Multiprocessing operating systems
6 likes•7,510 views

The research document by JK Chathurangi Shyalika discusses the significance and technological advancements of multiprocessing operating systems, highlighting their architectural issues, applications, advantages, disadvantages, and future trends. It elaborates on various multiprocessing models including Asymmetric and Symmetric Multi-Processing, along with detailed explanations of multiprocessor hardware configurations such as UMA and NUMA. Furthermore, the report compiles real-world examples and provides insights into the role of multiprocessing in the evolving landscape of information technology.
























![25
Heterogeneous computing
- Heterogeneous computing refers to systems that use more than one kind of processor.
- Usually heterogeneity in the context of computing referred to different instruction
set architectures (ISA), where the main processor has one and the rest have another,
usually a very different architecture (maybe more than one), not just a different micro
architecture (floating point number processing is a special case
- The level of heterogeneity in modern computing systems gradually rises as increases in
chip area and further scaling of fabrication technologies allows for formerly discrete
components to become integrated parts of a system-on-chip.
ARM big. LITTLE
- It is a heterogeneous computing architecture developed by ARM Holdings, coupling
(relatively) slower, and low-power processor cores with (relatively) more powerful and
power-hungry ones.
- The intention is to create a multi-core processor that can adjust better to dynamic
computing needs and use less power than clock scaling alone.
- Finer-grained control of workloads that are migrated between cores. Because the
scheduler is directly migrating tasks between cores, kernel overhead is reduced and power
savings can be correspondingly increased.
- Implementation in the scheduler also makes switching decisions faster than in the
framework implemented in IKS.
Tegra
- Tegra is a system on a chip series developed for mobile devices such
as smartphones, personal digital assistants, andmobile Internet devices.
- The Tegra integrates an ARM architecture central processing unit (CPU), graphics
processing unit (GPU),northbridge, southbridge, and memory controller onto one package
- The second generation TegraSoC has a dual-core ARM Cortex-A9 CPU an ultra-low
power (ULP) GeForce GPU with 4 pixel shaders + 4 vertex shaders,[14] a 32-bit single-
channel memory controller with either LPDDR2-600 or DDR2-667 memory, a](https://image.slidesharecdn.com/multiprocessingoperatingsystems-180306112041/85/Multiprocessing-operating-systems-26-320.jpg)
![26
32KB/32KB L1 cache per core and a shared 1MB L2 cache.[15] There is also a version
of the SoC supporting 3D displays; this SoC uses a higher clocked CPU and GPU
BMDFM
- Binary Modular Dataflow Machine) is software, which enables running an application in
parallel on shared memory symmetric multiprocessors (SMP) using the multiple
processors to speed up the execution of single applications.
- MDFM automatically identifies and exploits parallelism due to the static and mainly
DYNAMIC SCHEDULING of the dataflow instruction sequences derived from the
formerly sequential program.
- BMDFM dynamic scheduling subsystem performs an SMP emulation of Tagged-
Token Dataflow Machine to provide the transparent dataflow semantics for the
applications.
Simultaneous multithreading
- It is a technique for improving the overall efficiency of superscalar CPUs with hardware
multithreading. SMT permits multiple independent threads of execution to better utilize
the resources provided by modern processor architectures.
- Multithreading is similar in concept to preemptive multitasking but is implemented at the
thread level of execution in modern superscalar processors.](https://image.slidesharecdn.com/multiprocessingoperatingsystems-180306112041/85/Multiprocessing-operating-systems-27-320.jpg)
























Multiprocessing operating systems
- 2. 1 A research done and published by : JK Chathurangi Shyalika Intake 31 General Sir John Kotelawela Defence University, Rathmalana, Sri Lanka
- 3. 2 Introduction Multiprocessing operating system is a growing application trend in the modern world which has become a novel research topic today. Each and every corner of the Contemporary Information Technology arena, the usage of multiprocessing has become an integral aspect. The technology of multiprocessing is tend to be developed vastly, through adding new cores to the implementation boundaries of multiprocessing. In this research I have provided an introduction to the architectural issues in multiprocessing systems, followed by, their applications in the real world, advantages, disadvantages and discovered solutions for them. And also I have also focused attention on the new trends, experiments on the future multiprocessing. In this report, I have discussed examples from actual architectures and have provided pointers to elaborate the role of Multiprocessing Operating Systems in the research world.
- 4. 3 Table of Contents 1.0 What are multiprocessor operating systems?..............................................................4 2.0 Multiprocessor Hardware............................................................................................5 2.0.1 UMA Bus-Based SMP Architectures......................................................................5 2.0.2 UMA Multiprocessors Using Crossbar Switches....................................................6 2.0.3 UMA Multiprocessors Using Multistage Switching Networks...............................7 2.0.4 NUMA Multiprocessors ..........................................................................................8 3.0 Multiprocessing models and frameworks ...................................................................9 3.0.1 Asymmetric Multi-Processing (AMP).....................................................................9 3.0.2 Symmetric Multi-Processing (SMP) .....................................................................12 3.0.3 AMP and SMP Model Comparisons .....................................................................15 4.0 Multiprocessor Synchronization ...............................................................................16 4.0.1 Spinning versus switching.....................................................................................17 5.0 Multiprocessor Scheduling........................................................................................18 5.0.1 Timesharing...........................................................................................................18 5.0.2 Space Sharing ........................................................................................................19 5.0.3 Interplay between scheduling and IPC ..................................................................20 5.0.4 Gang scheduling ....................................................................................................21 6.0 Applications of multiprocessing systems..................................................................23 6.0.1 Contemporary Multiprocessor Hardware ..............................................................23 6.0.2 Current Technologies of Multiprocessing Systems...............................................24 6.0.3 Current applications of Multiprocessing systems..................................................27 7.0 Advantages, Disadvantages and Solutions................................................................33 7.0.1 Advantages of Multiprocessor Systems ................................................................33 7.0.2 Disadvantages and obstacles of Multiprocessor Systems......................................34 7.0.3 Solutions................................................................................................................38 8.0 New trends of Multiprocessing .................................................................................41 8.0.1 Multiprocessing models and frameworks New trends ..........................................44 8.0.2 Experimental / Future multiprocessor hardware ...................................................46 8.0.3 Experimental / Future multiprocessor systems......................................................47 References ............................................................................................................................49 Conclusion............................................................................................................................50
- 5. 4 1.0 What are multiprocessor operating systems? Multiprocessing operating system refers to a computer system in which two or more CPUs share full access to a common RAM. They are also known as parallel systems or tightly coupled systems.
