



![Association Mining with Appiori Algorithm
• Associated rule mining which can help to find out interesting correlations and
dependencies the among the data and it can be also helpful for find frequent item-set
mining.
• Association rule is given in form of D1->D2 which means data D1 is related to the
data D2. If we analyze anything about the data D1 then we need to analyze data D2 as
well otherwise our result will be incomplete.
• In association rules two things are used first is support and second is confidence. Data
D1 and data D2 are interesting if it support [D1 U D2] and confidence [D1->D2] are
equal to or greater than user-defined minimum support value and minimum
confidence.
• Support defines how many time data occurs in particular user id, primary key,
transaction id or any other unique id.](https://image.slidesharecdn.com/lnct-190831144952/85/Mining-on-Relationships-in-Big-Data-era-using-Improve-Apriori-Algorithm-with-MapReduce-Approach-5-320.jpg)






Mining on Relationships in Big Data era using Improve Apriori Algorithm with MapReduce Approach
- 1. Paper Presentation on Mining on Relationships in Big Data era using Improve Apriori Algorithm with MapReduce Approach Kamlesh Kumar Pandey Dept. of Computer Science & Applications Dr. Hari Singh Gour Vishwavidyalaya,Sagar, M.P E-mail: kamleshamkgmail.com International Conference on Advanced Computation and Telecommunication
- 2. Content • Big Data • Big Data with Association Mining • Appiori Algorithm • Proposed Improve Appiori Algorithm Using Map-Reduce
- 3. Big Data • Present time technology is growing very fast. Every originations, industries or person moving towards Internet of things, cloud computing, warless sensor networks, social media, internet. These sources generated a data growing fast in per second, minutes or per hour in size of Terabytes or Petabytes . • Diebold et Al. (2000) is a first writer who discussed the word Big Data in his research paper. All of these authors define Big Data there means if the data set is large then gigabyte then these type of data set is known as Big Data. • Doug Laney et al (2001) was the first person who gave a proper definition for Big Data. He gave three characteristics Volume, Variety, and Velocity of Big Data and these characteristics known as 3 V’s of Big Data Management. If traditional data have met two basic characteristic at a time these data are come to under Big data. • Gartner (2012), “Big data is high-volume, high-velocity and high-variety information assets that demand cost-effective, innovative forms of information processing for enhanced insight and decision making”
- 4. Big Data V’s • In present time seven V’s used for Big Data where the first three V’s Volume, Variety, and Velocity are the main characteristics of big data. In addition to Variability, Value, Veracity, and Visualization are depending on the organization.
- 5. Association Mining with Appiori Algorithm • Associated rule mining which can help to find out interesting correlations and dependencies the among the data and it can be also helpful for find frequent item-set mining. • Association rule is given in form of D1->D2 which means data D1 is related to the data D2. If we analyze anything about the data D1 then we need to analyze data D2 as well otherwise our result will be incomplete. • In association rules two things are used first is support and second is confidence. Data D1 and data D2 are interesting if it support [D1 U D2] and confidence [D1->D2] are equal to or greater than user-defined minimum support value and minimum confidence. • Support defines how many time data occurs in particular user id, primary key, transaction id or any other unique id.
- 6. Appiori Algorithm • Apriori is the most popular algorithm for finding out frequent data items based on candidate and support threshold. • Apriori algorithm takes high I/O cost during the execution because it needs multiple time scan to the database and a large amount of memory because it holds the previous state and holds the result of rescanning on databases.
- 7. Proposed Improve Appiori Algorithm Using Map-Reduce • This proposed algorithm runs parallel to each database used one or more Map and Reduce function in big data framework like Apache Hadoop, Strom, Spark, Ping etc. • This algorithm works on any type of databases with only one time scanning on databases which is advanced as compared to existing Apriori algorithm. This algorithm is not depended on any number of Map or Reduce node.
