Migrating Airflow-based Apache Spark Jobs to Kubernetes – the Native Way
1 like915 views

The document discusses the migration of Airflow-based Spark jobs to Kubernetes, highlighting benefits such as cost reduction, increased visibility, and system robustness. It covers the technical aspects of using Kubernetes for managing data pipelines, including architecture, challenges, and integration with Airflow. Key points also include the adoption of Kubernetes for scalability and the introduction of a Spark-on-Kubernetes operator for streamlined application deployment.















































































Migrating Airflow-based Apache Spark Jobs to Kubernetes – the Native Way
- 2. @ItaiYaffe, @RTeveth Take a look at your data pipeline...
- 3. @ItaiYaffe, @RTeveth … Now back to me
- 4. @ItaiYaffe, @RTeveth … Now back at your pipeline
- 5. @ItaiYaffe, @RTeveth … Now back to me
- 6. @ItaiYaffe, @RTeveth Sadly, your pipeline isn’t me...
- 7. @ItaiYaffe, @RTeveth But if you migrate: Airflow Spark jobs to Kubernetes...
- 8. @ItaiYaffe, @RTeveth You can boost your data pipeline like me SAVE $10,000’s/month GAIN visibility MAKE your systems robust
- 9. Migrating Airflow-based Spark jobs to K8s the native way Roi Teveth, Nielsen Itai Yaffe, Imply
- 10. @ItaiYaffe, @RTeveth Introduction Roi TevethItai Yaffe ● Principal Solutions Architect @ Imply Prev. Big Data Tech Lead @ Nielsen ● Itai Yaffe @ItaiYaffe ● Big Data developer @ Nielsen Identity ● Kubernetes evangelist ● Roi Teveth @RTeveth
- 11. @ItaiYaffe, @RTeveth What will you learn? How to easily migrate your Spark jobs to K8s
- 12. @ItaiYaffe, @RTeveth What will you learn? How to easily migrate your Spark jobs to K8s to reduce costs, gain visibility and robustness
- 13. @ItaiYaffe, @RTeveth What will you learn? How to easily migrate your Spark jobs to K8s to reduce costs, gain visibility and robustness using Airflow as your workflow management platform
- 14. @ItaiYaffe, @RTeveth Nielsen Identity ● Data and Measurement company ● Media consumption ● Single source of truth of individuals and households ○ Unifies many proprietary datasets ○ Generates holistic view of a consumer
- 15. @ItaiYaffe, @RTeveth Nielsen Identity in numbers >10B events/day 60TB/day S3 6000’s nodes/day 10’s of TB ingested/day druid
- 16. @ItaiYaffe, @RTeveth The challenges Scalability Cost Efficiency Fault-tolerance
- 17. @ItaiYaffe, @RTeveth Why do we need Airflow? ● Dozens of ETL workflows running around the clock ● Originally used AWS Data Pipeline for workflow management ● But we also wanted: ○ Better visibility of configuration and workflow ○ Better monitoring and statistics ○ Share common configuration/code between workflows
- 18. @ItaiYaffe, @RTeveth Why do we Airflow? ~20 automatic DAG deployments/day ~1000 DAG Runs/day ~2 years in production Met all requirements & more ~40 users across 4 groups 6 contributions to open-source
- 19. @ItaiYaffe, @RTeveth Common data pipeline pattern - Airflow DAG
- 20. @ItaiYaffe, @RTeveth Common data pipeline pattern - high-level architecture 1. Read input files Data Lake 2. Write output files 3. Ingest to DB Intermediate StorageData Processing OLAP
- 21. @ItaiYaffe, @RTeveth Spark clusters ● Available cluster managers ○ Mesos, YARN, Standalone and K8s ● Managed Spark on public clouds ○ AWS EMR, Databricks, GCP Dataproc, etc.
- 22. @ItaiYaffe, @RTeveth Common data pipeline pattern - high-level architecture 1. Read input files Data Lake 2. Write output files 3. Ingest to DB Intermediate StorageData Processing OLAP
- 23. @ItaiYaffe, @RTeveth What is EMR? EMR is an AWS managed service to run Hadoop & Spark clusters
- 24. @ItaiYaffe, @RTeveth What is EMR? EMR is an AWS managed service to run Hadoop & Spark clusters Allows you to reduce costs by using Spot instances
- 25. @ItaiYaffe, @RTeveth What is EMR? EMR is an AWS managed service to run Hadoop & Spark clusters Allows you to reduce costs by using Spot instances Charges management cost for each instance in a cluster
- 26. @ItaiYaffe, @RTeveth EMR pricing - example Cluster Cost $1000
- 27. @ItaiYaffe, @RTeveth EMR pricing - example* Cluster Cost * Based on current i3.8xlarge Spot pricing. This may vary depending on the region, instance type, etc. EC2 Cost $1000 = $650
- 28. @ItaiYaffe, @RTeveth EMR pricing - example* Cluster Cost * Based on current i3.8xlarge Spot pricing. This may vary depending on the region, instance type, etc. EC2 Cost EMR Cost $1000 = $650 + $350
- 29. @ItaiYaffe, @RTeveth Running Airflow-based Spark jobs on EMR ● EMR has official Airflow support ● Open-source, remember? ○ Allows us to fix existing components ■ EmrStepSensor fixes (AIRFLOW-3297) ○ … As well as add new components ■ AWS Athena Sensor (AIRFLOW-3403) ■ OpenFaaS hook (AIRFLOW-3411) emr_create_job_flow_operator emr_add_steps_operator emr_step_sensor Creates new emr cluster Adds Spark step to the cluster Checks if the step succeeded
- 30. @ItaiYaffe, @RTeveth Running Airflow-based Spark jobs on EMR ● EMR has official Airflow support ● Open-source, remember? ○ Allows us to fix existing components ■ EmrStepSensor fixes (AIRFLOW-3297) ○ … As well as add new components ■ AWS Athena Sensor (AIRFLOW-3403) ■ OpenFaaS hook (AIRFLOW-3411) emr_create_job_flow_operator emr_add_steps_operator emr_step_sensor Creates new emr cluster Adds Spark step to the cluster Checks if the step succeeded This was great...
- 31. @ItaiYaffe, @RTeveth But we wanted MORE! $$$ Visibility Robustness
- 32. @ItaiYaffe, @RTeveth Introducing - Spark-on-Kubernetes +
- 33. @ItaiYaffe, @RTeveth Let’s explain what is Kubernetes (a.k.a K8s) ● Open source platform for running and managing containerized workloads ● Includes ○ Built-in controllers to support various workloads (e.g micro-services) ○ Additional extensions (called “operators”) to support custom workloads ● Highly scalable
- 34. @ItaiYaffe, @RTeveth Basic Kubernetes terminology ClusterControl plane Worker nodes (EC2 in our case) Pods group of one or more containers (such as Docker containers)
- 35. @ItaiYaffe, @RTeveth Basic Kubernetes terminology ● kubectl - K8s CLI
- 36. @ItaiYaffe, @RTeveth Basic Kubernetes terminology ● The term “operator” exists both in Airflow and in Kubernetes
- 37. @ItaiYaffe, @RTeveth Basic Kubernetes terminology ● The term “operator” exists both in Airflow and in Kubernetes ● operator ○ Represents a single task ○ Operators determine what is actually executed when your DAG runs ○ Example: ■ bash-operator - executes a bash command
- 38. @ItaiYaffe, @RTeveth Basic Kubernetes terminology ● The term “operator” exists both in Airflow and in Kubernetes ● operator ○ Additional extensions to Kubernetes ○ Holds the knowledge of how to manage a specific application ○ Example: ■ postgres-operator - defines and manages a PostgreSQL cluster
- 39. @ItaiYaffe, @RTeveth Basic Kubernetes terminology ● The term “operator” exists both in Airflow and in Kubernetes ● operator ○ A non-core Kubernetes controller ○ Holds the knowledge of how to manage a specific application ○ Example: ■ postgres-operator - defines and manages a PostgreSQL cluster Operator != Operator
- 40. @ItaiYaffe, @RTeveth Kubernetes auto-scale ClusterControl plane Phase 1: no applications are running on the cluster
- 41. @ItaiYaffe, @RTeveth Kubernetes auto-scale ClusterControl plane Phase 2: application #1 starts running
- 42. @ItaiYaffe, @RTeveth Kubernetes auto-scale ClusterControl plane Phase 3: the cluster scales-up as needed
- 43. @ItaiYaffe, @RTeveth Kubernetes auto-scale ClusterControl plane Phase 4: application #2 starts running
- 44. @ItaiYaffe, @RTeveth Kubernetes auto-scale ClusterControl plane Phase 5: the cluster scales-up as needed
- 45. @ItaiYaffe, @RTeveth Kubernetes auto-scale ClusterControl plane Phase 6: applications finished running, cluster scales down
- 46. @ItaiYaffe, @RTeveth Kubernetes in a nutshell ● A platform for running and managing containerized workloads ● Each cluster has ○ 1 control plane ○ 0..X worker nodes ○ 0..Y pods ○ 0..Z applications running concurrently ● Kubernetes operator != Airflow operator ● Automatically scales out and in
- 47. @ItaiYaffe, @RTeveth Cool, so… Back to Spark-on-Kubernetes?
- 48. @ItaiYaffe, @RTeveth Spark-On-Kubernetes overview ● From Spark 2.3.0, K8s is supported as a cluster manager ● No additional management cost per instance ○ You only pay a small fee for the K8s cluster itself (e.g $60/month on AWS) ● This is still experimental, and some features are missing ○ E.g Dynamic Resource Allocation and External Shuffle Service
- 49. @ItaiYaffe, @RTeveth Submitting a Spark application to Kubernetes - alternatives 1. Using spark-submit script 2. Using Spark-On-Kubernetes Operator
- 50. @ItaiYaffe, @RTeveth Spark-submit example - SparkPi ./bin/spark-submit --master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> --deploy-mode cluster --name spark-pi --class org.apache.spark.examples.SparkPi --conf spark.executor.instances =3 --conf spark.kubernetes.container.image =<spark-image> local:///path/to/examples.jar
- 51. @ItaiYaffe, @RTeveth Spark-submit example - SparkPi ./bin/spark-submit --master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> --deploy-mode cluster --name spark-pi --class org.apache.spark.examples.SparkPi --conf spark.executor.instances =3 --conf spark.kubernetes.container.image =<spark-image> local:///path/to/examples.jar
- 52. @ItaiYaffe, @RTeveth Spark-submit example - SparkPi ./bin/spark-submit --master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> --deploy-mode cluster --name spark-pi --class org.apache.spark.examples.SparkPi --conf spark.executor.instances =3 --conf spark.kubernetes.container.image =<spark-image> local:///path/to/examples.jar Kubernetes control plane Kubernetes cluster SparkPi driver Executor 1 Executor 2 Executor 3
- 53. @ItaiYaffe, @RTeveth Spark-On-Kubernetes operator ● A Kubernetes operator ● Extends Kubernetes API to support Spark applications natively ● Built by GCP as an open-source project github.com/GoogleCloudPlatform/spark-on-k8s-operator
- 54. @ItaiYaffe, @RTeveth Spark-On-Kubernetes operator example - SparkPi apiVersion: "sparkoperator.k8s.io/v1beta2" kind: SparkApplication metadata: name: "spark-pi” namespace: default spec: ... driver: ... executor: ... Spark-pi.yaml
- 55. @ItaiYaffe, @RTeveth Spark-On-Kubernetes operator example - SparkPi apiVersion: "sparkoperator.k8s.io/v1beta2" kind: SparkApplication metadata: name: "spark-pi” namespace: default spec: ... driver: ... executor: ... Spark-pi.yaml Kubernetes control plane Kubernetes cluster kubectl Spark- on-K8s operator
- 56. @ItaiYaffe, @RTeveth Spark-On-Kubernetes operator example - SparkPi apiVersion: "sparkoperator.k8s.io/v1beta2" kind: SparkApplication metadata: name: "spark-pi” namespace: default spec: ... driver: ... executor: ... Spark-pi.yaml Kubernetes control plane Kubernetes cluster SparkPi driver Executor 1 Executor 2 Executor 3 kubectl Spark- on-K8s operator
- 57. @ItaiYaffe, @RTeveth Submitting a Spark application to K8s Topic Spark-submit Airflow built-in integration V Customize Spark-pods X* Easy access to Spark UI X Submit and view application from kubectl X
- 58. @ItaiYaffe, @RTeveth Submitting a Spark application to K8s Topic Spark-submit Spark-On-K8s operator Airflow built-in integration V X Customize Spark-pods X* V Easy access to Spark UI X V Submit and view application from kubectl X V
- 59. @ItaiYaffe, @RTeveth Integrate it with Airflow
- 60. @ItaiYaffe, @RTeveth So… we decided to take the road less traveled
- 61. @ItaiYaffe, @RTeveth So… we decided to take the road less traveled github.com/apache/airflow/pull/7163
- 62. @ItaiYaffe, @RTeveth A special thanks to Airflow committers @CzerwonyElmo (Kamil Breguła) @kaxil (Kaxil Naik) @AshBerlin (Ash Berlin-Taylor) @higrys (Jarek Potiuk)
- 63. @ItaiYaffe, @RTeveth Airflow SparkKubernetes integration KubernetesHook SparkKubernetes operator SparkKubernetes sensor
- 64. @ItaiYaffe, @RTeveth What have we gained by building this integration? ● Official built-in Airflow support ● Security ○ Save Kubernetes credentials inside Airflow connection mechanism ● Portability ○ Use templated Kubernetes object so the same app can be migrated easily to Airflow and also be run manually ● Kubernetes native ○ Communicate directly with the Kubernetes API
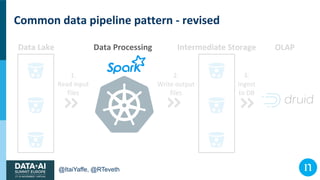
- 65. @ItaiYaffe, @RTeveth Common data pipeline pattern - revised
- 66. @ItaiYaffe, @RTeveth Common data pipeline pattern - revised 1. Read input files Data Lake 2. Write output files 3. Ingest to DB OLAPData Processing Intermediate Storage
- 67. @ItaiYaffe, @RTeveth Common data pipeline pattern - revised 1. Read input files Data Lake 2. Write output files 3. Ingest to DB OLAPData Processing Intermediate Storage
- 68. @ItaiYaffe, @RTeveth Common data pipeline pattern - revised 1. Read input files Data Lake 2. Write output files 3. Ingest to DB OLAPData Processing Intermediate Storage What’s missing?
- 69. @ItaiYaffe, @RTeveth Connecting the dots… making it production-ready
- 70. @ItaiYaffe, @RTeveth Visibility ● Spark History Server ○ Each K8s namespace has a dedicated Spark History Server ● Metrics ○ Spark metrics are exposed via JmxSink (github.com/prometheus/jmx_exporter) ○ System metrics are collected using github.com/kubernetes/kube-state-metrics ● Dashboards ○ Aggregating both Spark and system metrics
- 71. @ItaiYaffe, @RTeveth Visibility ● Logging ○ All logs are collected with Filebeat to Elasticsearch ● Alerting ○ Airflow callbacks emit metrics which trigger alerts when needed
- 72. @ItaiYaffe, @RTeveth Robustness ● Running a Spark job on multiple AZs ○ Can be beneficial when using Spot instances (depending on the amount of shuffling) ● AWS Node Termination Handler ○ Allows K8s to gracefully handle events such as EC2 Spot interruptions ○ Open source (github.com/aws/aws-node-termination-handler)
- 73. @ItaiYaffe, @RTeveth Benefits from migrating to Kubernetes ● ~30% cost reduction ○ No additional cost per instance ● Better visibility ● Robustness
- 74. @ItaiYaffe, @RTeveth Airflow integration current status ● Will be available in Airflow 2.0 ● Can’t wait? Check out the backport package for Airflow 1.10.12 tinyurl.com/y6xb7s3h
- 75. @ItaiYaffe, @RTeveth So with minimal changes...
- 76. @ItaiYaffe, @RTeveth You can boost your data pipeline like me SAVE $10,000’s/month GAIN visibility MAKE your systems robust
- 77. @ItaiYaffe, @RTeveth DRUID ES Want to know more? ● Women in Big Data ○ A world-wide program that aims : ■ To inspire, connect, grow, and champion success of women in the Big Data & analytics field ○ 30+ chapters and 17,000+ members world-wide ○ Everyone can join (regardless of gender), so find a chapter near you - https://www.womeninbigdata.org/wibd-structure/ ● Our Tech Blog - medium.com/nmc-techblog ○ Spark Dynamic Partition Inserts part 1 - https://tinyurl.com/yd94ztz5 ○ Spark Dynamic Partition Inserts Part 2 - https://tinyurl.com/y8uembml
- 78. QUESTIONS
- 79. THANK YOU Roi Teveth Roi Teveth Itai Yaffe Itai Yaffe
- 80. Feedback Your feedback is important to us. Don’t forget to rate and review the sessions.