Mastering Kafka Consumer Distribution: A Guide to Efficient Scaling and Resource Optimization
0 likes487 views

The document discusses the complexities of scaling Kafka consumers and the importance of efficient rebalancing to optimize resource utilization and minimize lag. It identifies challenges such as slow group coordinators and the potential negative impacts of unnecessary rebalancing on performance. The document also emphasizes the need for a strategic approach to scaling, including understanding when to scale, monitoring consumer metrics, and optimizing autoscaling strategies.






































































































Mastering Kafka Consumer Distribution: A Guide to Efficient Scaling and Resource Optimization
- 1. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Mastering Kafka consumer distribution A guide to efficient scaling and resource optimization Olena Kutsenko Sr. Developer Advocate Aiven Olena Babenko Staff Software Engineer Aiven
- 2. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Mastering Kafka consumer distribution A guide to efficient scaling and resource optimization ➔ why scaling consumers is not always desirable ➔ why consumer lag isn’t the metric you want to rely on ➔ how not to scale stateful consumers ➔ what is the most anticipated change in rebalancing protocol ➔ how to find a right balance between latency, durability and costs
- 3. Definition 1 ● What is rebalancing? ● Why do we need it?
- 5. Producers Consumers Topic �� Partition 1 Partition 2 Partition 3 Partition 4
- 6. Producers Consumers Topic �� Partition 1 Partition 2 Partition 3 Partition 4
- 7. Producers Consumers Topic �� Partition 1 Partition 2 Partition 3 Partition 4
- 8. Partition 1 Partition 2 Partition 3 Partition 4 Consumer 1 Consumer 2 Consumer 3
- 9. Broker 2 Partition 1 Partition 2 Partition 3 Partition 4 Consumer 1 Consumer 2 Consumer 3 Broker 1
- 10. Broker 2 Partition 1 Partition 2 Partition 3 Partition 4 Consumer 1 Consumer 2 Consumer 3 Broker 1 Consumer group
- 11. Broker 2 Partition 1 Partition 2 Partition 3 Partition 4 Consumer 1 Consumer 2 Consumer 3 Broker 1 Consumer group Consumer 4
- 12. Broker 2 Partition 1 Partition 2 Partition 3 Partition 4 Consumer 1 Consumer 2 Consumer 3 Broker 1 Consumer group Consumer 4 We need efficient rebalancing for: ● Scalability ● Elasticity ● Fault tolerance Moving ownership from one consumer to another is called a rebalance
- 13. Broker 2 Partition 1 Partition 2 Partition 3 Partition 4 Consumer 1 Consumer 2 Consumer 3 Broker 1 Consumer group Consumer 4 Side effects of rebalancing: ● Increased consumer lag, latency and reduced throughput ● Increased resource utilization ● Potential data duplication or data loss ● Increased complexity We need efficient rebalancing for: ● Scalability ● Elasticity ● Fault tolerance Moving ownership from one consumer to another is called a rebalance
- 14. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Rebalancing has a lot in common with cooking
- 15. [email protected] @OlenaKutsenko aiven.io Olena Babenko: 1. Know when to scale (and when not) 2. Minimize unnecessary data movement 3. Avoid unnecessary rebalancing We want to scale efficiently and effectively:
- 16. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Rebalancing is a teamwork
- 17. Broker 2 Partition 1 Partition 2 Partition 3 Partition 4 Consumer 1 Consumer 2 Consumer 3 Broker 1 Consumer group Consumer 4
