








































MySQL NDB Cluster 101
- 2. MySQL Cluster Proven in serving billions of people every day when making phone calls, playing online games or handling financial transactions.
- 3. Massively linear scale Always-On 99.9999% Availability Sharded In-Memory Datasets Always Consistent Parallel Real-Time Performance. Auto-partitioning, data distribution and replication built-in. Read- and Write Scale-Out to many TB on commodity hardware. Designed for mission critical systems. Masterless, shared-nothing with no single point of failure. Transactional consistency across distributed and partitioned dataset. Out of the box straightforward application programming. Ease of use Open Source Written in C++. Can be used standalone or with MySQL as a SQL front-end.
- 4. NDB is the highest throughput distributed, in-memory, transactional database in the world. It’s open source!
- 5. Horizontal and vertical scale with MySQL Cluster 15TB in-memory per node 100+TB with on-disk 100+TB to 5 PB in a single cluster 1 - 2GB/sec read/write transactions per shard 400k TPM DBT2 per 1 CPU socket 100+ data nodes 1-4 replicas 10k threads for parallel query processing
- 6. Cluster drives systems with massive scale and real-time answering times 100M trades analyzed every year 20B $ volume every day 2+B mobile phone users world wide 100+M in a single installation 30+M active gamers every month 12+M in one multi-player > > >
- 7. MySQL Cluster linear scale NoSQL Performance Confidential – Oracle Internal/Restricted/Highly Restricted Memory optimized tables Durable Mix with disk-based tables Parallel table scans for non-indexed searches MySQL Cluster FlexAsych 200M NoSQL Reads/Second !-!!!! !50,000,000!! !100,000,000!! !150,000,000!! !200,000,000!! !250,000,000!! 2! 4! 6! 8! 10! 12! 14! 16! 18! 20! 22! 24! 26! 28! 30! 32! Reads!per!second! Data!Nodes! FlexAsync!Reads!
- 8. MySQL Cluster Industries Telecom Gaming & Massive Parallel Online Games Financials
- 9. MySQL Cluster Use Cases • IOT - applications that write massive amounts of data in short periods of time • Shopping carts - durable, fast and frequent updates • User tracking and monitoring • Authentication and session management systems - real-time user verification • User profile and directories - reliable real-time information store • Messaging systems
- 10. Use cluster if you need Performance Read and write scalability Real-time in-memory Super low guaranteed latency Auto-Sharding Elastic Consistency Always on Always consistent ACID Global consistent view of the data data Cross-shard, cross- replica foreign keys SQL and NoSQL Distributed key value Advanced joins Parallel distributed query Highly Available Simple HA Simple programing
- 11. MySQL Cluster Usage • Key Value store + High Availability, Scale-Out, Durability • Transactional object store + Multi row transactions and consistency • Relational database + SQL joins, foreign keys, triggers, stored procedures, generated columns, JSON, GIS, … •
- 12. Usages
- 13. Confidential – Oracle Internal/Restricted/Highly Restricted Steel Belted Radius Carrier Server Provides centralized Authentication, Authorization, and Accounting (AAA or Triple A) management for users who connect and use a network service. https://www.juniper.net/documentation/en_US/sbr-carrier8.3.0 Juniper Radius Server Switch Scalable Session State Register MySQL Cluster
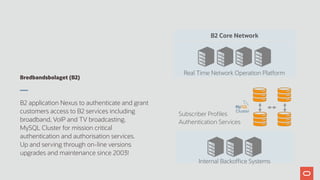
- 14. Bredbandsbolaget (B2) B2 application Nexus to authenticate and grant customers access to B2 services including broadband, VoIP and TV broadcasting. MySQL Cluster for mission critical authentication and authorisation services. Up and serving through on-line versions upgrades and maintenance since 2003! Real Time Network Operation Platform Internal Backoffice Systems Subscriber Profiles Authentication Services B2 Core Network
- 15. Stream processing in the financial industry Live trading data Kafka Messages Message Formatting Message Event Bus NDB native Client processors
- 16. Confidential – Oracle Internal/Restricted/Highly Restricted Hadoop (HopsFS) with MySQL Cluster NameNodes Leader HDFS Client DataNodes hops.io ClusterJ Small Files
- 17. Architecture Clients Cluster front- ends and connectors Data Nodes Partitioning- and distribution engine
- 18. Deployment examples Dev setup App or MySQL Server connecting directly locally to single data node. High available setup Co-located app/MySQL Server and data nodes using shared memory connections. Classical 3-tier setup Redundant SQL and NoSQL mixed access Multiple SQL nodes and native node.js accessing same datasets
- 19. Sharding and redundancy with no single point of failure Multiple copies of data are maintained for availability A group of data nodes shares the same data 1 - 4 replicas
- 20. High availability • Up to 4 replicas per shard • All replicas active • Always consistent • Microsecond failover
- 21. High availability • Majority for 3 and 4 nodes • Arbitration for 2 replicas • Proudly using 2-phase
- 22. Lets crash an Availability Zone (AD) • No service interruption source: LogicalClocks, MySQL Innovation Day, January 23, 2019
- 23. Synchronous replication locally and asynchronous between physical locations • With awareness of data locality and availability domains for cloud Cluster Data Nodes Replication Btw, conflict detection and automated resolution.
