Natural Language Processing (NLP) with .NET for #dotnetby meetup-29
Download as PPTX, PDF1 like413 views

Доклад посвящен обработке естественного языка (NLP) с использованием .NET, в котором рассматриваются основные задачи NLP, такие как сегментация предложений, анализ эмоций и автоматический перевод. Также обсуждаются архитектуры применения NLP в корпоративных поисковых системах и чат-ботах, а также доступные инструменты и NuGet пакеты. Основное внимание уделяется практическим примерам на F# и особенностям работы с различными API.



















































































Natural Language Processing (NLP) with .NET for #dotnetby meetup-29
- 1. Natural Language Processing (NLP) with .NET @sergey_tihon #dotnetby meetup-29
- 2. Sergey Tihon • Solution Architect, EPAM Systems • Microsoft MVP (Development Technologies) • Author of F# Weekly (sergeytihon.com) • Open Source enthusiast • Stanford.NLP.NET • OpenNLP.NET • SwaggerProvider • … (fsprojects) • https://twitter.com/sergey_tihon • Belarus, Minsk 2@sergey_tihon
- 3. Про что этот доклад 1. Разберемся что такое NLP, какие задачи решаются и где они встречаются @sergey_tihon 3
- 4. Про что этот доклад 1. Разберемся что такое NLP, какие задачи решаются и где они встречаются 2. Разберем Reference Architecture • Enterprise Document Search • Chat bots @sergey_tihon 4
- 5. Про что этот доклад 1. Разберемся что такое NLP, какие задачи решаются и где они встречаются 2. Разберем Reference Architecture • Enterprise Document Search • Chat bots 3. Разберем доступные нам инструменты • .NET Framework • Cloud API (MS LUIS, IBM Watson, Google) • Популярные NuGet пакеты (Stanford NLP, OpenNLP и другие) @sergey_tihon 5
- 6. Про что этот доклад 1. Разберемся что такое NLP, какие задачи решаются и где они встречаются 2. Разберем Reference Architecture • Enterprise Document Search • Chat bots 3. Разберем доступные нам инструменты • .NET Framework • Cloud API (MS LUIS, IBM Watson, Google) • Популярные NuGet пакеты (Stanford NLP, OpenNLP и другие) 4. Примеры будут на F# @sergey_tihon 6
- 7. Про что этот доклад 1. Разберемся что такое NLP, какие задачи решаются и где они встречаются 2. Разберем Reference Architecture • Enterprise Document Search • Chat bots 3. Разберем доступные нам инструменты • .NET Framework • Cloud API (MS LUIS, IBM Watson, Google) • Популярные NuGet пакеты (Stanford NLP, OpenNLP и другие) 4. Примеры будут на F# 5. Не будет примеров работы с русским языком @sergey_tihon 7
- 8. Про что этот доклад 1. Разберемся что такое NLP, какие задачи решаются и где они встречаются 2. Разберем Reference Architecture • Enterprise Document Search • Chat bots 3. Разберем доступные нам инструменты • .NET Framework • Cloud API (MS LUIS, IBM Watson, Google) • Популярные NuGet пакеты (Stanford NLP, OpenNLP и другие) 4. Примеры будут на F# 5. Не будет примеров работы с русским языком 6. Но (я надеюсь) каждый узнает что-то новое! @sergey_tihon 8