- 18. Broker 2 Partition 1 Partition 2 Partition 3 Partition 4 Consumer 1 Consumer 2 Consumer 3 Broker 1 Consumer group Consumer 4 Group coordinator - broker
- 19. Broker 2 Partition 1 Partition 2 Partition 3 Partition 4 Consumer 1 Consumer 2 Consumer 3 Broker 1 Consumer group Consumer 4 Group coordinator - broker Group leader - consumer
- 21. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Group coordinator Consumer 1 Consumer 2 Consumer 1 member.id=c1 partitions 1 & 2 Consumer 2 member.id=c2 partition 3
- 22. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Group coordinator Consumer 1 Consumer 2 Consumer 1 member.id=c1 partitions 1 & 2 Consumer 2 member.id=c2 partition 3 ��
- 23. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Group coordinator Consumer 1 Consumer 2 Consumer 1 member.id=c1 partitions 1 & 2 Consumer 2 member.id=c2 partition 3 Consumer 3 new
- 24. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Group coordinator Consumer 1 Consumer 2 Consumer 1 member.id=c1 partitions 1 & 2 Consumer 2 member.id=c2 partition 3 �� Consumer 3 new JoinGroupRequest {member.id=unknown}
- 25. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Group coordinator Consumer 1 Consumer 2 Consumer 1 member.id=c1 partitions 1 & 2 Consumer 2 member.id=c2 partition 3 �� Consumer 3 new JoinGroupRequest {member.id=unknown} HeartbeatResponse {REBALANCE_IN_PROGRESS} HeartbeatResponse {REBALANCE_IN_PROGRESS}
- 26. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Group coordinator Consumer 1 Consumer 2 Consumer 1 member.id=c1 partitions 1 & 2 Consumer 2 member.id=c2 partition 3 �� Consumer 3 new JoinGroupRequest {member.id=unknown} HeartbeatResponse {REBALANCE_IN_PROGRESS} HeartbeatResponse {REBALANCE_IN_PROGRESS} JoinGroupRequest {member.id=c1} JoinGroupRequest {member.id=c2}
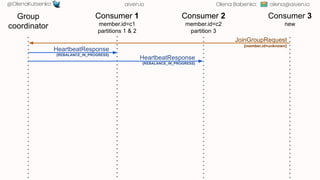
- 27. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Group coordinator Consumer 1 Consumer 2 Consumer 1 member.id=c1 partitions 1 & 2 Consumer 2 member.id=c2 partition 3 �� Consumer 3 new JoinGroupRequest {member.id=unknown} HeartbeatResponse {REBALANCE_IN_PROGRESS} HeartbeatResponse {REBALANCE_IN_PROGRESS} JoinGroupRequest {member.id=c1} JoinGroupRequest {member.id=c2} JoinGroupResponse {memberId, member list & subscriptions} JoinGroupResponse JoinGroupResponse
- 28. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Group coordinator Consumer 1 Consumer 2 Consumer 1 member.id=c1 partitions 1 & 2 Consumer 2 member.id=c2 partition 3 �� Consumer 3 new JoinGroupRequest {member.id=unknown} HeartbeatResponse {REBALANCE_IN_PROGRESS} HeartbeatResponse {REBALANCE_IN_PROGRESS} JoinGroupRequest {member.id=c1} JoinGroupRequest {member.id=c2} JoinGroupResponse {memberId, member list & subscriptions} �� SyncGroupRequest {assignment plan} SyncGroupRequest SyncGroupRequest JoinGroupResponse JoinGroupResponse
- 29. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Group coordinator Consumer 1 Consumer 2 Consumer 1 member.id=c1 partitions 1 & 2 Consumer 2 member.id=c2 partition 3 �� Consumer 3 new JoinGroupRequest {member.id=unknown} HeartbeatResponse {REBALANCE_IN_PROGRESS} HeartbeatResponse {REBALANCE_IN_PROGRESS} JoinGroupRequest {member.id=c1} JoinGroupRequest {member.id=c2} JoinGroupResponse {memberId, member list & subscriptions} JoinGroupResponse �� SyncGroupRequest {assignment plan} SyncGroupResponse {assignment plan} SyncGroupRequest SyncGroupRequest SyncGroupResponse {assignment plan} SyncGroupResponse {assignment plan} JoinGroupResponse
- 30. [email protected] @OlenaKutsenko aiven.io Olena Babenko: You probably already see some bottlenecks….
