Real-Time Integration Between MongoDB and SQL Databases
8 likes•2,976 views

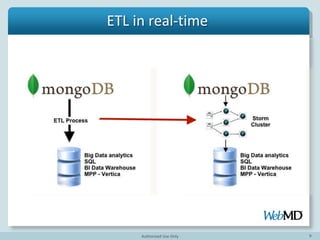
This document describes how WebMD uses Apache Storm to build a real-time data pipeline that moves data from MongoDB to SQL databases. A Storm topology is constructed with a spout that reads continuously from the MongoDB oplog and emits tuples. These tuples are then processed by bolts that extract fields from embedded arrays, parse documents, and write the data to SQL databases. This pipeline allows for real-time analytics on user activity data stored in MongoDB to be performed using SQL queries. The topology scales easily to handle increasing data volumes and velocities.



































![43
{"ns": "people", "op":"i",
o : {
_id: 1,
name: { first: 'John', last:
'Backus' },
birth: 'Dec 03, 1924’
}
["ns": "people", "op":"i",
“_id”:1,
"name_first": "John",
"name_last":"Backus",
"birth": "DEc 03, 1924"
]
Parse documents with Bolt](https://image.slidesharecdn.com/mongodb2013stormv3-130610104215-phpapp02/85/Real-Time-Integration-Between-MongoDB-and-SQL-Databases-43-320.jpg)


![46
Write to SQL with SQLWriter Bolt
["ns": "people", "op":"i",
“_id”:1,
"name_first": "John",
"name_last":"Backus",
"birth": "Dec 03, 1924"
]
insert into people (_id,name_first,name_last,birth) values
(1,'John','Backus','Dec 03,1924') ,
insert into people_awards (_id,awards_award,awards_award,awards_by)
values (1,'Turing Award',1977,'ACM'),
insert into people_awards (_id,awards_award,awards_award,awards_by)
values (1,'National Medal of Science',1975,'National Science Foundation')](https://image.slidesharecdn.com/mongodb2013stormv3-130610104215-phpapp02/85/Real-Time-Integration-Between-MongoDB-and-SQL-Databases-46-320.jpg)









Real-Time Integration Between MongoDB and SQL Databases
- 1. 1 Distributed, fault-tolerant, transactional Real-Time Integration: MongoDB and SQL Databases Eugene Dvorkin Architect, WebMD
- 2. 2 WebMD: A lot of data; a lot of traffic ~900 millions page view a month ~100 million unique visitors a month
- 3. 3 How We Use MongoDB User Activity
- 4. 4 Why Move Data to RDBMS? Preserve existing investment in BI and data warehouse To use analytical database such as Vertica To use SQL
- 5. 5 Why Move Data In Real-time? Batch process is slow No ad-hoc queries No real-time reports
- 6. 6 Challenge in moving data Transform Document to Relational Structure Insert into RDBMS at high rate
- 7. 7 Challenge in moving data Scale easily as data volume and velocity increase
- 8. 8 Our Solution to move data in Real-time: Storm tem.Storm – open source distributed real- time computation system. Developed by Nathan Marz - acquired by Twitter
- 9. 9 Hadoop Storm Our Solution to move data in Real-time: Storm
- 10. 10 Why STORM? JVM-based framework Guaranteed data processing Supports development in multiple languages Scalable and transactional Easy to learn and use
- 11. 11 Overview of Storm cluster Master Node Cluster Coordination run worker processes
- 12. 12 Storm Abstractions Tuples, Streams, Spouts, Bolts and Topologies
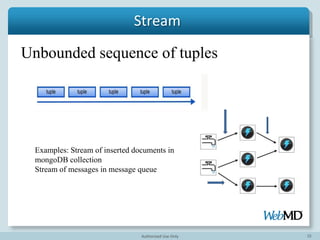
- 14. 14 Stream Unbounded sequence of tuples Example: Stream of messages from message queue
- 15. 15 Spout Read from stream of data – Queues, web logs, API calls, mongoDB oplog Emit documents as tuples Source of Streams
- 16. 16 Bolts Process tuples and create new streams
- 17. 17 Bolts Apply functions /transforms Calculate and aggregate data (word count!) Access DB, API , etc. Filter data Map/Reduce Process tuples and create new streams
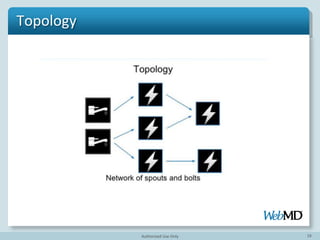
- 18. 18 Topology
- 19. 19 Topology Storm is transforming and moving data
- 20. 20 MongoDB How To Read All Incoming Data from MongoDB?
