Mapping Applications with Collectives over Sub-communicators on Torus Networks (SC12)
1 like•1,619 views

SC12論文紹介@東工大



![Introduction: タスク配置
n 「どのタスク」を「どのノード」に割り当てるか
l 配置によってネットワークの使い方が変わる→性能が変わる
n 我々がやっているメニーコアの場合 (RMAP)
Bitonic Sort Matrix Multiply Idle Off-Chip Memory
Normal RMAP
100000
Elapsed cycle [K cycle]
79775
80000 68921
76587
60000 68703
40000
20000
0
Bitonic Sort Matrix Multiply
(a) Normal Allocation (b) RMAP Allocation
Shinya Takamaeda-Y. Tokyo Tech 4](https://image.slidesharecdn.com/sc2012mappingapplications-130126104434-phpapp01/85/Mapping-Applications-with-Collectives-over-Sub-communicators-on-Torus-Networks-SC12-4-320.jpg)





















Mapping Applications with Collectives over Sub-communicators on Torus Networks (SC12)
- 1. 2013年1月26日 14:00 – 17:00 SC論文読み会 @東工大 Mapping Applications with Collectives over Sub-communicators on Torus Networks (SC12) 著者:Abhinav Bhatele (LLNL), et al. 発表者:高前田(山崎) 伸也 (東工大)
- 2. この論文を選んだ理由 n 実はうちの研究室でもスパコン向けタスク配置をやって いる l あのテーマをSCに通すにはどんな感じの論文にすればいいんだ ろう?と興味がわいた n アプリには興味がないけど,スケジューリングとか配置 とかで性能を高くするのは好き n 絵がたくさん載っていて楽しそう Shinya Takamaeda-Y. Tokyo Tech 2
- 3. 概要 n スパコンにおける良いタスク配置を決定するためのツー ルに関する論文 l いくつかのシンプルなオペレーションでアプリケーションの配 置を変更できる n 2つのアプリケーションで評価 l pF3D: レーザープラズマ相互作用 l Qbox: 第1原理分子動力学 Shinya Takamaeda-Y. Tokyo Tech 3
- 4. Introduction: タスク配置 n 「どのタスク」を「どのノード」に割り当てるか l 配置によってネットワークの使い方が変わる→性能が変わる n 我々がやっているメニーコアの場合 (RMAP) Bitonic Sort Matrix Multiply Idle Off-Chip Memory Normal RMAP 100000 Elapsed cycle [K cycle] 79775 80000 68921 76587 60000 68703 40000 20000 0 Bitonic Sort Matrix Multiply (a) Normal Allocation (b) RMAP Allocation Shinya Takamaeda-Y. Tokyo Tech 4
- 5. Introduction: 従来手法について n 通信するタスク間のホップ数を小さくするように配置 l ネットワークリンクの共有や混雑を減らすため n どんな時にこれは有効か? l 各タスクが少数のノードとPoint-to-Pointで通信する,かつ l Global communicatorでcollective通信を行う場合 Shinya Takamaeda-Y. Tokyo Tech 5
- 6. Introduction: 問題点 n スパコンのノード数とネットワークの直径は増加傾向 l Global communicatorではなくsub-communicatorを用いて collective通信を行うように n Sub-communicatorを用いる場合の最適なタスク配置 l Sub-communicator単位のグループでノードをまとめれば, ホップ数は削減できる l グループ境界のハードウェアリンクが未使用となり,ネット ワークバンド幅の利用効率が制限される l 例えば,ただまとめるのではなく,ちょっとずらしたりすると 使えるリンク数が増えてネットワーク性能が上がりそう Shinya Takamaeda-Y. Tokyo Tech 6
- 7. Introduction: 本論文の貢献 n N次元トーラスにおけるSub-communicatorを用いた Collective通信,特にall-to-allとbroadcastの性能向上を 目指す l 複数の次元にまたがってトーラスのリンクを包み込むようにコ ミュニケータを配置することで,実効バンド幅を増やすことが でき,混雑を回避するための経路を提供することが可能になる l 直線上に配置した8ノードでのall-to-allは2x2x2のキューブのそれ よりもとても遅い n 既存のライブラリはレイテンシを削減するためにホップ 数を削減することにフォーカスしていたが,我々はより 多くの次元のリンクを利用することによりバンド幅使用 率を最大化する新しいツールRubikを提案する Shinya Takamaeda-Y. Tokyo Tech 7
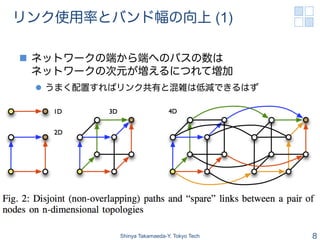
- 8. リンク使用率とバンド幅の向上 (1) n ネットワークの端から端へのパスの数は ネットワークの次元が増えるにつれて増加 l うまく配置すればリンク共有と混雑は低減できるはず Shinya Takamaeda-Y. Tokyo Tech 8