- 31. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Drama points 1. Group coordinator is too slow
- 32. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Drama points 1. Group coordinator is too slow 2. Group leader is too slow
- 33. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Drama points 1. Group coordinator is too slow 2. Group leader is too slow 3. Some of consumers are too slow
- 34. [email protected] @OlenaKutsenko aiven.io Olena Babenko: 1. Group coordinator is too slow 2. Group leader is too slow 3. Some of consumers are too slow Drama points # of consumers Probability of success per instance Overall probability
- 35. [email protected] @OlenaKutsenko aiven.io Olena Babenko: 1. Group coordinator is too slow 2. Group leader is too slow 3. Some of consumers are too slow Drama points # of consumers Probability of success per instance Overall probability 6 99%
- 36. [email protected] @OlenaKutsenko aiven.io Olena Babenko: 1. Group coordinator is too slow 2. Group leader is too slow 3. Some of consumers are too slow Drama points # of consumers Probability of success per instance Overall probability 6 99% =0.99^6 = 0.94 = 94%
- 37. [email protected] @OlenaKutsenko aiven.io Olena Babenko: 1. Group coordinator is too slow 2. Group leader is too slow 3. Some of consumers are too slow 4. Drama points # of consumers Probability of success per instance Overall probability 6 99% =0.99^6 = 0.94 = 94% 100 99%
- 38. [email protected] @OlenaKutsenko aiven.io Olena Babenko: 1. Group coordinator is too slow 2. Group leader is too slow 3. Some of consumers are too slow 4. Drama points # of consumers Probability of success per instance Overall probability 6 99% =0.99^6 = 0.94 = 94% 100 99% =0.99^100 = 0.366 = 37%
- 39. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Drama points 1. Group coordinator is too slow 2. Group leader is too slow 3. Some of consumers are too slow 4. A new node is stuck in rebalancing
- 40. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Drama points 1. Group coordinator is too slow 2. Group leader is too slow 3. Some of consumers are too slow 4. A new node is stuck in rebalancing 5. onPartitionsRevoked dark hole
- 41. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Drama points 1. Group coordinator is too slow 2. Group leader is too slow 3. Some of consumers are too slow 4. A new node is stuck in rebalancing 5. onPartitionsRevoked dark hole Consumers apply the new assignment plan: 1. What partitions are newly assigned and what are now revoked 2. Start reading from newly assigned partitions 3. If any existing partitions are revoked trigger a new rebalance
- 42. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Drama points 1. Group coordinator is too slow 2. Group leader is too slow 3. Some of consumers are too slow 4. A new node is stuck in rebalancing 5. onPartitionsRevoked dark hole Consumers apply the new assignment plan: 1. What partitions are newly assigned and what are now revoked 2. Start reading from newly assigned partitions 3. If any existing partitions are revoked trigger a new rebalance
- 44. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Scale horizontally vs vertically Vertical scaling Pros: - Less rebalancing, if static members used. (group.instance.id config). More flexible, when run out of resources(CPU, RAM, disc etc). Vertical scaling Cons: - Lots of partitions on one node, not always good as well - one hot partition could hog all resources. - Bigger machines not always possible. - State might be lost
- 45. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Horizontal scaling is time consuming and risky. How to make it more efficient?
- 46. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Build In consumer metrics records-lag-max Lag - very common metric to identify that there are too much going on, especially, is lag is among ALL or majority of partitions. records-consumed-rate The average number of records consumed per second join-rate If only one partition is laging, that might be an error, or problems with Job Groups. Helps to monitor if something is wrong with a rebalancing
- 47. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Build In consumer metrics Pros: - It is a simplest option to start from Cons: - On a consumer side and depends on a consumer health and state
- 48. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Kafka cluster metrics
- 49. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Generic Kafka Cluster metrics - Also have lag info - Less biased - More info about producers and events production - Additional important info about group coordinator health
- 50. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Autoscale
- 51. [email protected] @OlenaKutsenko aiven.io Olena Babenko: KEDA (Apache Kafka scaler) lagThreshold Could be tuned to scale instanced based on lag. activationLagThreshold The activating (or deactivating) phase is the moment when KEDA (operator) has to decide if the workload should be scaled from/to zero + many more + A lot more, if chose prometheus trigger (custom metrics)
- 52. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Knative - Scale up and down faster using an amount of events - You can Scale Kafka Source using KEDA - Great in handling spikes - Reusability of resources - Keeps same pod identity, while replacing nodes (reduce amount of rebalancing during failure) - More complicated
- 53. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Lag only grows after autoscale
- 54. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Autoscale using lag is not always optimal - Lots of joins/rebalancing can make event consumption slower. More nodes will be requested as a result - Too much pressure on one Leading node - Lag metric doesn’t answer question WHAT CAUSED A LAG! (it is not always lack of resources) As a result: - Fast autoscaling might be problematic
- 55. [email protected] @OlenaKutsenko aiven.io Olena Babenko: 1. Know when to scale (and when not) 2. Minimize unnecessary data movement 3. Avoid unnecessary rebalancing We want to scale efficiently and effectively:
- 56. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Lag == Money 💰 ?