- 9. Русский язык Каталог NLPub организован по вики- принципу и содержит сведения об инструментах, ресурсах, методах и алгоритмах, необходимых для успешного построения систем автоматической обработки русского языка https://nlpub.ru/Обработка_текста • MyStem - морфологический анализ текста на русском языке https://tech.yandex.ru/mystem/ • Томита-парсер - извлечения структурированных данных из текста на естественном языке https://tech.yandex.ru/tomita/ • Linguistic technologies (API) • Translate API • Dictionary API • SpeechKit • Predictor API @sergey_tihon 9
- 10. Задачи в NLP @sergey_tihon 10
- 11. Задачи в NLP • Sentence Segmentation – разбить текст на предложения • Tokenization – разбить предложение на токены (слова + символы) • Part-Of-Speech Tagging – определить часть речи (слова в предложении) • Stemming – найти базовую форму слова (например убрать временную форму) • Named Entity Recognition – распознать какие токены являются известными сущностями (Имя, Дата, Место) • Speech Synthesis – синтез речи (текст –> речь) 11@sergey_tihon
- 12. Задачи в NLP • Syntactic Parsing – построить синтаксическое дерево • Sentiment Analysis – определить эмоцию в тексе (на сколько юзер доволен или недоволен) • Relationship Extraction – найти отношения между словами в предложении (объект – субъект) • Text Similarity – посчитать на сколько похожи два текста • Information Extraction – извлечение структурированной информации из текста • Speech Recognition – распознавание речи (речь –> текст) 12@sergey_tihon
- 13. Задачи в NLP • Machine Translation – автоматический машинный перевод текста или аудио • Natural Language Generation – генерация текста (описать что нарисовано на картинке) • Automatic Summarization – сгенерировать текст описывающий увиденное (описание к видео) • Question Answering – понять и найти ответ на вопрос • Conversation Interfaces – система взаимодействующая с юзером через диалог (чат-боты) 13@sergey_tihon
- 15. Документы хранятся в разных системах 15@sergey_tihon
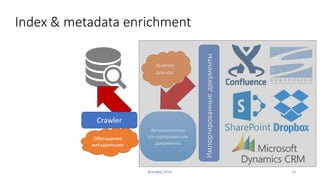
- 18. Index & metadata enrichment 18@sergey_tihon Импортированныедокументы Автоматически сгенерированные документы Анализ док-ов Crawler Обогащение метаданными
- 21. Отличия от веб-поиска (Google/Yandex) 1. Поиск по документам а не по веб страницам a) Много повторяющегося текста и дубликатов (нету page / site rank) b) Большие документы (презентации достигают 2Гб) c) Сложности с онлайн превью @sergey_tihon 21
- 22. Отличия от веб-поиска (Google/Yandex) 1. Поиск по документам а не по веб страницам a) Много повторяющегося текста и дубликатов (нету page / site rank) b) Большие документы (презентации достигают 2Гб) c) Сложности с онлайн превью 2. “Мало” пользователей (по сравнению с Google/Yandex) a) Сложно обучаться на поведении пользователей b) Узкоспециализированные запросы c) Приходится обучатся на контенте и сильно зависеть от процессов компании и данных в разных системах. @sergey_tihon 22
- 23. 23@sergey_tihon
- 24. Синтез речи (Speech Synthesis) 24 System.Speech.dll присутствует в .NET начиная с версии 3.0 (т.е. с 2006г) @sergey_tihon
- 25. Распознавание речи (Speech Recognition) 25 Грамматика распознаваемого языка – это набор правил или ограничений, которые определяют, что механизм распознавания может распознать как “значимый ввод”. Речь ограниченная грамматикой Свободная речь @sergey_tihon
- 26. Распознавание речи (Speech Recognition) 26@sergey_tihon
