MariaDB ColumnStore
0 likes552 views

MariaDB ColumnStore is a high performance columnar storage engine for MariaDB that supports analytical workloads on large datasets. It uses a distributed, massively parallel architecture to provide faster and more efficient queries. Data is stored column-wise which improves compression and enables fast loading and filtering of large datasets. The cpimport tool allows loading data into MariaDB ColumnStore in bulk from CSV files or other sources, with options for centralized or distributed parallel loading. Proper sizing of ColumnStore deployments depends on factors like data size, workload, and hardware specifications.
























![Bulk Data Load: cpimport
• Fastest way to load data into MariaDB ColumnStore
• Load data from CSV file
cpimport dbName tblName [loadFile]
• Load data from Standard Input
mysql -e 'select * from source_table;' -N db2 | cpimport destination_db
destination_tbl -s 't‘
• Load data from Binary Source file
cpimport -I1 mydb mytable sourcefile.bin
• Multiple tables in can be loaded in parallel by launching multiple jobs
• Read queries continue without being blocked
• Successful cpimport is auto-committed
• In case of errors, entire load is rolled back](https://image.slidesharecdn.com/mariadbcolumnstore170524-170607100633/85/MariaDB-ColumnStore-26-320.jpg)





MariaDB ColumnStore
- 2. Agenda • Why using a Column Based database – And why not? • MariaDB ColumnStore architecture • Using and Sizing MariaDB ColumnStore • Getting data into MariaDB ColumnStore
- 3. Why a Columnar Database
- 4. Data organization • Row-by-row – Good for row based processing – Use indexing for lookups • Typically B-Tree indexing – Indexing is difficult for data that is not well distributed – Indexing slows down DML • Column based – Good for dataset based processing – Needs no indexes – Data is typically organized in chunks – Lends itself to high level of compression – Metadata used for filtering and processing – Large amount of data is much, much less of an issue – Loading data is consistently fast, independent on data size
- 5. OLTP/NoSQL Workloads Suited for reporting or analysis of millions-billions of rows from data sets containing millions-trillions of rows. OLAP/Analytic/ Reporting Workloads Workload – Query Vision/Scope 1 100 10,000 10-100GB 10,000,000,000 1-10TB 1,000,000 100,000,000 100-1,000GB
- 6. Columnar General Best Practices Not suited for OLTP Micro-batch load allows for near real-time behavior Infrequently used columns do not impact other queries Columnar suitable for sparse columns (nulls compress nicely)
- 7. Data Modeling Best Practices Star-schema optimizations are generally a good idea Conservative data typing is very important Especially around fixed-length vs. dictionary boundary (8 bytes) IP Address vs. IP Number Break down compound fields into individual fields: Trivializes searching for sub-fields Can avoid dictionary overhead Cost to re-assemble is generally small
- 9. MariaDB ColumnStore High performance columnar storage engine that support wide variety of analytical use cases with SQL in a highly scalable distributed environments Parallel query processing for distributed environments Faster, More Efficient Queries Single SQL Interface for both OLTP and analytics Easier Enterprise Analytics Power of SQL and Freedom of Open Source to Big Data Analytics Better Price Performance
- 10. MariaDB ColumnStore • GPLv2 Open Source • Columnar, Massively Parallel MariaDB Storage Engine • Scalable, high-performance analytics platform • Built in redundancy and high availability • Runs on premise and on AWS cloud • Full SQL syntax and capabilities regardless of platform Big Data Sources Analytics Insight MariaDB ColumnStore . . . Node 1 Node 2 Node 3 Node N Local / AWS® / GlusterFS® ELT Tools BI Tools
- 11. SQL Features Source : InfiniDB SQL Syntax Guide Cross Engine Joins UDF DML Aggregation DDL Disk Based Joins Windowing Functions SELECT QUERY
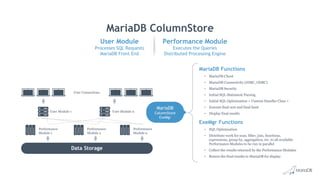
- 12. MariaDB ColumnStore Architecture Data Storage User Connections User Module nUser Module 1 Performance Module n Performance Module 2 Performance Module 1 MariaDB Front End Query Engine User Module Processes SQL Requests Performance Module Distributed Processing Engine
