MongoDB & Spark
Download as PPTX, PDF19 likes3,707 views

The document discusses the integration of MongoDB with Apache Spark, focusing on data processing techniques and configurations. It outlines various components of the ecosystem like HDFS, YARN, Hive, and Pig, as well as concepts like resilient distributed datasets and transformations/actions in Spark. Additionally, it references code examples for implementing Spark with MongoDB and notes from a correspondence regarding plays and related information.




























































MongoDB & Spark
- 29. Transformation s Parellelize = x t(x) = x’ t(x’) = x’’
- 30. Transformations filter( func ) union( func ) intersection( set ) distinct( n ) map( function )
- 31. Action f(x’’) = yParellelize = x t(x) = x’ t(x’) = x’’
- 32. Actions collect() count() first() take( n ) reduce( function )
- 33. Lineage f(x’’) = yParellelize = x t(x) = x’ t(x’) = x’’
- 35. Transform Transform ActionParallelize Transform Transform ActionParallelize Transform Transform ActionParallelize Transform Transform ActionParallelize Transform Transform ActionParallelize Lineage
- 36. Transform Transform ActionParallelize Transform Transform ActionParallelize Transform Transform ActionParallelize Transform Transform ActionParallelize Transform Transform ActionParallelize Lineage
- 37. Transform Transform ActionParallelize Transform Transform ActionParallelize Transform Transform ActionParallelize Transform Transform ActionParallelize Transform Transform ActionParallelize Lineage
- 39. { "_id" : ObjectId("4f16fc97d1e2d32371003e27"), "body" : "the scrimmage is still up in the air. "subFolder" : "notes_inbox", "mailbox" : "bass-e", "filename" : "450.", "headers" : { "X-cc" : "", "From" : "[email protected]", "Subject" : "Re: Plays and other information", "X-Folder" : "Eric_Bass_Dec2000Notes FoldersNotes inbox", "Content-Transfer-Encoding" : "7bit", "X-bcc" : "", "To" : "[email protected]", "X-Origin" : "Bass-E", "X-FileName" : "ebass.nsf", "X-From" : "Michael Simmons", "Date" : "Tue, 14 Nov 2000 08:22:00 -0800 (PST)", "X-To" : "Eric Bass", "Message-ID" : "<6884142.1075854677416.JavaMail.evans@thyme>", "Content-Type" : "text/plain; charset=us-ascii", "Mime-Version" : "1.0" } }
- 40. { "_id" : ObjectId("4f16fc97d1e2d32371003e27"), "body" : "the scrimmage is still up in the air. "subFolder" : "notes_inbox", "lfpwoojjf0wig=-i1qf=q0qif0=i38 -00 1-8" : "bass-e", "filename" : "450.", "headers" : { "X-cc" : "", "From" : "[email protected]", "Subject" : "Re: Plays and other information", "X-Folder" : "Eric_Bass_Dec2000Notes FoldersNotes inbox", "Content-Transfer-Encoding" : "7bit", "X-bcc" : "", "To" : "[email protected]", "X-Origin" : "Bass-E", "X-FileName" : "ebass.nsf", "X-From" : "Michael Simmons", "Date" : "Tue, 14 Nov 2000 08:22:00 -0800 (PST)", "X-To" : "Eric Bass", "Message-ID" : "<6884142.1075854677416.JavaMail.evans@thyme>", "Content-Type" : "text/plain; charset=us-ascii", "Mime-Version" : "1.0" }
- 41. { _id : "[email protected]|[email protected]", value : 2 } { _id : "[email protected]|[email protected]", value : 2 } { _id : "[email protected]|[email protected]", value : 2 }
- 43. Spark Configuration Configuration conf = new Configuration(); conf.set( "mongo.job.input.format", "com.mongodb.hadoop.MongoInputFormat” ); conf.set( "mongo.input.uri", "mongodb://localhost:27017/db.collection” );
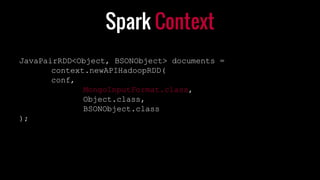
- 44. Spark Context JavaPairRDD<Object, BSONObject> documents = context.newAPIHadoopRDD( conf, MongoInputFormat.class, Object.class, BSONObject.class );
- 45. Spark Context JavaPairRDD<Object, BSONObject> documents = context.newAPIHadoopRDD( conf, MongoInputFormat.class, Object.class, BSONObject.class );
- 46. Spark Context JavaPairRDD<Object, BSONObject> documents = context.newAPIHadoopRDD( conf, MongoInputFormat.class, Object.class, BSONObject.class );
- 47. Spark Context JavaPairRDD<Object, BSONObject> documents = context.newAPIHadoopRDD( conf, MongoInputFormat.class, Object.class, BSONObject.class );
- 48. Spark Context JavaPairRDD<Object, BSONObject> documents = context.newAPIHadoopRDD( conf, MongoInputFormat.class, Object.class, BSONObject.class );
- 50. Deployment Artifacts Hadoop Connector Jar Fat Jar Java Driver Jar
- 51. Spark Submit /usr/local/spark-1.5.1/bin/spark-submit --class com.mongodb.spark.examples.DataframeExample --master local Examples-1.0-SNAPSHOT.jar
- 53. JavaRDD<Message> messages = documents.map ( new Function<Tuple2<Object, BSONObject>, Message>() { public Message call(Tuple2<Object, BSONObject> tuple) { BSONObject header = (BSONObject)tuple._2.get("headers"); Message m = new Message(); m.setTo( (String) header.get("To") ); m.setX_From( (String) header.get("From") ); m.setMessage_ID( (String) header.get( "Message-ID" ) ); m.setBody( (String) tuple._2.get( "body" ) ); return m; } } );
- 54. MognoDB & Spack code demo
- 55. THE FUTURE AND BEYOND THE INFINITE
- 60. MongoDB + Spark
- 61. THANKS! { name: ‘Bryan Reinero’, role: ‘Developer Advocate’, twitter: ‘@blimpyacht’, email: ‘[email protected]’ }