- 27. System.Speech vs Microsoft.Speech https://msdn.microsoft.com/en-us/magazine/dn857362.aspx System.Speech.dll Microsoft.Speech.dll Native code API (C++) Managed code API (C#) Часть OS (Windows Vista+) Устанавливается отдельно Не распространяется с приложением Можно распространять вместе с приложением Работает с грамматиками (Grammars) или со свободной речью Нужно создавать грамматики (Grammars) Тренируется под юзера Не нуждается в тренировке 27@sergey_tihon
- 29. Популярные области применения Чат-боты Персональные ассистенты Поиск 29@sergey_tihon
- 30. Чат-боты
- 31. 31 Архитектура информационного чат-бота 1. Пользователь начинает общение с ботом @sergey_tihon
- 32. 32 Архитектура информационного чат-бота 1. Пользователь начинает общение с ботом 2. Авторизуемузнаем пользователя @sergey_tihon
- 33. 33 Архитектура информационного чат-бота 1. Пользователь начинает общение с ботом 2. Авторизуемузнаем пользователя 3. Пользователь задает вопрос @sergey_tihon
- 34. 34 Архитектура информационного чат-бота 1. Пользователь начинает общение с ботом 2. Авторизуемузнаем пользователя 3. Пользователь задает вопрос 4. Когнитивные сервисы распознают намеренье пользователя @sergey_tihon
- 35. 35 Архитектура информационного чат-бота 1. Пользователь начинает общение с ботом 2. Авторизуемузнаем пользователя 3. Пользователь задает вопрос 4. Когнитивные сервисы распознают намеренье пользователя 5. В случае неоднозначности, намеренье уточняется @sergey_tihon
- 36. 36 Архитектура информационного чат-бота 1. Пользователь начинает общение с ботом 2. Авторизуемузнаем пользователя 3. Пользователь задает вопрос 4. Когнитивные сервисы распознают намеренье пользователя 5. В случае неоднозначности намеренье уточняется 6. Бот делает запрос за данными @sergey_tihon
- 37. 37 Архитектура информационного чат-бота 1. Пользователь начинает общение с ботом 2. Авторизуемузнаем пользователя 3. Пользователь задает вопрос 4. Когнитивные сервисы распознают намеренье пользователя 5. В случае неоднозначности намеренье уточняется 6. Бот делает запрос за данными 7. Собираем телеметрию чтобы следить за поведением и улучшать бота https://dev.botframework.com @sergey_tihon
- 38. Language Understanding Intelligent Service (LUIS) 38@sergey_tihon
- 39. Что такое намеренье (intent)? 39 Message from User "increase volume on TV" намеренье сущность @sergey_tihon
- 40. Что такое намеренье (intent)? 40 Message from User "increase volume on TV" намеренье сущность @sergey_tihon
- 41. Conversation Conversation Virtual Agent Language Language Translator Natural Language Classifier Speech Speech to Text Text to Speech Vision Visual Recognition Empathy Personality Insights Tone Analyzer Discovery Discovery Natural Language Understanding Discovery News Knowledge Studio Аналог LUIS.ai
- 43. Что есть в NuGet? 43@sergey_tihon