- 6. 5 2.0 Multiprocessor Hardware All multiprocessors particularly have the property that every CPU can address all of memory. Basically today, multiprocessor hardware is embedded with Multi-core processors. They refers to more than one processing cores in a single processor. Some multiprocessors have the additional property that every memory word can be read as fast as every other memory word. These machines are called UMA (Uniform Memory Access) multiprocessors. The other type, NUMA (Non-uniform Memory Access) multiprocessors do not have this property. 2.0.1 UMA Bus-Based SMP Architectures The simplest multiprocessors are based on a single bus. Two or more CPUs and one or more memory modules all use the same bus for communication. When a CPU wants to read a memory word, it first checks to see if the bus is busy. If the bus is idle, the CPU puts the address of the word it wants on the bus, asserts a few control signals and waits until the memory puts the desired word on the bus. If the bus is busy when a CPU wants to read or write memory, the CPU just waits until the bus becomes idle. Here it causes the problem with this design. With two or three CPUs, contention for the bus will be manageable; with 32 or 64, it will be unbearable. The system will be totally limited by the bandwidth of the bus and most of the CPUs will be idle most of the time. The solution to this problem is to add a cache to each CPU as depicted in the figure (ii). The cache can be inside the CPU chip, next to the CPU chip, on the processor board, or some combination of all three. Since many reads can now be satisfied out of the local cache, there will be much less bus traffic and the system can support more CPUs. Figure (iii) shows the way in which each CPU has not only a cache, but also a local, private memory which it accesses over a dedicated (private) bus. To use this configuration optimally, the compiler should place all the program text, strings, constants and other read-only data, stacks, and local variables in the private memories. The shared memory is then only used for writable shared variables. In most cases, this careful placement will greatly reduce bus traffic, but it does require active cooperation from the compiler.
- 7. 6 (i) (ii) (iii) Three bus-based multiprocessors. (i) Without caching. (ii) With caching. (iii) With caching and private memories. 2.0.2 UMA Multiprocessors Using Crossbar Switches The use of a single bus limits the size of a UMA multiprocessor to about 16 or 32 CPUs, even with the best caching. To go through beyond that, a different kind of interconnection network is needed. The simplest circuit for connecting n CPUs to k memories is the crossbar switch, which is shown in the figure. Crossbar switches have been used for a long time within telephone switching exchanges to connect a group of incoming lines to a set of outgoing lines in an arbitrary way. Figure (a) An 8 × 8 crossbar switch. (b) An open cross point. (c) A closed cross point.
- 8. 7 At each intersection of a horizontal (incoming) and vertical (outgoing) line is a cross point. A cross point is a small switch that can be electrically opened or closed, depending on whether the horizontal and vertical lines are to be connected or not. Figure (a) shows three cross points closed simultaneously, allowing connections between the CPU and memory (pairs (001, 000), (101, 101), and (110,010)) at the same time. Many other combinations are also possible. 2.0.3 UMA Multiprocessors Using Multistage Switching Networks This is a completely different multiprocessor design is based on the humble 2 × 2 switch. This switch has two inputs and two outputs. Messages arriving on either input line can be switched to either output line. For our purposes, messages will contain up to four parts, as shown in Figure (b). The Module field tells which memory to use. The Address specifies an address within a module. The opcode gives the operation such as READ or WRITE. Finally, the optional Value field may contain an operand, such as a 32-bit word to be written on a WRITE. The switch inspects the Module field and uses it to determine if the message should be sent on X or on Y. Figure (a) A 2 × 2 switch. (b) A message format. These 2 × 2 switches can be arranged in many ways to build larger multistage switching networks. One example is the omega network, illustrated below. Here it is connected to eight CPUs to eight memories using 12 switches. Figure: An omega switching network.
- 9. 8 2.0.4 NUMA Multiprocessors Single bus UMA multiprocessors are generally limited to no more than a few dozen CPUs and crossbar or switched multiprocessors need a lot of expensive hardware and are not that much bigger. To get to more than 100 CPUs with that all memory modules have the same access time NUMA multiprocessors were aroused. They provide a single address space across all the CPUs, but unlike the UMA machines, access to local memory modules is faster than access to remote ones. Thus all UMA programs will run without change on NUMA machines, but the performance will be worse than on a UMA machine at the same clock speed. NUMA machines have three key characteristics that all of them possess and which together distinguish them from other multiprocessors: 1. There is a single address space visible to all CPUs. 2. Access to remote memory is via LOAD and STORE instructions. 3. Access to remote memory is slower than access to local memory. When the access time to remote memory is not hidden, because there is no caching, then the system is called NC-NUMA. When coherent caches are present the system is called CC- NUMA (Cache-Coherent NUMA). The most popular approach for building large CC-NUMA multiprocessors currently is the directory-based multiprocessor. It consists of fields of 32-bit memory address and a directory at node 36. (a) A 256-node directory-based multiprocessor. (b) Division of a 32-bit memory address into fields. (c) The directory at node 36.
- 10. 9 3.0 Multiprocessing models and frameworks Traditionally, there were two multiprocessing models: 1. Asymmetric Multi-Processing (AMP) 2. Symmetric Multiprocessing (SMP) 3.0.1 Asymmetric Multi-Processing (AMP) Simply in AMP, each processor is assigned a special task. AMP designs incorporate several cores on a chip with each processor using its own L1 cache and all processors share a common global memory. The AMP model can incorporate either heterogeneous cores executing in different operating systems or homogeneous cores executing the same OS. With heterogeneous cores, AMP architecture looks like a Digital Signal Processing (DSP) architecture. Application tasks are sent to the system’s separate processors in AMP designs. These processors are collocated on the same board, but each is a separate computing system with its own OS and memory partition within the common global memory. Traditional AMP Model
- 11. 10 The advantages of the AMP multiprocessing model i. The tasks and peripheral usage of the Operating system can be dedicated to a single core. Hence, it offers the easiest and quickest path for porting legacy code from single core designs to multi-core designs. Therefore, it is the easier multiprocessing model for serial computing software engineers to start with. ii. Migrating existing (non-SMP) OSs to the model is relatively simple and usually offer superior node-to-node communication compared to a distributed architecture. iii. AMP also allows software developers to directly control each core and how the cores work with standard debugging tools and methodologies. AMP thus supports the sharing of large global memories asymmetrically between cores. iv. AMP provides software developers with greater control over efficiency and determinism. v. AMP allows engineers to embed loosely coupled applications from multiple processors to a single processor with multiple cores. The disadvantages of the AMP multiprocessing model i. The AMP multiprocessing model becomes exponentially more difficult, when more cores are added, especially for tightly coupled applications executing on all cores. ii. AMP can result in underutilized processor cores. As an example, if one core becomes busy, applications running on that core cannot easily migrate to an underutilized core. Although dynamic migration is possible in AMP, it involves complex check pointing of the application’s state which can result in service interruption while the application is stopped on one core and restarted on a different core. This migration may be impossible if the cores use different OSs. iii. None of the OSs owns the entire application system. The application designer must manage the complex tasks of handling shared hardware resources. The complexity of
- 12. 11 these tasks increases significantly as more cores are added. As a result, AMP is ill- suited for tightly coupled applications integrating more than two cores. iv. Memory latency and bandwidth can be affected by other nodes. v. The AMP multiprocessing model does not permit system tracing tools to gather operating statistics for the multi-core chip as a whole since the OSs are distributed on each core. Instead, application developers gather this information separately from each core and then combine the results for analysis purposes. This is only a concern for systems where the applications on the individual cores are tightly coupled. vi. Cache thrashing may occur in some applications.