- 57. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Lag == Money 💰 !! Time ⌛
- 58. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Time is more universal unit - Lag is depending on a message sizes, on batch.size, on linger.ms - Time is more universal unit for many businesses - you probably know how much it cost to delay order for 2 hours, or paying website downtime for 5 minutes. - AWS, Confluent, Aiven etc usually on a server side provide time-related metrics like Estimated Time Lag or Latency
- 59. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Simplest way to calculate time lag - Took latest offset from a consumer group - Read committed/consumed message timestamp from a topic - Compare with current time Pros: - Accurate Cons: - Need to get a whole message (might be big) - Need to do this quite often - Do not scale well for multiple producers, consumer-groups, topics and partitions
- 60. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Serglo - Build an interpolation table to eliminate disadvantages of a simple method - A latest committed/consumed message get approximated(predicted) timestamp - Predicted timestamp compared with current time, to return time lag
- 61. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Serglo
- 62. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Aiven time lag predictor
- 63. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Aiven Lag predictor Checkpoint 1: 09:00
- 64. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Aiven Lag predictor Checkpoint 2: 09:05
- 65. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Aiven Lag predictor Consumption speed: 100 - 70 = 30 records per 5 seconds = 30 / 5 = 6 records per second Left to consume: 180 - 100 = 80 records = 80 / 6 = 13.333 seconds to catch up
- 66. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Aiven Lag predictor kafka_lag_predictor_group_lag_predicted_seconds - estimate how much time you need to catch up, with a current producing and consuming speed. OR Estimate WHEN will be consumed event that was published right NOW. More data points gives more precise results.
- 67. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Compare - Serglo more about individual message level(deduce timestamp for a one last message) vs Aiven lag predictor more about overall speed. Both could be useful in a right context - Any options, usually works good - Can give you slightly different results, and expectations might be different
- 68. [email protected] @OlenaKutsenko aiven.io Olena Babenko: More metrics for better conclusion
- 69. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Aiven Lag predictor
- 70. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Aiven Lag predictor Server-side metrics, defined at the same time: `kafka_lag_predictor_topic_produced_records_total` Represents the total count of records produced.(per partition) `kafka_lag_predictor_group_consumed_records_total` Represents the total count of records consumed. (per partition)
- 71. [email protected] @OlenaKutsenko aiven.io Olena Babenko: 1. Know when to scale (and when not) 2. Minimize unnecessary data movement 3. Avoid unnecessary rebalancing We want to scale efficiently and effectively:
- 72. [email protected] @OlenaKutsenko aiven.io Olena Babenko: 1. Know when to scale (and when not) 2. Minimize unnecessary data movement 3. Avoid unnecessary rebalancing - Scale multiple instances at once We want to scale efficiently and effectively:
- 73. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Scaling ratio Aiven lag predictor (per partition): - Changes over time of AVG(kafka_lag_predictor_topic_produced_records_total / kafka_lag_predictor_group_consumed_records_total ) Client side alternative (per topic): - Changes over time of AVG(record-send-total / record-consumed-total) - OR per second record-send-rate / records-consumed-rate
- 74. [email protected] @OlenaKutsenko aiven.io Olena Babenko: 1. Know when to scale (and when not) 2. Minimize unnecessary data movement 3. Avoid unnecessary rebalancing We want to scale efficiently and effectively:
- 75. [email protected] @OlenaKutsenko aiven.io Olena Babenko: 1. Know when to scale (and when not) Identify other issues that caused lag 2. Minimize unnecessary data movement 3. Avoid unnecessary rebalancing We want to scale efficiently and effectively:
- 76. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Rebalancing issues Aiven lag predictor (per partition): - Max over time of for all consumers in topic kafka_lag_predictor_group_consumed_records_total == 0 New server side metrics (KIP-714): - consumer.coordinator.assigned.partitions != 0 - consumer.coordinator.rebalance.latency.max Client side alternative: - join-rate (Consumer)
- 77. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Consumption issues Aiven lag predictor (per partition): - Max over time per partition, per topic kafka_lag_predictor_group_consumed_records_total == 0 New server side metrics (KIP-714): - consumer.fetch.manager.fetch.latency.max - consumer.node.request.latency.max - consumer.connection.creation.total
- 78. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Production issues (Scale down) Aiven lag predictor (per partition): - Max over time of kafka_lag_predictor_topic_produced_records_total == 0 - Hot partition MAX(kafka_lag_predictor_topic_produced_records_total) AVG(kafka_lag_predictor_topic_produced_records_total) New server side metrics (KIP-714): - producer.record.queue.time.max - producer.node.request.latency.max - producer.record.queue.time.max
- 79. So! When to Scale?
- 80. [email protected] @OlenaKutsenko aiven.io Olena Babenko: What is important for your business? - Define relevant business rules to predict problem - Rules could be a combination of different metrics: - Time lag estimation - Producer health/speed - Consumer health/speed - Group Coordinator metrics Example: Burrow. Took an offsets and other metrics and transform them into status.
- 81. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Conclusion - Use static groups when possible - Include /Try server side metrics + new broker metrics - Reactive scaling not always good (better to predict lag, then act when consumer group already lagging) - Scale based on your business needs - Scale X instances at once and not overload your partition leader to reduce rebalancing <- Could we do better?