- 44. 01. Stanford.NLP.CoreNLP (74887) 02. Syn.Bot (30506) 03. AboditNLP (28543) 04. AboditUnits (21475) 05. Stanford.NLP.POSTagger (18541) 06. Stanford.NLP.NER (18256) 07. Stanford.NLP.Parser (16880) 08. OpenNLP (15033) 09. Language Detection (11171) 10. Autofac.Extras.AboditNLP (10978) 44@sergey_tihon 01. Stanford.NLP.CoreNLP (183571) 02. Syn.Bot (34648) +13.5% 03. Microsoft.Recognizers.Text (32467) New 04. AboditNLP (31821) +21% 05. Microsoft.Recognizers.Text.Number (31760) 06. Microsoft.Recognizers.Text.NumberWithUnit (31670) 07. Microsoft.Recognizers.Text.DateTime (31198) 08. AboditUnits (24383) 09. Stanford.NLP.POSTagger (20880) 10. Stanford.NLP.NER (20581) 11. OpenNLP (19784) +32% 12. Stanford.NLP.Parser (17760) 13. Language Detection (16326) +46% 2018, April 2018, August
- 45. 01. Stanford.NLP.CoreNLP (183571) 02. Syn.Bot (34648) 03. Microsoft.Recognizers.Text (32467) 04. AboditNLP (31821) 05. Microsoft.Recognizers.Text.Number (31760) 06. Microsoft.Recognizers.Text.NumberWithUnit (31670) 07. Microsoft.Recognizers.Text.DateTime (31198) 08. AboditUnits (24383) 09. Stanford.NLP.POSTagger (20880) 10. Stanford.NLP.NER (20581) 11. OpenNLP (19784) 12. Stanford.NLP.Parser (17760) 13. Language Detection (16326) 45@sergey_tihon
- 46. 46@sergey_tihon
- 47. 01. Stanford.NLP.CoreNLP (183571) 02. Syn.Bot (34648) 03. Microsoft.Recognizers.Text (32467) 04. AboditNLP (31821) 05. Microsoft.Recognizers.Text.Number (31760) 06. Microsoft.Recognizers.Text.NumberWithUnit (31670) 07. Microsoft.Recognizers.Text.DateTime (31198) 08. AboditUnits (24383) 09. Stanford.NLP.POSTagger (20880) 10. Stanford.NLP.NER (20581) 11. OpenNLP (19784) 12. Stanford.NLP.Parser (17760) 13. Language Detection (16326) 47@sergey_tihon
- 48. LanguageDetection .NET порт Language Detection Library for Java • Языковые профили на основе данных из Wikipedia • Определяет язык текста используя наивный байесовский фильтр • 99%+ точность для 53 языков 48@sergey_tihon
- 49. 01. Stanford.NLP.CoreNLP (183571) 02. Syn.Bot (34648) 03. Microsoft.Recognizers.Text (32467) 04. AboditNLP (31821) 05. Microsoft.Recognizers.Text.Number (31760) 06. Microsoft.Recognizers.Text.NumberWithUnit (31670) 07. Microsoft.Recognizers.Text.DateTime (31198) 08. AboditUnits (24383) 09. Stanford.NLP.POSTagger (20880) 10. Stanford.NLP.NER (20581) 11. OpenNLP (19784) 12. Stanford.NLP.Parser (17760) 13. Language Detection (16326) 49@sergey_tihon
- 50. Abodit NLP Abodit NLP это проект Ian Mercer’a. Проект начинался как персональный, с целью соединить системы умного дома с чат-системами. Вместо задач общего понимания текста, фокусируется на задачах распознавания токенов и сопоставления их с реальными объектами с которым можно взаимодействовать (комнаты, датчики, системы управления и т.д.) http://nlp.abodit.com 50@sergey_tihon
- 51. 01. Stanford.NLP.CoreNLP (183571) 02. Syn.Bot (34648) 03. Microsoft.Recognizers.Text (32467) 04. AboditNLP (31821) 05. Microsoft.Recognizers.Text.Number (31760) 06. Microsoft.Recognizers.Text.NumberWithUnit (31670) 07. Microsoft.Recognizers.Text.DateTime (31198) 08. AboditUnits (24383) 09. Stanford.NLP.POSTagger (20880) 10. Stanford.NLP.NER (20581) 11. OpenNLP (19784) 12. Stanford.NLP.Parser (17760) 13. Language Detection (16326) 51@sergey_tihon
- 52. Syn.Bot – OSCOVA & SIML Автономный фреймворк для разработки ботов (с поддержкой .NET Standard, Xamarin, Mono). Позволяет создавать ботов которые работают офлайн. Поддерживают: - диалоги - распознавание намеренья - распознавание сущностей 52@sergey_tihon Synthetic Intelligence Network a brand of REVARN™ Cybernetics.