- 13. 12 3.0.2 Symmetric Multi-Processing (SMP) Simply, in SMP architectures, each processor performs all the tasks within the OS. Each node may have two or more processors using homogeneous cores, (not heterogeneous cores) while the multiple processors share the global memory. In addition, the processors may also have both local and shared cache, and the cache is coherent between all processors and memory. SMP executes only one copy of an OS on all of the chip’s cores or a subset of the chip’s cores. Since the OS has insight into all system elements, it can transparently and automatically allocate shared resources on all cores. It can also execute any application on any core. Therefore, SMP was designed so it can mimic single-processor designs in a distributed computing environment. The OS provides dynamic memory allocation, allowing all cores to draw on the full pool of available memory without a performance penalty. Traditional SMP Model
- 14. 13 The advantages of the SMP multiprocessing model i. There is a large global memory and better performance per watt in these systems due to using fewer memory controllers. Instead of splitting memory between multiple central processing units, SMP’s large global memory is accessible to all processor cores. For example, data intensive applications, such as image processing and data acquisition systems, often prefer large global memories that can be accessed at data rates up to 100s of Megabytes/second (Mbytes/sec). ii. SMP also provides simpler node-to-node communication and SMP applications can be programmed to be independent of node count. SMP especially lends itself to newer multi-core processor designs. iii. Systems based on SMP have the OS perform load-balancing for the tasks between all cores. iv. One copy of an OS can control all tasks performed on all cores, dynamically allocating tasks or threads to the underutilized core to achieve maximum system utilization. v. The SMP multiprocessing model permits system tracing tools to gather operating statistics for the multi-core chip as a whole and thereby providing developers insights into optimizing and debugging applications. The tracing tools can track thread migration between cores, scheduling events and other information useful for maximizing core utilization. vi. A SMP approach is best for a larger number of cores and for developers who have time to adequately develop a long term solution that may eventually add more cores.
- 15. 14 The disadvantages of the SMP multiprocessing model i. The memory latency and bandwidth of a given node can be affected by other nodes and cache thrashing may occur in some applications. ii. Legacy applications ported to an SMP environment generally require a redesign of the software. Legacy applications with poor synchronization among threads may work incorrectly in the SMP concurrent environment. Therefore an SMP approach is better for software developers with parallel computing experience. iii. When moving legacy architectures from single core processing to multi-core processing, the major issue is concurrency. In a single operating environment, running multiple threads is a priority, so two threads with different priority levels can execute in parallel when they are distributed to different cores. iv. SMP systems exhibit non-determinism. So therefore, any computing solutions that require determinism may need to stay away from an SMP model.
- 16. 15 3.0.3 AMP and SMP Model Comparisons Programming Concept AMP SMP Seamless resource Sharing No Yes Scalable beyond dual Core No/Complicated for tightly coupled apps Yes Mixed OS environment (ex: VxWorks & Linux) Yes No Dedicated processor by function (CPU affinity) Yes Yes/No. CPU affinity is not supported in traditional SMP models, but most RTOS suppliers provide CPU affinity for their SMP models. Inter-core messaging Slower (application) Fast (OS primitives) Thread synchronization between cores No/Complicated Yes Dynamic load balancing No Yes System-wide debug and optimization No/Complicated for tightly coupled apps Yes Migrating Legacy Apps/New App Development Best at Migrating Legacy Apps. Good choice for New App Development. Best for New App Development Data/Task Parallelism Task preferred Data preferred Engineer experienced in Serial Computing Only Better choice than SMP More difficult for a novice parallel computing developer
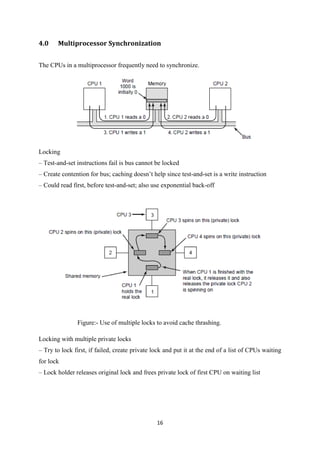
- 17. 16 4.0 Multiprocessor Synchronization The CPUs in a multiprocessor frequently need to synchronize. Locking – Test-and-set instructions fail is bus cannot be locked – Create contention for bus; caching doesn’t help since test-and-set is a write instruction – Could read first, before test-and-set; also use exponential back-off Figure:- Use of multiple locks to avoid cache thrashing. Locking with multiple private locks – Try to lock first, if failed, create private lock and put it at the end of a list of CPUs waiting for lock – Lock holder releases original lock and frees private lock of first CPU on waiting list
- 18. 17 4.0.1 Spinning versus switching In some cases CPU “must” wait and scheduling critical section may be held at that time. For example, must wait to acquire ready list. In other cases spinning may be more efficient than blocking spinning wastes CPU cycles switching uses up CPU cycles also if critical sections are short spinning may be better than blocking static analysis of critical section duration can determine whether to spin or block dynamic analysis can improve performance
- 19. 18 5.0 Multiprocessor Scheduling On a uniprocessor, scheduling is a one dimensional. The operating system has to decide repeatedly which process should be run next? On a multiprocessor, scheduling is two dimensional. The scheduler has to decide which process to run and which CPU to run it on. This extra dimension greatly complicates scheduling on multiprocessors. Another complicating factor is that in some systems, all the processes are unrelated whereas in others they come in groups. An example of the first situation is a timesharing system in which independent users start up independent processes. The processes are unrelated and each one can be scheduled without regard to the other ones. An example of the second situation occurs regularly in program development environments. Large systems often consist of some number of header files containing macros, type definitions, and variable declarations that are used by the actual code files. When a header file is changed, all the code files that include it must be recompiled and the program make is commonly used to manage development. 5.0.1 Timesharing The simplest scheduling algorithm for dealing with unrelated processes (or threads) is to have a single system wide data structure for ready processes. This is possibly just a list, but more likely a set of lists for processes at different priorities as depicted in the figure. Here the 16 CPUs are all currently busy and a prioritized set of 14 processes are waiting to run. The first CPU to finish its current work (or have its process block) is CPU 4, which then locks the scheduling queues and selects the highest priority process, A. Next, CPU 12 goes idle and chooses process B. As long as the processes are completely unrelated, scheduling occurs repeatedly.