- 21. 21 MongoDB How To Read All Incoming Data from MongoDB? Use MongoDB OpLog
- 22. 22 What is OpLog? Replication mechanism in MongoDB It is a Capped Collection
- 23. 23 Spout: reading from OpLog Located at local database, oplog.rs collection
- 24. 24 Spout: reading from OpLog Operations: Insert, Update, Delete
- 25. 25 Spout: reading from OpLog Name space: Table – Collection name
- 26. 26 Spout: reading from OpLog Data object:
- 28. 28 Automatic discovery of sharded cluster
- 29. 29 Example: Shard vs Replica set discovery
- 31. 31 Spout: Reading data from OpLog How to Read data continuously from OpLog?
- 32. 32 Spout: Reading data from OpLog How to Read data continuously from OpLog? Use Tailable Cursor
- 33. 33 Example: Tailable cursor - like tail –f
- 34. 34 Manage timestamps Use ts (timestamp in oplog entry) field to track processed records If system restart, start from recorded ts
- 35. 35 Spout: reading from OpLog
- 36. 36 SPOUT – Code Example
- 37. 37 TOPOLOGY
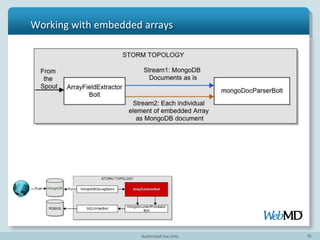
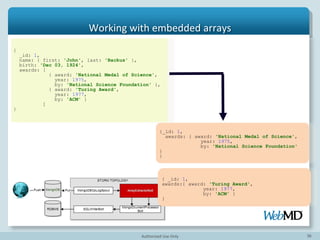
- 38. 38 Working With Embedded Arrays Array represents One-to-Many relationship in RDBMS
- 39. 39 Example: Working with embedded arrays
- 40. 40 Example: Working with embedded arrays {_id: 1, ns: “person_awards”, o: { award: 'National Medal of Science', year: 1975, by: 'National Science Foundation' } } { _id: 1, ns: “person_awards”, o: {award: 'Turing Award', year: 1977, by: 'ACM' } }
- 41. 41 Example: Working with embedded arrays public void execute(Tuple tuple) { ......... if (field instanceof BasicDBList) { BasicDBObject arrayElement=processArray(field) ...... outputCollector.emit("documents", tuple, arrayElement);
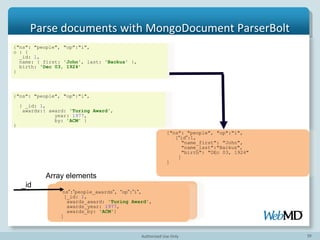
- 42. 42 Parse documents with Bolt
- 43. 43 {"ns": "people", "op":"i", o : { _id: 1, name: { first: 'John', last: 'Backus' }, birth: 'Dec 03, 1924’ } ["ns": "people", "op":"i", “_id”:1, "name_first": "John", "name_last":"Backus", "birth": "DEc 03, 1924" ] Parse documents with Bolt
- 44. 44 @Override public void execute(Tuple tuple) { ...... final BasicDBObject oplogObject = (BasicDBObject)tuple.getValueByField("document"); final BasicDBObject document = (BasicDBObject)oplogObject.get("o"); ...... outputValues.add(flattenDocument(document)); outputCollector.emit(tuple,outputValues); Parse documents with Bolt
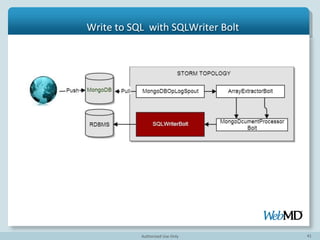
- 45. 45 Write to SQL with SQLWriter Bolt
- 46. 46 Write to SQL with SQLWriter Bolt ["ns": "people", "op":"i", “_id”:1, "name_first": "John", "name_last":"Backus", "birth": "Dec 03, 1924" ] insert into people (_id,name_first,name_last,birth) values (1,'John','Backus','Dec 03,1924') , insert into people_awards (_id,awards_award,awards_award,awards_by) values (1,'Turing Award',1977,'ACM'), insert into people_awards (_id,awards_award,awards_award,awards_by) values (1,'National Medal of Science',1975,'National Science Foundation')
- 47. 47 @Override public void prepare(.....) { .... Class.forName("com.vertica.jdbc.Driver"); con = DriverManager.getConnection(dBUrl, username,password); @Override public void execute(Tuple tuple) { String insertStatement=createInsertStatement(tuple); try { Statement stmt = con.createStatement(); stmt.execute(insertStatement); stmt.close(); Write to SQL with SQLWriter Bolt
- 48. 48 Topology Definition TopologyBuilder builder = new TopologyBuilder(); // define our spout builder.setSpout(spoutId, new MongoOpLogSpout("mongodb://", opslog_progress) builder.setBolt(arrayExtractorId ,new ArrayFieldExtractorBolt(),5).shuffleGrouping(spoutId) builder.setBolt(mongoDocParserId, new MongoDocumentParserBolt()).shuffleGrouping(arrayExtractorId, documentsStreamId) builder.setBolt(sqlWriterId, new SQLWriterBolt(rdbmsUrl,rdbmsUserName,rdbmsPassword)).shuffle Grouping(mongoDocParserId) LocalCluster cluster = new LocalCluster(); cluster.submitTopology("test", conf, builder.createTopology());
- 49. 49 Topology Definition TopologyBuilder builder = new TopologyBuilder(); // define our spout builder.setSpout(spoutId, new MongoOpLogSpout("mongodb://", opslog_progress) builder.setBolt(arrayExtractorId ,new ArrayFieldExtractorBolt(),5).shuffleGrouping(spoutId) builder.setBolt(mongoDocParserId, new MongoDocumentParserBolt()).shuffleGrouping(arrayExtractorId ,documentsStreamId) builder.setBolt(sqlWriterId, new SQLWriterBolt(rdbmsUrl,rdbmsUserName,rdbmsPassword)).shuffl eGrouping(mongoDocParserId) LocalCluster cluster = new LocalCluster(); cluster.submitTopology("test", conf, builder.createTopology());
