










































ML_Lec2 introduction to data processing.pdf
- 2. Agenda Revision Data Preprocessing. Data cleaning Dealing with missing data. Dealing with categorical data. Feature scaling ▪ Rescaling ▪ Mean normalization ▪ Standardization ▪ Scaling to unit length Dimensionality reduction ▪ Feature selection ▪ Feature extraction Partitioning a dataset in training and testing sets
- 3. Revision Learning In machine learning, pattern recognition and learning there is a relationship/nature between the observations (input features) and response (target), we need to understand this relationship . ❑ Learning ▪ The learning process tends to understand and predict new values based on finding a mathematical model and a relationship between the given observations ( i.e. inputs and output). ❑ Examples of learning problems: ❑ Predict a wind speed and a solar radiation. ❑ Detection of cancers; Breast, Leukemia and Spinal cancers. ❑ Estimate the amount of glucose in the blood.
- 4. Data Preprocessing Introduction The quality of the data and the amount of useful information that it contains are key factors that determine how well a machine learning algorithm can learn. Therefore, it is absolutely critical that we make sure to examine and preprocess a dataset before we feed it to a learning algorithm. we will discuss the essential data preprocessing techniques that will help us to build good machine learning models.
- 5. Data Preprocessing technique is used to manipulate and transform the raw dataset into a clean and scaled dataset. In other words, whenever the dataset is gathered from different sources it is collected in raw format which is not feasible for the analysis. Therefore, certain steps are executed to convert the dataset into a small clean dataset. The data preprocessing technique is performed before the uses of the collected dataset. Data Preprocessing Introduction
- 6. Data Cleaning Feature Scaling Dimensionality Reduction Data Preprocessing Introduction
- 7. Data Preprocessing Why we need to the data preprocessing process? The main objectives of data preprocessing are to manipulate and transform raw data into cleaned and scaled format. In addition it is important to compress the data onto a smaller dimensional subspace while retaining most of the relevant information.
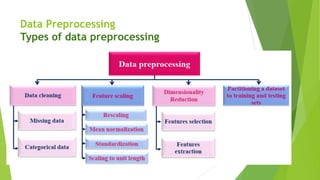
- 8. Data Preprocessing Types of data preprocessing
- 9. Data Preprocessing Data cleaning: missing data In real-world applications are familiar that the collected data samples contain one or more missing values for various reasons. These reasons include: There could have been an error in the data collection process certain measurements are not applicable and particular fields could have been simply left blank in a survey, for instance. We typically see missing values as the blank spaces in our data table or as placeholder strings such as NaN (Not A Number).
- 10. Data Preprocessing Data cleaning: missing data
- 11. Data Preprocessing Data cleaning: missing data
- 12. Data Preprocessing Data cleaning: missing data
- 13. Data Preprocessing Data cleaning: missing data
- 14. Data Preprocessing Data cleaning: categorical data
- 15. Data Preprocessing Data cleaning: categorical data
- 16. Data Preprocessing Data cleaning: categorical data
- 17. Data Preprocessing Data cleaning: categorical data
- 18. Data Preprocessing Data cleaning: categorical data
- 19. Data Preprocessing Data cleaning: categorical data
- 20. Data Preprocessing Data cleaning: categorical data
- 30. Data Preprocessing Feature scaling: rescaling
- 31. Data Preprocessing Feature scaling: rescaling
- 32. Data Preprocessing Feature scaling: mean normalization
- 33. Data Preprocessing Feature scaling: standardization
- 34. Data Preprocessing Feature scaling: scaling to unit length
- 36. Data Preprocessing Partitioning a dataset in training and testing sets
- 37. Data Preprocessing Partitioning a dataset in training and testing sets
- 38. Data Preprocessing Partitioning a dataset in training and testing sets
- 39. Data Preprocessing Partitioning a dataset in training and testing sets
- 40. Data Preprocessing Partitioning a dataset in training and testing sets