- 20. 19 Figure: Using a single data structure for scheduling a multiprocessor. Using a single scheduling data structure for all CPUs timeshares the CPUs, much as they would be in a uniprocessor system. It also provides automatic load balancing because it can never happen that one CPU is idle while others are overloaded. Two disadvantages of this approach are the potential contention for the scheduling data structure as the numbers of CPUs grows and the usual overhead in doing a context switch when a process blocks for I/O. It is also possible that a context switch happens when a process’s quantum expires. 5.0.2 Space Sharing Scheduling multiple threads at the same time across multiple CPUs is called space sharing. The simplest space sharing algorithm works like this. Assume that an entire group of related threads is created at once. At the time it is created, the scheduler checks to see if there are as many free CPUs as there are threads. If there are, each thread is given its own dedicated (non multiprogrammed) CPU and they all start. If there are not enough CPUs, none of the threads are started until enough CPUs are available. Each thread holds onto its CPU until it terminates, at which time the CPU is put back into the pool of available CPUs. If a thread blocks on I/O, it continues to hold the CPU, which is simply idle until the thread wakes up. When the next batch of threads appears, the same algorithm is applied. At any instant of time, the set of CPUs is statically partitioned into some number of partitions, each one running the threads of one process. In the following figure, we have partitions of sizes 4, 6, 8, and 12 CPUs, with 2 CPUs unassigned. As time goes on, the number and size of the partitions will
- 21. 20 change as processes come and go.So, in space sharing groups of cooperating threads can communicate at the same time and so it results in a fast inter-thread communication time. Figure: A set of 32 CPUs split into four partitions, with two CPUs A clear advantage of space sharing is the elimination of multiprogramming, which eliminates the context switching overhead. The disadvantage is the time wasted when a CPU blocks and has nothing at all to do until it becomes ready again. 5.0.3 Interplay between scheduling and IPC Consequently, people have looked for algorithms that attempt to schedule in both time and space together, especially for processes that create multiple threads, which usually need to communicate with one another. To see the kind of problem that can occur when the threads of a process (or processes of a job) are independently scheduled, consider a system with threads A0 and A1 belonging to process A and threads B0 and B1 belonging to process B. threads A0 and B0 are timeshared on CPU 0; threads A1 and B1 are timeshared on CPU 1. Threads A0 and A1 need to communicate often. The communication pattern is that A0 sends A1 a message with A1 then sending back a reply to A0, followed by another such sequence. Figure: Communication between two threads belonging to process A that are running out of phase.
- 22. 21 In time slice 0, A0 sends A1 a request but A1 does not get it until it runs in time slice 1 starting at 100 milliseconds. It sends the reply immediately but A0 does not get the reply until it runs again at 200 milliseconds. The net result is one request-reply sequence every 200 milliseconds. So this is not very good. So the problem with communication between two threads can be stated simply as both the threads at last become belong to a one process and both running out of phase. 5.0.4 Gang scheduling The solution to the problem of communication among threads is gang scheduling, which is an outgrowth of co-scheduling. Gang scheduling has three parts: i. Groups of related threads are scheduled as a unit, a gang. ii. All members of a gang run simultaneously, on different timeshared CPUs. iii. All gang members start and end their time slices together. In this mechanism, all CPUs are scheduled synchronously. This means that time is divided into discrete quanta. At the start of each new quantum, all the CPUs are rescheduled with a new thread being started on each one. At the start of the following quantum, another scheduling event happens. In between, no scheduling is done. If a thread blocks, its CPU stays idle until the end of the quantum. The Gang scheduling can be viewed as below. Figure: Gang Scheduling
- 23. 22 Here a multiprocessor with six CPUs is being used by five processes, A through E, with a total of 24 ready threads. During time slot 0, threads A0 through A6 are scheduled and run. During time slot 1, Threads B0, B1, B2, C0, C1, and C2 are scheduled and run. During time slot 2, D’s five threads and E0 get to run. The remaining six threads belonging to process E run in time slot 3. Then the cycle repeats, with slot 4 being the same as slot 0 and so on. The idea of gang scheduling is to have all the threads of a process run together, so that if one of them sends a request to another one, it will get the message almost immediately and be able to reply almost immediately. As shown in the above figure, since all the A threads are running together, during one quantum, they may send and receive a very large number of messages in one quantum, thus eliminating the problem above.
- 24. 23 6.0 Applications of multiprocessing systems 6.0.1 Contemporary Multiprocessor Hardware Today the usage of multicore processors in the multiprocessing operating systems has become a growing trend. In multiprocessors there are more than one processing cores in a single processor, that are connected on chip bus and those multicore dies in a package. Some of the multicores are as follows. • Intel Nehalem: Beckton, Westmere; Sandy Bridge • AMD Opteron: K10 (Barcelona, Magny Cours); Bulldozer • ARM Cortex A9, A15 MPCore • Oracle (Sun) UltraSparc T1,T2,T3,T4 (Niagara) 1. ARM Cortex A9 MPCore 2. Intel Nehalem
- 25. 24 3. AMD Barcelona 6.0.2 Current Technologies of Multiprocessing Systems Software lockout - In multiprocessor computer systems, software lockout is the issue of performance degradation due to the idle wait times spent by the CPUs in kernel-level critical sections. - Though software lockout is a great problem now there are solutions for this problem in modern technology. - To reduce the performance degradation of software lockout to reasonable levels (L/E between 0.05 and 0.1), the kernel and/or the operating system must be designed accordingly. Conceptually, the most valid solution is to decompose each kernel data structure in smaller independent substructures, having each a shorter elaboration time. This allows more than one CPU to access the original data structure. - kernel must be designed to have its critical sections as short as possible, therefore decomposing each data structure in smaller substructures. Giant Lock - In operating systems, a giant lock is a lock which be used in the kernel to provide the concurrency control required by symmetric multiprocessingsystems. - A giant lock is a solitary global lock that is held whenever a thread enters kernel space, and is released when the thread returns to user space.