- 50. 50 Topology Definition TopologyBuilder builder = new TopologyBuilder(); // define our spout builder.setSpout(spoutId, new MongoOpLogSpout("mongodb://", opslog_progress) builder.setBolt(arrayExtractorId ,new ArrayFieldExtractorBolt(),5).shuffleGrouping(spoutId) builder.setBolt(mongoDocParserId, new MongoDocumentParserBolt()).shuffleGrouping(arrayExtractorId, documentsStreamId) builder.setBolt(sqlWriterId, new SQLWriterBolt(rdbmsUrl,rdbmsUserName,rdbmsPassword)).shuffle Grouping(mongoDocParserId) LocalCluster cluster = new LocalCluster(); cluster.submitTopology("test", conf, builder.createTopology());
- 51. 51 Topology Definition TopologyBuilder builder = new TopologyBuilder(); // define our spout builder.setSpout(spoutId, new MongoOpLogSpout("mongodb://", opslog_progress) builder.setBolt(arrayExtractorId ,new ArrayFieldExtractorBolt(),5).shuffleGrouping(spoutId) builder.setBolt(mongoDocParserId, new MongoDocumentParserBolt()).shuffleGrouping(arrayExtractorId, documentsStreamId) builder.setBolt(sqlWriterId, new SQLWriterBolt(rdbmsUrl,rdbmsUserName,rdbmsPassword)).shuffle Grouping(mongoDocParserId) StormSubmitter.submitTopology("OfflineEventProcess", conf,builder.createTopology())
- 52. 52 Lesson learned By leveraging MongoDB Oplog or other capped collection, tailable cursor and Storm framework, you can build fast, scalable, real-time data processing pipeline.
- 53. 53 Resources Book: Getting started with Storm Storm Project wiki Storm starter project Storm contributions project Running a Multi-Node Storm cluster tutorial Implementing real-time trending topic A Hadoop Alternative: Building a real-time data pipeline with Storm Storm Use cases
- 54. 54 Resources (cont’d) Understanding the Parallelism of a Storm Topology Trident – high level Storm abstraction A practical Storm’s Trident API Storm online forum Mongo connector from 10gen Labs MoSQL streaming Translator in Ruby Project source code New York City Storm Meetup
- 55. 55 Questions Eugene Dvorkin, Architect, WebMD [email protected] Twitter: @edvorkin LinkedIn: eugenedvorkin
Editor's Notes
- #3: Leading source of health and medical information.
- #4: Data is rawData is immutable, data is trueDynamic personalized marketing campaigns
- #14: Main data structure in stormNamed list of value where each valuecan be of any typeTyple know ho to serialize primitive data types, string and byte arrays. For any other type Register serializer for this type
- #24: The oplog is a capped collection that lives in a database called local on every replicating node and records all changes to the data. Every time a client writes to the primary, an entry with enough information to reproduce the write is automatically added to the primary’s oplog. Once the write is replicated to a given secondary, that secondary’s oplog also stores a record of the write. Each oplog entry is identified with a BSON timestamp, and all secondaries use the timestamp to keep track of the latest entry they’ve applied.
- #29: How do you now if you connected to shard cluster
- #36: Use mongo Oplog as a queue
- #37: Spout extend interface
- #40: Awards array in Person document – converted into 2 documents with id as of parent document Id
- #41: Awards array – converted into 2 documents with id as of parent document Id. Name space will be used later to insert data into correct table on SQL side
- #42: Instance of BasicDBList in Java
- #44: Flatten out your document structure – use loop or recursion to flatten it outHopefully you don’t have deeply nested documents, which against mongoDB guidelines for schema design
- #48: Use tickle tuples and update in batches
- #49: Local mode vs prod mode
- #50: Increasing papallelization of the bolt. Let say You want 5 bolts to process your array, because it more time consuming operation or you want more SQLWtirerBolts,Because it takes long time to insert data, then use parallelization hint parameters in bolt definition.System will create correspponding number of workers to process your request.
- #51: Local mode vs prod mode
- #52: Local mode vs prod mode