- 53. 01. Stanford.NLP.CoreNLP (183571) 02. Syn.Bot (34648) 03. Microsoft.Recognizers.Text (32467) 04. AboditNLP (31821) 05. Microsoft.Recognizers.Text.Number (31760) 06. Microsoft.Recognizers.Text.NumberWithUnit (31670) 07. Microsoft.Recognizers.Text.DateTime (31198) 08. AboditUnits (24383) 09. Stanford.NLP.POSTagger (20880) 10. Stanford.NLP.NER (20581) 11. OpenNLP (19784) 12. Stanford.NLP.Parser (17760) 13. Language Detection (16326) 53@sergey_tihon
- 54. Stanford NLP Group https://nlp.stanford.edu Stanford CoreNLP is written in Java; recent releases require Java 1.8+ 54@sergey_tihon
- 55. IKMV.NET Compiler. http://www.ikvm.net IKVMCompiler Java Class A Java Class B Java Class C A .NET implementation of the Java class libraries .NET Class A .NET Class B .NET Class C My.dllMy.jar 55@sergey_tihon
- 56. Терминология Аннотация – метаданные, ассоциированные с объектом (текстом, предложением, словом) Аннотатор – объект который добавляет одну или несколько аннотаций к объекту (может иметь зависимости на другие аннотации) Pipeline – последовательность аннотаторов 56@sergey_tihon
- 57. Stanford CoreNLP Server - http://corenlp.run 57@sergey_tihon
- 59. Примеры или какой пакет выбрать? // Подсказка: Вот этот! ;) // P.S. Но не больше одного за раз !!! 59@sergey_tihon
- 60. Простой API для CoreNLP Функциональность Аннотация Класс Метод Sentence Splitting ssplit Document .sentences() / .sentence(int) Coreference Resolution dcoref Document .coref() Tokenization tokenize Sentence .words() / .word(int) Part of Speech Tagging pos Sentence .posTags() / .posTag(int) Lemmatization lemma Sentence .lemmas() / .lemma(int) Named Entity Recognition ner Sentence .nerTags() / .nerTag(int) Constituency Parsing parse Sentence .parse() Dependency Parsing depparse Sentence .governor(int) / .incomingDependencyLabel(int) Natural Logic Polarity natlog Sentence .natlogPolarities() / .natlogPolarity(int) Open Information Extraction openie Sentence .openie() / .openieTriples() 60@sergey_tihon
- 61. Простой API для CoreNLP Функциональность Аннотация Класс Метод Sentence Splitting ssplit Document .sentences() / .sentence(int) Coreference Resolution dcoref Document .coref() Tokenization tokenize Sentence .words() / .word(int) Part of Speech Tagging pos Sentence .posTags() / .posTag(int) Lemmatization lemma Sentence .lemmas() / .lemma(int) Named Entity Recognition ner Sentence .nerTags() / .nerTag(int) Constituency Parsing parse Sentence .parse() Dependency Parsing depparse Sentence .governor(int) / .incomingDependencyLabel(int) Natural Logic Polarity natlog Sentence .natlogPolarities() / .natlogPolarity(int) Open Information Extraction openie Sentence .openie() / .openieTriples() 61@sergey_tihon Не очень-то просто на самом деле
- 62. Простой API для CoreNLP 62@sergey_tihon
- 63. Запуск CoreNLP Server локально # Запуск сервера используя все jar файлы текущей директории # В корневой директории распакованного zip архива, используя Java8 java -mx4g –cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer –port 9000 –timeout 15000 https://stanfordnlp.github.io/CoreNLP/corenlp-server.html 63@sergey_tihon
- 64. CoreNLP Server REST API @sergey_tihon 64
- 65. Клиент для Core NLP Server До pipeline.annotate: После pipeline.annotate: 65@sergey_tihon
- 66. Из чего состоит pipeline (Аннотаторы) Аннотатор Имя класса Генерируемые аннотации tokenize TokenizerAnnotator TokensAnnotation ssplit WordsToSentencesAnnotator SentencesAnnotation pos POSTaggerAnnotator PartOfSpeechAnnotation lemma MorphaAnnotator LemmaAnnotation ner NERClassifierCombiner NamedEntityTagAnnotation and NormalizedNamedEntityTagAnnotation parse ParserAnnotator TreeAnnotation, BasicDependenciesAnnotation, CollapsedDependenciesAnnotation, CollapsedCCProcessedDependenciesAnnotation dcoref DeterministicCorefAnnotator CorefChainAnnotation Полный список - https://stanfordnlp.github.io/CoreNLP/annotators.html 66@sergey_tihon