- 26. 25 Heterogeneous computing - Heterogeneous computing refers to systems that use more than one kind of processor. - Usually heterogeneity in the context of computing referred to different instruction set architectures (ISA), where the main processor has one and the rest have another, usually a very different architecture (maybe more than one), not just a different micro architecture (floating point number processing is a special case - The level of heterogeneity in modern computing systems gradually rises as increases in chip area and further scaling of fabrication technologies allows for formerly discrete components to become integrated parts of a system-on-chip. ARM big. LITTLE - It is a heterogeneous computing architecture developed by ARM Holdings, coupling (relatively) slower, and low-power processor cores with (relatively) more powerful and power-hungry ones. - The intention is to create a multi-core processor that can adjust better to dynamic computing needs and use less power than clock scaling alone. - Finer-grained control of workloads that are migrated between cores. Because the scheduler is directly migrating tasks between cores, kernel overhead is reduced and power savings can be correspondingly increased. - Implementation in the scheduler also makes switching decisions faster than in the framework implemented in IKS. Tegra - Tegra is a system on a chip series developed for mobile devices such as smartphones, personal digital assistants, andmobile Internet devices. - The Tegra integrates an ARM architecture central processing unit (CPU), graphics processing unit (GPU),northbridge, southbridge, and memory controller onto one package - The second generation TegraSoC has a dual-core ARM Cortex-A9 CPU an ultra-low power (ULP) GeForce GPU with 4 pixel shaders + 4 vertex shaders,[14] a 32-bit single- channel memory controller with either LPDDR2-600 or DDR2-667 memory, a
- 27. 26 32KB/32KB L1 cache per core and a shared 1MB L2 cache.[15] There is also a version of the SoC supporting 3D displays; this SoC uses a higher clocked CPU and GPU BMDFM - Binary Modular Dataflow Machine) is software, which enables running an application in parallel on shared memory symmetric multiprocessors (SMP) using the multiple processors to speed up the execution of single applications. - MDFM automatically identifies and exploits parallelism due to the static and mainly DYNAMIC SCHEDULING of the dataflow instruction sequences derived from the formerly sequential program. - BMDFM dynamic scheduling subsystem performs an SMP emulation of Tagged- Token Dataflow Machine to provide the transparent dataflow semantics for the applications. Simultaneous multithreading - It is a technique for improving the overall efficiency of superscalar CPUs with hardware multithreading. SMT permits multiple independent threads of execution to better utilize the resources provided by modern processor architectures. - Multithreading is similar in concept to preemptive multitasking but is implemented at the thread level of execution in modern superscalar processors.
- 28. 27 6.0.3 Current applications of Multiprocessing systems Disco Operating System Disco is a system Virtual Machine that presents a similar fundamental machine to all of the various OS’s that might be running on the machine. Disco was developed as a part of the Stanford FLASH project, funded by ARPA grant DABT63-94-C-0054. FLASH is an academic machine designed at Stanford University. Disco is highly scalable. These can be commodity OS’s, uniprocessor, multiprocessor or specialty systems. VMM designed for the FLASH multiprocessor machine includes a collection of nodes containing a processor, memory, and I/O. The use directory cache coherence is likely, which makes it look like a CC-NUMA machine. It has also been ported to a number of other machines. Disco performs features such as Scalability, Flexibility, hide NUMA effect, Fault Containment and Compatibility with legacy applications Disco’s Interface The virtual CPU of Disco is an abstraction of a MIPS R10000. The operating system do not only emulates but extends (e.g., reduces some kernel operations to simple load/store instructions.) It contains a presented abstraction of physical memory starting at address 0 (zero). I/O Devices are varying from disks, network interfaces, interrupts, clocks, etc. and it contains special interfaces for network and disks. Disco was implemented as a multi-threaded shared-memory program. It paid a careful attention paid to memory placement, cache-aware data structures and processor communication patterns. Disco is only 13,000 lines of code whereas Windows Server 2003
- 29. 28 contained of about 50,000,000 lines, Red Hat about 7.1 - ~ 30,000,000 lines and Mac OS X 10.4 - ~86,000,000 line of code. The execution of a virtual processor is mapped one-for-one to a real processor. At each context switch, the state of a processor is made to be that of a VP. On MIPS, Disco runs in kernel mode and puts the processor in appropriate modes for what’s being run and Supervisor mode for OS, user mode for apps. Simple scheduler of DISCO allows VP’s to be time-shared across the physical processors. Virtual Physical Memory The OS makes requests to physical addresses and Disco translates them to machine addresses. Disco uses the hardware TLB (Translation-Lookaside Buffer) for this. Switching a different VP onto a new processor requires a TLB flush, so Disco maintains a 2nd -level TLB to offset the performance hit. There’s also a technical issue with TLBs, that Kernel space and the MIPS processor that threw them for a loop. NUMA Memory Management In an effort to mitigate the non-uniform effects of a NUMA machine, Disco does a bunch of stuff. They are allocating as much memory to have “affinity” to a processor as possible. And also then it migrates or replicates pages across virtual machines to reduce long memory accesses. Virtual I/O Devices Obviously Disco needs to intercept I/O requests and direct them to the actual device. It is primarily handled by installing drivers for Disco I/O in the guest OS. In DISCO, DMA provides an interesting challenge, in that the DMA addresses need the same translation as regular accesses.
- 30. 29 Disco use 4 representative workloads for parallel applications as: Software Development (Pmake of a large app) Hardware Development (Verilog simulator) Scientific Computing (Raytracing and a sorting algorithm) Commercial Database (Sybase) Memory usage of Disco scales well and processor utilization also scales well. Performance overheads are relatively small for most loads. It has lots of engineering challenges, but most seem to have been overcome. Tesselation (Space-Time Partitioning (Stp)) Tessellation is a new operating system built on top of STP, which restructures a traditional operating system as a set of distributed interacting services. STP divides resources such as cores, cache, and network bandwidth amongst interacting software components. Components are given unrestricted access to their resources and may schedule them in an application- specific fashion, which is critical for good parallel application performance. Components communicate via messages, which are strictly controlled to enhance correctness and security. In Tessellation, parallel applications can efficiently coexist and interact with one another. Space-Time Partitioning in Tessellation: a snapshot in time with four spatial partitions. Partitions provide a natural framework for encapsulating major components of applications and the operating system. The objectives of partitions could be partition for performance, Quality of service, Correctness, Energy, Hybrid Behavior etc.
- 31. 30 The Tessellation Kernel as shown below is a thin, trusted layer that implements resource allocation and scheduling at the partition granularity. Tessellation exploits a combination of hardware and software mechanisms to perform space-time partitioning and provides a standardized API for applications to configure resources and construct secure restricted communication channels between partitions. The Tessellation Kernel is much thinner than traditional monolithic kernels or even hypervisors, and avoids many of the performance issues with micro kernels by providing OS services in spatially distributed active partitions through secure messaging and thus avoiding context switches. The Tessellation Kernel utilizes a combination of hardware and software mechanisms to enforce partition boundaries. Components of a Tessellation system. K42 K42 is an open-source research operating system for cache-coherent 64-bit multiprocessor systems. It was developed primarily at IBM Thomas J. Watson Research Center in collaboration with University of Toronto and University of New Mexico. The main focus of this OS is to address performance and scalability issues of system software on large- scale, shared memory, NUMA multiprocessor computers. This is an operating system well suited to support systems research. The primary goals of K42's design that support such research include flexibility to allow a multitude of policies and implementations to be supported simultaneously, extensibility to allow new policies and implementations to be readily added and scalability to enable good performance for both small and large applications on both small and large multiprocessor systems. The goals are accomplished via key features including an object oriented structure that allows specialized resource management implementations and policies on a per-resource, per application basis,
- 32. 31 implementation in user-level servers of much of the system functionality, and a sophisticated set of underlying services that provides a programming model for developing system software in a scalable and modular fashion. These characteristics make K42 an attractive framework for prototyping new operating system ideas. In addition, K42 has a sophisticated performance monitoring infrastructure allowing a thorough understanding of new ideas to be gained. The above framework combined with a consistent emphasis on scalability makes K42 well suited for high-end computing initiatives. K42 provides an enhanced object-oriented model, called clustered objects that can improve access locality by enabling selective partitioning, replication and distribution of object implementations. K42 is structured around a client-server model. Much of the functionality traditionally implemented in the kernel or servers is moved to libraries in the application's address space.
- 33. 32 K42 clustered objects K42 Performance
- 34. 33 7.0 Advantages, Disadvantages and Solutions 7.0.1 Advantages of Multiprocessor Systems - Better Performance. Due to multiplicity of processors, multiprocessor systems have better performance than single processor systems. (Such as shorter responses times and higher throughput) For example, if there are two different programs to be run, two processors are evidently more powerful than one because the programs can be simultaneously run on different processors. Furthermore, if a particular computation can be partitioned into a number of sub- computations that can run concurrently, in a multiprocessor system, all the sub-computations can be simultaneously run, with each one on a difference processor. It is also known as parallel processing. - Better Reliability Due to multiplicity of processors, multiprocessor systems also have better reliability than single processor systems. In a properly designed multiprocessor system, if one of the processors breaks down, the other processor or processors automatically takes over the system workload until repairs are made. Hence, a complete breakdown of such systems can be avoided.
- 35. 34 7.0.2 Disadvantages and obstacles of Multiprocessor Systems Multiprocessing systems deal with four problem types associated with control processes or with the transmission of message packets to synchronize events between processors. These types are 1. Overhead - The time wasted in achieving the required communications and control status prior to actually beginning the client’s processing request. 2. Latency - The time delay between initiating a control command, or sending the command message and when the processors receive it and begin initiating the appropriate actions. 3. Determinism - The degree to which the processing events are precisely executed 4. Skew - A measurement of how far apart events occur in different processors, when they should occur simultaneously. 5. Cache coherence - is the consistency of shared resource data that ends up stored in multiple local caches. When clients in a system maintain caches of a common memory resource, problems may arise with inconsistent data. This is particularly true of CPUs in a multiprocessing system. The various ways in which these problems arise in multiprocessing systems become more understandable when considering how a simple message is interpreted within such architecture. If a message-passing protocol sends packets from one of the processors to the data chain linking the others, each individual processor must interpret the message header and then pass it along if the packet is not intended for it. Plainly, latency and skew will increase with each pause for interpretation and retransmission of the packet. When additional processors are added to the system chain (scaling out), determinism is adversely impacted. A custom hardware implementation is required on circuit boards designed for multiprocessing systems whereby a dedicated bus, apart from a general-purpose data bus, is provided for command-and-control functions. In this way, determinism can be maintained regardless of the scaling size. In multiprocessing systems using a simple locking kernel design, it is possible for two CPUs to simultaneously enter a test and set loop on the same flag. These two processors can
- 36. 35 continue to spin forever, with the read of each causing the store of the other to fail. To prevent this, a different latency must be purposely introduced for each processor. To provide good scaling, SMP operating systems are provided with separate locks for different kernel subsystems. One solution is called fine-grained kernel locking. It is designed to allow individual kernel subsystems to run as separate threads on different processors simultaneously, permitting a greater degree of parallelism among various application tasks. A fine-grained kernel-locking architecture must permit tasks running on different processors to execute kernel-mode operations simultaneously, producing a threaded kernel. If different kernel subsystems can be assigned separate spin locks, tasks trying to access these individual subsystems can run concurrently. The quality of the locking mechanism, called its granularity, determines the maximum number of kernel threads that can be run concurrently. If the NOS is designed with independent kernel services for the core scheduler and the file system, two different spin locks can be utilized to protect these two subsystems. Accordingly, a task involving a large and time-consuming file read/write operation does not necessarily have to block another task attempting to access the scheduler. Having separate spin locks assigned for these two subsystems would result in a threaded kernel. Both tasks can execute in kernel mode at the same time, as shown in fallow, A spin lock using a threaded kernel. We can notice that while Task 1 is busy conducting its disk I/O, Task 2 is permitted to activate the high-priority Task 3. This permits Task 2 and Task 3 to conduct useful operations
- 37. 36 simultaneously, rather than spinning idly and wasting time. Observe that Task 3’s spin lock is released prior to its task disabling itself. If this were not done, any other task trying to acquire the same lock would idly spin forever. Using a fine-grained kernel-locking mechanism enables a greater degree of parallelism in the execution of such user tasks, boosting processor utilization and overall application throughput. Why use multiple processors together instead of simply using a single, more powerful processor to increase the capability of a single node? The reason is that various roadblocks currently exist limiting the speeds to which a single processor can be exposed. Faster CPU clock speeds require wider buses for board-level signal paths. Supporting chips on the motherboard must be developed to accommodate the throughput improvement. Increasing clock speeds will not always be enough to handle growing network traffic. Cache Coherence Software on a shared-memory multiprocessor suffers not only from cold, conflict and capacity cache misses (as on a uniprocessor), but also from coherence misses. Coherence misses are caused by read/write sharing and the cache-coherence protocol and are often the dominant source of cache misses. For example, in a study of IRIX on a 4-processor system, Tolerance found that misses due to sharing dominated all other types of misses, accounting for up to 50 percent of all data cache misses. In addition to misses caused by direct sharing of data, writes by two processors to distinct variables that reside on the same cache line will cause the cache line to Ping-Pong between the two processors. This problem is known as false sharing and can contribute significantly to the cache miss rate. Semi-automatic methods for reducing false sharing, such as structure padding and data regrouping, have proven somewhat effective, but only for parallel scientific applications. The effects of synchronization variables can have a major impact on cache performance, since they can have a high degree of read/write sharing and often induce large amounts of false sharing. Cache miss latency In addition to the greater frequency of cache misses due to sharing, SMMP programmers are faced with the problem that cache misses cost more in multiprocessors regardless of their
- 38. 37 cause. The latency increase of cache misses on multiprocessors stems from a number of sources. First, more complicated controllers and bus protocols are required to support multiple processors and cache coherence, which can increase the miss latency by a factor of two or more. Second, the probability of contention at the memory and in the interconnection network (bus, mesh, or other) is higher in a multiprocessor. Extreme examples can be found in early work on Mach on the RP3 where it took 2.5 hours to boot the system due to memory contention and in the work porting Solaris to the Cray Super Server where misses in the idle process slowed non-idle processors by 33 percent. Third, the directory-based coherence schemes of larger systems must often send multiple messages to retrieve up-to-date copies of data or invalidate multiple sharers of a cache-line, further increasing both latency and network load. This effect is clearly illustrated in the operating system investigations which found that local data miss costs were twice the local instruction cache miss costs, due to the need to send multiple remote messages. In the case of large systems, the physical distribution of memory has a considerable effect on performance. Such systems are generally referred to as NUMA systems, or Non-Uniform Memory Access time systems, since the time to access memory varies with the distance between the processor and the memory module. In these systems, physical locality plays an important role in addition to temporal and spatial locality. As a result of the high cost of cache misses, newer systems are being designed to support non-blocking caches and write buffers in order to hide load and store latencies. Many of these systems allow loads and stores to proceed while previous loads and stores are still outstanding. This results in a system in which the order of loads and stores may not appear the same to each processor; these systems are sometimes referred to as being weakly consistent. Another result of the high cache-miss latency is the movement towards larger cache lines of 128 or even 256 bytes in length. These large cache lines are an attempt to substitute bandwidth (which is relatively easy to design into a system) for latency (which is much harder to design in). Unfortunately, large cache lines tend to degrade performance in SMMPs due to increased false sharing.
- 39. 38 7.0.3 Solutions The issues described in the previous section clearly have a major impact on the performance of multiprocessor operating system software. In order to achieve good performance, system software must be designed to take the hardware characteristics into account. There are no magic solutions for dealing with them; the design of each system data structure must take into account the expected access pattern, degree of sharing, and synchronization requirements. Nevertheless, it has been found a number of principles and design strategies that have repeatedly been useful. Structuring data for caches When frequently accessed data is shared, it is important to consider how the data is mapped to hardware cache lines and how the hardware keeps the cached copies of the data consistent. Principles for structuring data for caches include: 1: Segregate read-mostly data from frequently modified data. Read-mostly data should not reside in the same cache line as frequently modified data in order to avoid false sharing. Segregation can often be achieved by properly padding, aligning, or regrouping the data. Consider a linked list whose structure is static but whose elements are frequently modified. To avoid having the modifications of the elements affect the performance of list traversals, the search keys and link pointers should be segregated from the other data of the list elements. 2: Segregate independently accessed read/write data from each other. This principle prevents false sharing of read/write data, by ensuring that data that is accessed independently by multiple processors ends up in different cache lines. 3: Privatize write-mostly data. Where practical, generate a private copy of the data for each processor so that modifications are always made to the private copy and global state is determined by combining the state of all copies. This principle avoids coherence overhead in the common case, since processors update only their private copy of the data. For example, it is often necessary to maintain a reference count on an object to ensure that the object is not
- 40. 39 deleted while it is being accessed. Such a reference count can be decomposed into multiple reference counts, each updated by a different processor and, applying S2, forced into separate cache lines. 4: Use strictly per-processor data wherever possible. If data is accessed mostly by a single processor, it is often a good idea to restrict access to only that processor, forcing other processors to pay the extra cost of inter-processor communication on their infrequent accesses. In addition to the caching benefits, strictly per-processor structures allow the use of uniprocessor solutions to synchronize access to the data. For example, for low-level structures, disabling interrupts is sufficient to ensure atomic access. Alternatively, since data is only accessed by a single processor, the software can rely on the ordering of writes for synchronization, something not otherwise possible on weakly consistent multiprocessors. Locking data In modern processors, acquiring a lock involves modifying the cache line containing the lock variable. Hence, in structuring data for good cache performance, it is important to consider how accesses to the lock interact with accesses to the data being locked. 1: Use per-processor reader/writer locks for read-mostly data. A lock for read-mostly data should be implemented using a separate lock for each processor. To obtain a read-lock, a processor need only acquire its own lock, while to obtain a write-lock it must acquire all locks. This strategy allows the processor to acquire a read-lock and access the shared data with no coherence overhead in the common case of read access. 2: Segregate contended locks from their associated data if the data is frequently modified. If there is a high probability of multiple processes attempting to modify data at the same time, then it is important to segregate the lock from the data so that the processors trying to access the lock will not interfere with the processor that has acquired the lock. 3: Collocate uncontended locks with their data if the data is frequently modified. When a lock is brought into the cache for locking, some of its associated data is then brought along with it and hence subsequent cache misses are avoided.
- 41. 40 Localizing data accesses For large-scale systems, the system programmer must be concerned with physical locality in order to reduce the latency of cache misses, to decrease the amount of network traffic and to balance the load on the different memory modules in the system. Physical locality can be especially important for operating systems since they typically exhibit poor cache hit rates. 1: Replicate read-mostly data. Read-mostly data should be replicated to multiple memory modules so that processors’ requests can be handled by nearby replicas. Typically, replication should occur on demand so that the overhead of replicating data is only incurred if necessary. 2: Partition and migrate read/write data. Data should be partitioned into constituent components according to how the data will be accessed, allowing the components to be stored in different memory modules. Each component should be migrated on use if it is primarily accessed by one processor at a time. Alternatively, if most of the requests to the data are from a particular client, then the data should be migrated with that client.
- 42. 41 8.0 New trends of Multiprocessing - Technology Trends Computer technology has made incredible progress in the years since the first general- purpose electronic computer was created. In the late 1970s, the emergence of microprocessor led to high performance improvement—about 35% growths per year. Owning to this growth rate and the cost advantage of the mass-produced microprocessor, an increasing fraction of computer business is based on microprocessors. From mid-1980s, the growth rate is 50%- 100% per year. At the same time, the number of transistors on chip grows rapidly. Clock rates also experienced tremendous growth rates. Figure 1 shows us such general technology trend. Figure 2 shows the technology trends. We can see that multiprocessors have the fastest performance growth rate. Figure 3 shows us the clock frequency g rowth rate. We can see that the clock frequency increases 30% per year. Figure 4 shows us the transistor count growth rate, from which we can see that now there are 100 million transistors on chip and the transistor count grows much faster than clock rate—currently 40% per year. Parallel processing is a way to use more transistors.
