouldn t Up-to-date correct entities Real entities Dups, errors, and outdated entities No photo Incorrect store URL WOO improves our breadth, depth, and accuracy by combining knowledge from alternative sources, and by modernizing how we do matching, blending, and de-duping No business hours - 62 -
- 63. Value #2 — Agility launching new experiences Answers instead of links Related knowledge in context WOO lets us quickly create entity centric DD modules using the existing knowledge in the KB The integrated KB lets us show Emerging markets and tail pages relevant knowledge from one Yahoo property on other properties and off network The KB gets us deep into the tail by combining and blending knowledge from many sources - 63 -
- 64. Other potential benefits • Dynamic interlinking of content – E.g. direct links from Yahoo! News to background information in Yahoo! Music about an artist • Dynamic composition of web pages – Topic-entity pages • Better understanding of user intent – Semantic analysis of query logs – Semantic analysis of navigation paths • Exposure of Yahoo! content using standard technologies – Linking to external sources to make it part of the Linked Data cloud - 64 -
- 65. Innovative media companies are moving in this direction Courtesy of Silver Oliver (BBC) - 65 -
- 66. Innovative media companies are moving in this direction Courtesy of Evan Sandhaus (NYT). - 66 -
- 67. Take home: use what works! • The W3C s semantic technology stack is daunting – The basics are simple: • URIs for entity identifiers, RDF for data exchange • Standards for embedding data in HTML – Useful in search and at other points of content consumption • Standards for expressing the meaning of data – Useful in data integration • Do your bit! - 67 -
- 68. The End • Credits to many people from Yahoo! around the world • Contact me at – [email protected] – @pmika - 68 -