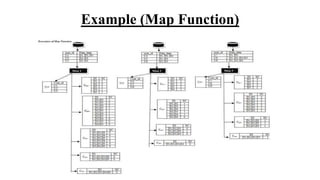
- 8. Algorithm Map Function:- • In the first step, we calculate a total number of user UL available in every node. • In a second step, we find out Cm1, which hold a total number of data D along with their frequent related to the user. This frequent data item is known as support count. In this step we also find out Dc, which hold total number of data used in Cm1. • In the third step, we will combine the data item in a possible combination of DcCk until Cmk != null or K value is greater than to DcCk. Cmk is a matrix which holds to the frequent data item and their support count.
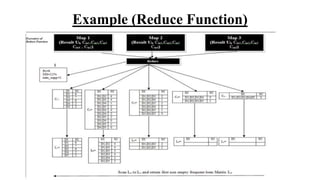
- 10. Algorithm Reduce Function:- • In the fourth step we will find a total number of user Pc in the big data environment using UL matrix and min_support value using (MS/100) * Pc formula where MS is user define minimum support threshold. • In the fifth step we combine all Cmk is separate until finding out Cmk != null and stored all result in candidate k size data item Ck matrix. After that we will remove all data item that are smaller than minimum support value in Ck and store this result in Lk matrix. Lk matrix is known as frequent k size data item matrix, which is suitable for find out related data in the big data environment. • In the last step we scan Lk matrix from Lk to L1 for finding on related data, if we find Lk matrix is nonempty then this matrix is final related data matrix otherwise we check next Lk-1 matrix.
- 12. References 1. Choi Tsan-Ming, Wallace Sten and Wangg Yulan (2017), “Big Data Analytics in Operations Management”, Production and Operations Management (Wiley), Online ISSN: 1937-5956, V-26, I-12. 2. Apiletti Daniele, Baralis Elena, Cerquitelli Tania, Garza Paolo, Pulvirenti Fabio and Venturini Luca (2017), “Frequent Itemsets Mining for Big Data: A Comparative Analysis” , Big Data Research (Elsevier), Online ISSN: 2214-5796 V-9, pp 67-83. 3. Ozkosea Hakan, Arıa Emin Sertac and Gencerb Cevriye (2015): “Yesterday, Today and Tomorrow of Big Data”, Procedia - Social and Behavioral Sciences, Online ISSN 1877-0428, V-195, pp 1042-1050. 4. Sivarajah Uthayasankar and Mustafa Kamal Muhammad (2017): “Critical analysis of Big Data challenges and analytical methods”, Journal of Business Research (Elsevier), V-70, pp 263-286. 5. Gandomi Amir and Haider Murtaza (2015): “Beyond the hype: Big data concepts, methods, and analytics”, International Journal of Information Management, Published by Elsevier, V-35, pp 137-144. 6. Zhang Shichao and Wu Xindong (2011), “Fundamentals of association rules in data mining and knowledge discovery”, WIREs Data Mining and Knowledge Discovery, Online ISSN: 1942-4795, V-1, I-2, pp 97–116. 7. Li Ning, Zeng Li, H Qing and Zhongzhi Shi (2017): “Parallel Implementation of Apriori Algorithm Based on MapReduce”, Proc of 13th ACIS International Conference on Software Engineering, Artificial Intelligence, Networking, and Parallel/Distributed Computing held from 8-10 Aug. 2012 at Kyoto, Japan. 8. Borgelt Christian (2012), “Frequent item set Mining”, WIREs Data Mining and Knowledge Discovery, Online ISSN: 1942-4795, V- 2, I-6, pp 437– 456. 9. Viger Philippe Fournier, Lin Wei Jerry, Vo Bay, Chi Tin Truong, Zhang Ji and Le Hoai Bac (2017), “A survey of itemset mining”, WIREs Data Mining and Knowledge Discovery, Online ISSN: 1942-4795, V-7, I-4, pp 1-18. 10. Singh Sudhakar, Garg Rakhi, Mishra P K (2014), “Review of Apriori Based Algorithms on MapReduce Framework”, Proc of International Conference on Communication and Computing at Bangalore, India, pp. 593–604.