- 82. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Yes!
- 83. [email protected] @OlenaKutsenko aiven.io Olena Babenko: A new consumer protocol! Yey!
- 85. [email protected] @OlenaKutsenko aiven.io Olena Babenko: KIP-848 The Next Generation of the Consumer Rebalance Protocol ➔
- 86. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Should we redo everything right now?
- 87. [email protected] @OlenaKutsenko aiven.io Olena Babenko: New consumer group protocol - Consumers are not responsible for keeping state - Leader is not responsible for calculating assignment - Simpler - Not all problems gone
- 88. [email protected] @OlenaKutsenko aiven.io Olena Babenko: New consumer group protocol - Pay more attention to broker health. This might be another important dimension to your metrics - Life of consumers should become easier, and some metrics become obsolete - Life of Kafka providers like Consuent, AWS, Aiven became harder, but it is not your problem ;)
- 89. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Conclusion. - Use static groups when possible - Include /Try server side metrics + new broker metrics - Reactive scaling not always good (better to predict lag, then act when consumer group already lagging) - Scale based on your business needs - Scale X instances at once and not overload your partition leader <- Not a problem anymore - You can try a new protocol version soon (3.7 preview)
- 90. [email protected] @OlenaKutsenko aiven.io Olena Babenko: 1. Know when to scale (and when not) 2. Minimize unnecessary data movement 3. Avoid unnecessary rebalancing We want to scale efficiently and effectively:
- 91. [email protected] @OlenaKutsenko aiven.io Olena Babenko: 1. Know when to scale (and when not) 2. Minimize unnecessary data movement 3. Avoid unnecessary rebalancing We want to scale efficiently and effectively:
- 93. [email protected] @OlenaKutsenko aiven.io Olena Babenko: 1. Know when to scale (and when not) 2. Minimize unnecessary data movement 3. Avoid unnecessary rebalancing We want to scale efficiently and effectively:
- 94. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Assignors ➔ RangeAssignor ➔ RoundRobinAssignor ➔ CooperativeStickyAssignor
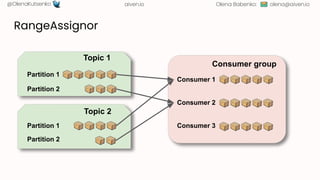
- 95. [email protected] @OlenaKutsenko aiven.io Olena Babenko: RangeAssignor
- 96. [email protected] @OlenaKutsenko aiven.io Olena Babenko: RangeAssignor Topic 2 Partition 1 Partition 2 Partition 1 Partition 2 Consumer 1 Consumer 2 Consumer 3 Topic 1 Consumer group
- 97. [email protected] @OlenaKutsenko aiven.io Olena Babenko: RoundRobinAssignor
- 98. [email protected] @OlenaKutsenko aiven.io Olena Babenko: RoundRobinAssignor Topic 2 Partition 1 Partition 2 Partition 1 Partition 2 Consumer 1 Consumer 2 Consumer 3 Topic 1 Consumer group
- 99. [email protected] @OlenaKutsenko aiven.io Olena Babenko: CooperativeStickyAssignor
- 100. [email protected] @OlenaKutsenko aiven.io Olena Babenko: CooperativeStickyAssignor Topic 2 Partition 1 Partition 2 Partition 1 Partition 2 Consumer 1 Consumer 2 Consumer 3 Topic 1 Consumer group
- 101. [email protected] @OlenaKutsenko aiven.io Olena Babenko: ● Scaling infinitely is not possible ● Use static groups and CooperativeStickyAssignor ● Pay attention to broker and consumer health ● Predict lag, not act when consumer group already lagging ● Define business rules and control them with metrics Remember
- 102. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Olena Kutsenko twitter.com/OlenaKutsenko linkedin.com/in/olenakutsenko Olena Babenko linkedin.com/in/melhelen/ https://github.com/anelook/mastering-kafka-consumer-distribution
- 103. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Olena Kutsenko twitter.com/OlenaKutsenko linkedin.com/in/olenakutsenko Olena Babenko linkedin.com/in/melhelen/ https://github.com/anelook/mastering-kafka-consumer-distribution Register for Aiven for Apache Kafka and get extra credits:
- 104. [email protected] @OlenaKutsenko aiven.io Olena Babenko: Olena Kutsenko twitter.com/OlenaKutsenko linkedin.com/in/olenakutsenko Olena Babenko linkedin.com/in/melhelen/ Find us at #108 https://github.com/anelook/mastering-kafka-consumer-distribution Register for Aiven for Apache Kafka and get extra credits: