







































Migration from MySQL to Cassandra for millions of active users
- 1. How did we migrate data for millions of live users from MySQL to Cassandra Andrey Panasyuk, @defascat
- 2. Plan
- 3. Use case Challenges a. Individual b. Corporate
- 4. Servers ● Thousands of servers in prod ● Java 8 ● Tomcat 7 ● Spring 3 ● Hibernate 3
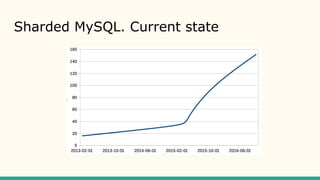
- 6. Sharded MySQL. Current state
- 7. Sharded MySQL. Environment 1. MySQL (Percona Server) 2. Hardware configuration: a. two Intel E2620v2 CPU b. 128GB RAM c. 12x800GB Intel SSD, RAID 10 d. two 2Gb network interfaces (bonded)
- 8. MemcacheD 1. Hibernate a. Query Cache b. Entity Cache 2. 100th of nodes 3. ~100MBps per Memcache node
- 9. Sharded MySQL. Failover 1. master 2. co-master 3. flogger 4. archive X4
- 10. Sharded MySQL. Approach 1. Hibernate changes: a. Patching 2nd level caching: i. +environment ii. -class version b. More info to debug problems c. Fixing bugs 2. Own implementation: a. FitbitTransactional b. ManagedHibernateSession 3. Dynamic sharding concept (somewhat similar to C*)
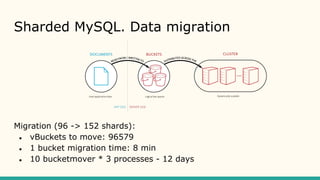
- 11. Sharded MySQL. Data migration Solution: vBucket
- 12. Sharded MySQL. Data migration Migration (96 -> 152 shards): ● vBuckets to move: 96579 ● 1 bucket migration time: 8 min ● 10 bucketmover * 3 processes - 12 days
- 13. Sharded MySQL. Data migration Job ● Setup a. Ensures vbuckets in read-only mode b. Waits for servers to reach consensus ● Execute a. Triggers actions (dump, insert, etc.) on Bucketmover b. Waits for actions to complete ● Wrap-up a. Updates shards for vbuckets, re-opens them for writes b. Advances jobs to next action
- 14. Sharded MySQL. Schema migration 1. Locks during schema update Solution: pt-online-schema-change + protobuf Drawbacks: 1. Split between DML/DDL scripts 2. Binary format (additional data) 3. Additional platform specific tool message Meta { optional string name = 1; optional string intro = 2; ... repeated string requiredFeatures = 32; } message Challenge { optional Meta meta = 1; ... optional CWRace cw_race = 6; }
- 15. Sharded MySQL. Development 1. Job system across shards 2. Use unsharded databases for lookup tables 3. Do not forget about custom annotation @PrimaryEntity(entityType = EntityType.SHARDED_ENTITY)
- 16. Query patterns 1. Create challenge 2. List challenges by user 3. Get challenge team leaderboard by user 4. Post a message 5. List challenge messages 6. Cheer a message
- 17. MySQL. Not a problem 1. Knowledge Base 2. Response Time
- 18. Our problems 1. MySQL a. Scalability b. Fault tolerance c. Schema migration d. Locks 2. Infrastructure cost a. MemcacheD b. Redis
- 19. C* expectations 1. Scalability 2. Quicker fault recovery 3. Easier schema migration 4. Lack of locks
- 20. Migration specifics 1. Millions of real users in prod 2. No downtime
- 22. Apache Cassandra Apache Cassandra is a free and open-source distributed database management system designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. Cassandra offers robust support for clusters spanning multiple datacenters, with asynchronous masterless replication allowing low latency operations for all clients.
- 23. Setting cluster up 1. Performance testing 2. Monitoring 3. Alerting 4. Incremental repairs (CASSANDRA-9935)
- 24. C* tweaks 1. ParNew+CMS -> G1 2. MaxPauseGCMillis = 200ms 3. ParallelGCThreads and ConcGCThreads = 4 4. Compaction 5. gc_grace_seconds = 0 (already big TTL for our data)
- 25. Create keyspaces/tables 1. Almost the same schema with Cassandra adjustments 2. Data denormalization was required in several places
- 26. ID migration 1. Create pseudo-random migration UUID based on BIGINT 2. Thank API designers for using string as object ids. 3. Make sure clients are ready for the new length of the id. 4. Migrate API to UUID all over the place
- 27. DAO (Data Access Object) 1. Create CassandraDAO with the same interface as HibernateDAO 2. Create ProxyAdapterDAO to control which implementation to select 3. Create adapter implementation for each DAO with the same interface as HibernateDAO
- 28. Enable shadow writes (percentage) 1. Introduce environment specific settings for shadow writes 2. Adjust ProxyAdapterDAO code to enable shadow writes by percentage. Various implementations. 3. Analyze performance (StatsD metrics for our code + Cassandra metrics)
- 29. Migrate legacy data 1. Create a new job to read/migrate data 2. Process data in batches
- 30. Start shadow C* reads with validation 1. Environment specific settings for data validation 2. Adjust ProxyAdapterDAO code to enable simultaneous read from MySQL and Cassandra 3. Adjust ProxyAdapterDAO to be able to compare objects 4. Logging & investigating data discrepancy.
- 31. Check validation issues 1. Path a. Fix code problems b. Migrate affected challenges again c. Go to step 1 2. Duration: 1.5 month
- 32. Turn on read from C* 1. Introduce C* return read percentage in the config settings 2. Still do shadow MySQL reads and validations 3. Increase percentage over time
- 33. Turn off writes to MySQL
- 34. Clean-up 1. Adjust places which are not suitable for C* patterns like look through all of the shards. 2. Adjust adapters to get rid of Hibernate DAOs. Adapter hierarchy is still presented 3. Remove obsolete code 4. Clean up MySQL database
- 35. Challenge Events Migration Example 1. Previous attempts: a. SWF + SQS b. MySQL + Job across all shards 2. Now a. Complication due to C* as a queue performance b. 16 threads across 1024 buckets
- 36. Code Redesign. Message cheer example 1. Originally a. Read b. Update BLOB c. Persist 2. Approach a. Update C* set as a single operation
- 37. Code Redesign. Life without transactions 1. BATCH 2. Some object as a single source of truth
- 39. Challenges C*. Current State 1. Two datacenters 2. 18 nodes 3. Hardware a. 24-core CPU b. 64 GB RAM 4. RF: 3
- 40. Results of migration 1. Significant improvement in persistence storage scalability & management (comparing to MySQL RDBMS) 2. Minimizing number of external points of failures 3. Squashing Technical Debt 4. Created a reusable migration module
- 41. Cassandra Inconveniences 1. Lack of ACID transactions 2. MultiDC scenarios require concious decisions for QUORUM/LOCAL_QUORUM. 3. Data denormalization 4. CQL vs SQL limitations 5. Less readable IDs
- 42. Surprisingly not a big deal 1. Lack of JOINs due to the model 2. Lack of aggregation functions due to the model (we’re on 2.1 now) 3. Eventual consistency 4. IDs format change