- 13. Process Functionality Value MariaDB • Hosts MariaDB • Connection management • SQL parsing & optimization Familiar DBMS interface Leverages existing partner integrations Delivers rich SQL syntax support Extent Map • Abstracts physical and logical storage • Metadata store Enables partition elimination ExeMgr • Work distribution • Final results management and aggregation Multi-threaded to take advantage of multi-core HW platforms User Module at a Glance
- 14. Process Functionality Value PrimProc • Scale-out cache management • Distributed scan, filter, join and aggregation operations • Resource management Independent scalability and tunable performance Multi-threaded to take advantage of multi-core HW platforms Data • High Speed Bulk Load • Transactional DML and DDL • Online schema extensions Non-blocking read enabled Multi-threaded to take advantage of multi-core HW platforms Performance Module at a Glance
- 15. MariaDB ColumnStore MariaDB Functions • MariaDB Client • MariaDB Connectivity (JDBC, ODBC) • MariaDB Security • Initial SQL Statement Parsing • Initial SQL Optimization < Custom Handler Class > • Execute final sort and final limit • Display final results ExeMgr Functions • SQL Optimization • Distribute work for scan, filter, join, functions, expressions, group by, aggregation, etc. to all available Performance Modules to be run in parallel • Collect the results returned by the Performance Modules • Return the final results to MariaDB for display MariaDB ColumnStore ExeMgr Data Storage User Connections User Module nUser Module 1 Performance Module n Performance Module 2 Performance Module 1 User Module Processes SQL Requests MariaDB Front End Performance Module Executes the Queries Distributed Processing Engine
- 16. Compression with Data Storage Layer Blocks (8KB) Extent1 (8MB~64MB 8 million rows) Logical Layer Segment File1 (maps to an Extent) Physical Layer Compression Chunks
- 17. • 8-byte fixed length token (pointer). • A variable length value stored at the location identified by the pointer. Data Types 1-byte Field with 8192 values per 8k block 2-byte Field with 4096 values per 8k block 4-byte Field with 2048 values per 8k block 8-byte Field with 1024 values per 8k block Dictionary structure made up of 2 files/extents with: At the physical layer, all columns are stored as:
- 18. • Varchar(8) or larger • Char(9) or larger Data Types 1-byte Field Examples TinyInt, Char(1) 2-byte Field Examples SmallInt, Char(2) 4-byte Field Examples Int, Char(3), Char(4), date, float 8-byte Field Examples BigInt, Char(5- 8),datetime, real/double Dictionary Examples At the physical layer, all columns are stored as:
- 19. Using MariaDB ColumnStore Just like MariaDB Server
- 20. MariaDB ColumnStore MariaDB ColumnStore uses standard “Engine=columnstore” syntax mysql> use tpcds_djoshi Database changed mysql> select count(*) from store_sales; +----------+ | count(*) | +----------+ | 2880404 | +----------+ 1 row in set (1.68 sec) mysql> describe warehouse; +-------------------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------------------+--------------+------+-----+---------+-------+ | w_warehouse_sk | int(11) | NO | | NULL | | | w_warehouse_id | char(16) | NO | | NULL | | | w_warehouse_name | varchar(20) | YES | | NULL | | | w_warehouse_sq_ft | int(11) | YES | | NULL | | | w_street_number | char(10) | YES | | NULL | | | w_street_name | varchar(60) | YES | | NULL | | | w_street_type | char(15) | YES | | NULL | | | w_suite_number | char(10) | YES | | NULL | | | w_city | varchar(60) | YES | | NULL | | | w_county | varchar(30) | YES | | NULL | | | w_state | char(2) | YES | | NULL | | | w_zip | char(10) | YES | | NULL | | | w_country | varchar(20) | YES | | NULL | | | w_gmt_offset | decimal(5,2) | YES | | NULL | | +-------------------+--------------+------+-----+---------+-------+ 14 rows in set (0.05 sec) CREATE TABLE `game_warehouse`.`dim_title` ( `id` INT, `name` VARCHAR(45), `publisher` VARCHAR(45), `release_date` DATE, `language` INT, `platform_name` VARCHAR(45), `version` VARCHAR(45) ) ENGINE=columnstore; Uses custom scalable columnar architecture
- 21. MariaDB ColumnStore mysql> use tpcds_djoshi Database changed mysql> select count(*) from store_sales; +----------+ | count(*) | +----------+ | 2880404 | +----------+ 1 row in set (1.68 sec) mysql> describe warehouse; +-------------------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------------------+--------------+------+-----+---------+-------+ | w_warehouse_sk | int(11) | NO | | NULL | | | w_warehouse_id | char(16) | NO | | NULL | | | w_warehouse_name | varchar(20) | YES | | NULL | | | w_warehouse_sq_ft | int(11) | YES | | NULL | | | w_street_number | char(10) | YES | | NULL | | | w_street_name | varchar(60) | YES | | NULL | | | w_street_type | char(15) | YES | | NULL | | | w_suite_number | char(10) | YES | | NULL | | | w_city | varchar(60) | YES | | NULL | | | w_county | varchar(30) | YES | | NULL | | | w_state | char(2) | YES | | NULL | | | w_zip | char(10) | YES | | NULL | | | w_country | varchar(20) | YES | | NULL | | | w_gmt_offset | decimal(5,2) | YES | | NULL | | +-------------------+--------------+------+-----+---------+-------+ 14 rows in set (0.05 sec) MariaDB Front End Standard ANSI SQL
- 22. Sizing Minimum Spec UM 4 core, 32 G RAM PM 4 core, 16 G RAM Typical Server spec PM 8 core 64G RAM UM 8 core, 264G RAM Data Storage External Data Volumes • Maximum 2 data volume per IO channel per PM node server • up to 2TB on the disk per data volume ≈ Max 4 TB per PM node Local disk Up to 2TB on the disk per PM node server DETAILED SIZING GUIDE based on data size and workload
- 23. Sizing - Example • MariaDB ColumnStore 60TB uncompressed data = 6TB compressed data at 10x compression • 2UM - 8 core 512G(based on work load) • 6 TB compressed = 3 data volume (at 2TB per volume) - with 1 data volume per PM node - 3PMs • Data growth - 2TB per month, Data retention - 2 years - Plan for 2TB X24 = 48 TB additional - 48 TB = 4.8TB compressed ≈ 3 data volume(at 2TB per volume) with 1 data volume per PM node - 3 additional PMs • Total 6 PMs, 2 UMs
- 24. Loading data 24
- 25. Data Load and Extents (local load) 8 million rows 1st Data Load CSV File Data Range 1 ~ 200 Rows 16 million 2nd Data Load New CSV File Data Range 150 ~ 210 Rows 16 million +8 Data Load Data Load Extent 1 Min 1, Max 200 Extent 2 Min 1, Max 200 8 million rows 8 million rows Extent 3 Min 150, Max 210 Extent 4 Min 150, Max 210 8 million rows Extent 5 Min 150, Max 210 8 million rows
- 26. Bulk Data Load: cpimport • Fastest way to load data into MariaDB ColumnStore • Load data from CSV file cpimport dbName tblName [loadFile] • Load data from Standard Input mysql -e 'select * from source_table;' -N db2 | cpimport destination_db destination_tbl -s 't‘ • Load data from Binary Source file cpimport -I1 mydb mytable sourcefile.bin • Multiple tables in can be loaded in parallel by launching multiple jobs • Read queries continue without being blocked • Successful cpimport is auto-committed • In case of errors, entire load is rolled back
- 27. Bulk Data Load: cpimport mode 1 Single file Central Input : Data source at UM cpimport -m1 mytest mytable mytable.tbl cpimport Name Node UM Node Source Data Node PM Node Data Node PM Node Data Node PM Node
- 28. Bulk Data Load: cpimport mode 2 Distributed Input: Data Source at PMs Partitioned load file on each PM cpimport -m2 testdb mytable /home/mydata/mytable.tbl cpimport Name Node UM Node Source Data Node PM Node Data Node PM Node Data Node PM Node Source Source
- 29. Distributed Input: Data Source at PMs Partitioned load file on each PM cpimport -m2 testdb mytable /home/mydata/mytable.tbl Bulk load command at one or more PM cpimport –m3 testdb mytable /home/mydata/mytable.tbl Bulk Data Load: cpimport mode 3 Name Node UM Node Source Data Node PM Node Data Node PM Node Data Node PM Node Source Source cpimport cpimport cpimport
- 30. Traditional way of importing data into any MariaDB storage engine table Bulk Data Load: LOAD DATA INFILE Up to 2 times slower than cpimport for large size imports mysql> load data infile '/tmp/ outfile1.txt' into table destinationTable; Query OK, 9765625 rows affected (2 min 20.01 sec) Records: 9765625 Deleted: 0 Skipped: 0 Warnings: 0 Either success or error operation can be rolled back
- 31. Thank you