- 9. リンク使用率とバンド幅の向上 (2) n Blue Gene/P 16ノードの配置MPI_AlltoallとMPI_Bcastの 性能 l リンク集中が少なくなると所要時間が短縮 Shinya Takamaeda-Y. Tokyo Tech 9
- 10. リンク使用率とバンド幅の向上 (3) n Blue Gene/Q 8ノードの配置MPI_AlltoallとMPI_Bcastの 性能 l リンク集中が少なくなると所要時間が短縮 Shinya Takamaeda-Y. Tokyo Tech 10
- 11. リンク使用率とバンド幅の向上 (4) n 戦略 l 通信するタスクはplane/boxまたはmeshの角に配置し, 一直線上に配置しない l 通信ペア間の距離を離してスペアのリンクの数を増やす l 包み込むようなトーラスリンクを追加の経路として使う (?) Shinya Takamaeda-Y. Tokyo Tech 11
- 12. The Rubik Mapping Tool Shinya Takamaeda-Y. Tokyo Tech 12
- 13. Partitioning Operations (1) n 4つのオペレーションでタスク群を分割 l div: 指定した個数に分割 l tile: 指定した大きさに分割 l mod: 指定した個数に分割し,インターリーブで交互に配置 l cut: それぞれの次元に施すオペレーションを指定 Shinya Takamaeda-Y. Tokyo Tech 13
- 14. Partitioning Operations (2) n アプリケーションだけではなくネットワーク(ノード) も同じオペレーションで分割 l それぞれのグループのサイズがアプリケーションとネットワーク で同じであれば,自動的にマップできる Shinya Takamaeda-Y. Tokyo Tech 14
- 15. Permuting Operations (1) n 2つのオペレーションがで配置をずらすことができる l tilt: 回転 l zigzag: ジグザグにずらす Shinya Takamaeda-Y. Tokyo Tech 15
- 16. Permuting Operations (2) Shinya Takamaeda-Y. Tokyo Tech 16
- 17. Permuting Operations (3) Shinya Takamaeda-Y. Tokyo Tech 17
- 18. Mapping A Lazer-Plasma Interaction Code (1) n 2D-FFTの計算とMPI_Alltoallが多く含まれる n ベースラインの性能 l デフォルトのタスク配置: TXYZ • ノード内→X軸→Y軸→Z軸の順にMPIランクの順番に配置 Shinya Takamaeda-Y. Tokyo Tech 18
- 19. Mapping A Lazer-Plasma Interaction Code (2) n ベースライン性能 l Weak-scalingで通信と計算の比率を比較 l ノード数の増加により通信オーバーヘッドが顕著化 Shinya Takamaeda-Y. Tokyo Tech 19
- 20. Mapping A Lazer-Plasma Interaction Code (3) n 2048コアにマッピング l こんな簡単なコードで! Shinya Takamaeda-Y. Tokyo Tech 20
- 21. Mapping A Lazer-Plasma Interaction Code (4) n いくつかの配置におけるネットワーク利用状況 Shinya Takamaeda-Y. Tokyo Tech 21
- 22. Mapping A Lazer-Plasma Interaction Code (5) n 各配置におけるMPIにかかった時間 l TXYZがベースライン Shinya Takamaeda-Y. Tokyo Tech 22
- 23. Mapping A Lazer-Plasma Interaction Code (6) n 各配置における性能 l 通信レートと1イタレーションの時間 Shinya Takamaeda-Y. Tokyo Tech 23
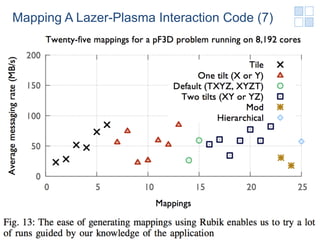
- 24. Mapping A Lazer-Plasma Interaction Code (7) Shinya Takamaeda-Y. Tokyo Tech 24
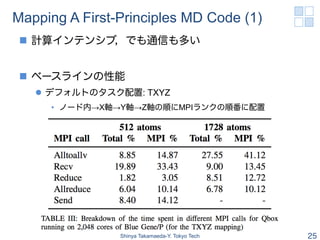
- 25. Mapping A First-Principles MD Code (1) n 計算インテンシブ,でも通信も多い n ベースラインの性能 l デフォルトのタスク配置: TXYZ • ノード内→X軸→Y軸→Z軸の順にMPIランクの順番に配置 Shinya Takamaeda-Y. Tokyo Tech 25
- 26. Mapping A First-Principles MD Code (2) n 2048コアにマッピング l こんな簡単なコードで! Shinya Takamaeda-Y. Tokyo Tech 26
- 27. Mapping A First-Principles MD Code (3) n 性能の変化 l 原子数512で40.0% (tiltY) の実行時間短縮 l 原子数1728で16.2% (mod)の実行時間短縮 Shinya Takamaeda-Y. Tokyo Tech 27
- 28. まとめ n スパコンにおける良いタスク配置を決定するためのツー ルに関する論文 l いくつかのシンプルなオペレーションでアプリケーションの配 置を変更できる n 2つのアプリケーションで評価 l pF3D: レーザープラズマ相互作用 l Qbox: 第1原理分子動力学 Shinya Takamaeda-Y. Tokyo Tech 28