- 43. 42 - Application Demand Trends Parallel computing is inevitable in the future. Performance is always the objective. Higher computational performance is always welcome in scientific computing. Today’s research in human genome, fluid turbulence, vehicle dynamics, ocean circulation, superconductor modeling and some other fields requires 1TFLOPS computational performance requirement and 1TB storage requirement. It is harder and harder to satisfy such requirement using uniprocessors. Some general-purpose computing also requires high computing performance. For example, engineering computing (CAD, database, visualization, image processing…) has higher and higher computing performance demands Commercial computing (transaction processing, data mining…) relies on parallelism for high end because the computational power determines the ability to handle business. Some embedded systems, especially some mobile terminals such as handheld devices, require significant computational power. Moreover, low power consumption and low cost are usually strict specification constraints. Currently, parallel computing has occurred in scientific and engineering computing. In commercial computing, parallel computing is more and more popular. Using large-scale multiprocessors instead of supercomputers is already under way. The demand for improving throughput on sequential workloads maybe is the greatest use of small-scale multiprocessors.
- 44. 43 - Architecture Trends In the last two decades, performance growth of uniprocessors exploiting instruction-level parallelism, driven by the microprocessors, was at its highest rate since the first transistorized computers in the late 1950s and the early 1960s. This rapid rate of performance growth will continue at least for the next 5 years. Instruction-level parallelism is still valuable but limited. Coarser-level parallelism (e.g. thread-level parallelism) is the most viable approach. Bus technology and processor performance accelerate the advances of each other. From all of the above trends in technology, application demand and architecture, we can see that parallelism is more and more important and multiprocessor, as a cost-effective parallel architecture, is increasingly attractive, not irrelevant. Today’s microprocessor has multiprocessor support. Many servers and workstation are becoming multiprocessors to get higher performance at reasonable cost. We can say that multiprocessor will definitely have a greater role in the future.
- 45. 44 8.0.1 Multiprocessing models and frameworks New trends Asymmetric Multi-Processing is diametrically different from Symmetric Multi-Processing in most programming concepts. However, software architect or developer of a system being ported to a multi-core processor needs AMP support for some programming concepts and SMP support for other programming concepts. The most developed solution for this, prevalent in the past several years is developing hybrid models that combine some AMP support with some SMP support based on the system needs. Two of the more popular hybrid models include, Combined AMP/SMP Model and Supervised AMP Model. Combined AMP/SMP Model Combined AMP/SMP Model executes both processing models on one processor. For example, for a quad-core processor, two cores will be executing an AMP model while the remaining two cores will be executing a SMP model. Combined AMP/SMP Model
- 46. 45 In this hybrid model, there is no cross pollination between the models running on any of the cores. One benefit of this model is that architects can implement tasks that achieve better performance on AMP such as task parallelism on the AMP cores and tasks that achieve better performance on SMP such as data parallelism on the SMP cores, resulting in an overall system performance than an AMP or SMP only system. Supervised AMP Model Supervised AMP Model includes a layer of software executing between the Oss and the cores. The supervisor’s primarily benefit is additional communication software that allows for improved system communication between the OSs running on the different cores. The benefits of this model are:- - Improving scalability for additional cores. - Providing better system debugging between processes on different cores. - Enabling reboot of individual cores on your system. Supervised AMP Model
- 47. 46 Hence, Supervised AMP model has improved system debugging capabilities over a system implementing a traditional AMP model. 8.0.2 Experimental / Future multiprocessor hardware Examples of the multiprocessor hardware that are still being developed are:- Intel SCC Microsoft Beehive Intel Polaris Tilera Tile64, Tile-Gx Intel MIC (Knight’s Corner - Xeon Phi) i. Intel SCC ii. Microsoft Beehive iii. Intel MIC
- 48. 47 iv. Tilera Tile64, Tile-Gx 8.0.3 Experimental / Future multiprocessor systems Barrelfish Operating system Barrelfish is a new research operating system being built from scratch and released by ETH Zurich in Switzerland, with assistance from Microsoft Research. They are motivated by two closely related trends in hardware design: first, the rapidly growing number of cores, which leads to a scalability challenge, and second, the increasing diversity in computer hardware, requiring the OS to manage and exploit heterogeneous hardware resources. Barrelfish structure The special features that are included in this OS are:- No sharing • Has a Multikernel – fos: factored operating system The multikernel
- 49. 48 Microkernel Goals of this OS: – Scale to many cores – Support and manage heterogeneous hardware Design principles: – Interprocessor communication is explicit – OS structure hardware neutral – State is replicated Corey Operating system Corey is an experimental operating system designed to give applications control of sharing kernel data structures. Multiprocessor application performance can be limited by the operating system when the application uses the operating system frequently and the operating system services use data structures shared and modified by multiple processing cores. If the application does not need the sharing, then the operating system will become an unnecessary bottleneck to the applications' performance. Corey arranges each kernel data structure so that only a single processor need update it, unless directed otherwise by the application. Corey implements three new operating system abstractions that allow applications to control inter-core sharing and to take advantage of the likely abundance of cores by dedicating cores to specific operating system functions. Measurements of micro benchmarks and application benchmarks show how control over sharing can improve performance. Some other special features are:- • Organized as an exokernel • Corey kernel provides – Address ranges – Kernel cores – Shares
- 50. 49 References i. RetrievedJanuary , 2014 Available: http://www.cse.unsw.edu.au/~cs9242/12/lectures/10-multiproc-4up.pdf ii. RetrievedJanuary , 2014 Available: http://www.cs.vu.nl/~ast/books/mos2/sample- 8.pdf iii. Operating systems concepts, .Silberschatz, Galvin & Gagne, John Wiley & sons8th edition ed ,Vol . ;.2009 iv. Modern Operating systems. A.S Tanenbaum2nd edition ed ,Vol . ;.2001. v. Performance Issues for Multiprocessor Operating Systems, Benjamin Gamsa, Orran Krieger, EricW. Parsons, Michael Stumm Technical Report CSRI-339 November 1995 vi. Multiple Processor Systems, "Steve Armstrong" chapter08 vii. Lecture19, Richard S. Hall, Software Development for Parallel and Multi-Core Processing, Kenn R. Luecke, The Boeing Company,USA viii. Chapter 2, Multi-core and Many-core Processor Architectures A. Vajda, Programming Many-Core Chips, DOI 10.1007/978-1-4419-9739-5_2, © Springer Science+Business Media, LLC 2011
- 51. 50 Conclusion As described in this research report, Multiprocessing operating systems has become a highly developing area today. The computational performance of multiprocessors continues to improve by leaps and bounds fueled in part by rapid improvements in processor and interconnection technology. The performance of multiprocessing operating systems have becomes ever more critical through avoiding the obstacles of them. So, as IT graduates it is our objective to be informed on this growing trend in the world.