- 24. Data distribution • Auto-sharding and distribution No name-node or central master • Each dataset is split into fragments and distributed across data nodes • Within a cluster data is always transactionally consistent MySQL Cluster Data Nodes PK Service Data 253 Tiktok xxx 892 Snapchat xxx 253 Discord xxx 739 Instagram xxx
- 25. Data distribution • Partition of all data to thousands of virtual partitions • Virtual partitions distributed to data nodes … PK Service Data 253 Tiktok xxx 892 Snapchat xxx 253 Discord xxx 739 Instagram xxx
- 26. Data distribution • Deterministic, random distribution by default • Data in up to 32 data node local partitions • each controlled by their own threads • key to parallel query processing PK Service Data 253 Tiktok xxx 892 Snapchat xxx 253 Discord xxx 739 Instagram xxx
- 27. Data distribution and HA • Each partition is synchronously replicated to peer data nodes • ReplicaSets are called Node Group • All partitions active for read and write PK Service Data 253 Tiktok xxx 892 Snapchat xxx 253 Discord xxx 739 Instagram xxx Node Group Node Group
- 28. On-line Scaling and Elasticity - Repartitioning • Virtual partitions re-distributed on-line when adding more data nodes • Designed to be a slow background process not impacting real-time performance.
- 29. On-line Scaling and Elasticity - Repartitioning • Minimal amount of data moved • No re-hashing necessary • Similar to consistent hashing
- 30. Writing data writes Data Memory (RAM) • Memory is locked so it won’t swap
- 31. Writing data • Writes log to disk asynchronously in background - key to real-time in-memory transactions • Partial checkpoints of data memory - fast node starts and system recovery Flush writes to disk in background checkpoints writes … Data Memory (RAM)
- 32. Writing data • Writes go to data memory and commit log • In-memory data reads never involve disks Flush writes to disk in background checkpoints Commit Log (REDO) writes … time … Data Memory (RAM)
- 33. Data Node Multiple Threads per data node Parallel execution of … multiple queries from … … multiple users on … … multiple MySQL Servers Communication with signals Goal: minimize context switching NIC Main thread Local Data Managers Receive Send Disk/SSD IO DataMemory (RAM)
- 34. Lock free multi core VM • Data is partitioned inside the data nodes • Communication asynchronously, event driven on cluster’s VM • No group communication - instead using Distributed row locks Non-blocking 2-phase commit NIC Main thread Local Data Managers Receive Send Disk/SSD IO DataMemory (RAM)
- 35. Queries in multithreaded NDB Virtual Machine • Even a single query from MySQL Server executed in parallel DataMemory (RAM) QUERY …
- 36. Massive parallel system executing parallel queries Receive Send Transaction Data Manager Data Node Data Node Receive Send Transaction Data Manager
- 37. Data distribution awareness • Key-value with hash on primary key • Complemented by ordered in-memory- optimised T-Tree indexes for fast searches For PK operations NDB data partition is simply calculated PK Service Data 739 Instagram xxx
- 38. Consolidated view of distributed data • Clients and MySQL Servers see a consolidated view of the distributed data • Joins are pushed down to data nodes • Parallel cross-shard execution in the data nodes • Result consolidation in MySQL Server Consolidated view of distributed data
- 39. Parallel cross-partition queries • Parallel execution on the data nodes and within data nodes • 64 cpus per node leveraged • parallelizes single queries • 144 data nodes x 32 partitions = 4608! CPUs + 32 other processing threads per node • automatic batching, event driven and asynchronous PK Service Data 253 Tiktok xxx 892 Snapchat xxx 253 Discord xxx 739 Instagram xxx
- 40. Parallel cross-partition queries $ SELECT * FROM services LEFT JOIN data USING(service) Data Nodes Service Data Snapchat xxx PK Service 892 Snapchat PK Service Data 892 Snapchat xxx … … … Parallel execution of single queries on all data nodes and within data nodes
- 41. MySQL Cluster - matured with advanced features • Disk tables for even bigger data • IO control for efficient disk usage • Local domain / availability domain • Shared memory connections • Sub-second failover and self-healing • Online scaling, maintenance and version upgrades • Heartbeat mechanisms to support nontrivial network failures • many more …
- 42. Thank You Bernd Ocklin Snr Director MySQL Cluster Development