- 67. Извлечение данные из аннотаций Annotation, CoreMap и CoreLabel работают как словарь, где ключом является java.lang.Class аннотации 67@sergey_tihon
- 69. 69@sergey_tihon
- 70. 01. Stanford.NLP.CoreNLP (183571) 02. Syn.Bot (34648) 03. Microsoft.Recognizers.Text (32467) 04. AboditNLP (31821) 05. Microsoft.Recognizers.Text.Number (31760) 06. Microsoft.Recognizers.Text.NumberWithUnit (31670) 07. Microsoft.Recognizers.Text.DateTime (31198) 08. AboditUnits (24383) 09. Stanford.NLP.POSTagger (20880) 10. Stanford.NLP.NER (20581) 11. OpenNLP (19784) 12. Stanford.NLP.Parser (17760) 13. Language Detection (16326) 70@sergey_tihon
- 71. OpenNLP https://opennlp.apache.org Описание: • Language Detector • Sentence Detector • Tokenizer • Name Finder (NER) • Document Categorizer • Part-of-Speech Tagger • Lemmatizer • Chunker • Parser • Coreference Resolution Мануалы по тренировке новых моделей! 71@sergey_tihon
- 72. Open NLP для .NET Независимое переписывание Apache OpenNLP на C#: • Поддержка .net standard 2.0 • Обратно совместима с моделями от • Переписывается вручную (без автоматических тулов) Хорошо: • Полностью совпадает по функционалу с Java версией (1.9.1) Плохо: • Нет поддержки .net core • Зависит от IKVM.NET Knuppe.SharpNL https://github.com/knuppe/SharpNL https://github.com/sergey-tihon/OpenNLP.NET OpenNLP.NET 72@sergey_tihon
- 74. Дерево разбора предложения 74 Penn Treebank II tag set Part-of-speech tags (Части речи) • DT – determiner (определяющее слово) • JJ – adjective (прилагательное) • NN – noun (существительно) • VBZ - verb, 3rd person singular present (глагол, 3ее лицо, ед. число) • IN - conjunction, subordinating or preposition (союз, предлог) Chunk tags (Групповые теги) • NP – noun phrase (словосочетание) • PP – prepositional phrase (фраза с предлогом) • VP – verb phrase (глагольная фраза) Скриншот c corenlp.run @sergey_tihon
- 75. Понимание вопросов 75@sergey_tihon http://sergey-tihon.github.io/Stanford.NLP.Fsharp/so_questions.html Making Tree Kernels practical for Natural Language Learning http://www.aclweb.org/anthology/E06-1015 Assistant Search 1. Получить вопрос 2. Построить синтаксическое дерево 3. Выделить ключевые слова и фразы 4. Построить запрос в поисковую систему
- 76. Обучение модели распознавания токенов (TokenNameFinderModel, NER) 76@sergey_tihon
- 78. Советы 1. Проверяйте наличие облачного API решающего вашу задачу 1. Проще всего использовать 2. Цена зависит от количества запросов 3. Нужно оправлять данные за пределы организации 4. Чаще всего модели не настраиваются под ваши данные @sergey_tihon 78
- 79. Советы 1. Проверяйте наличие облачного API решающего вашу задачу 1. Проще всего использовать 2. Цена зависит от количества запросов 3. Нужно оправлять данные за пределы организации 4. Чаще всего модели не настраиваются под ваши данные 2. Прототипируйте / проверяйте идеи со Stanford NLP 1. Качественные модели 2. Pipeline обработки данных расширяем, достаточно много примеров 3. Лицензия GLP v3 (платно для коммерческого использования) @sergey_tihon 79
- 80. Советы 1. Проверяйте наличие облачного API решающего вашу задачу 1. Проще всего использовать 2. Цена зависит от количества запросов 3. Нужно оправлять данные за пределы организации 4. Чаще всего модели не настраиваются под ваши данные 2. Прототипируйте / проверяйте идеи со Stanford NLP 1. Качественные модели 2. Pipeline обработки данных расширяем, достаточно много примеров 3. Лицензия GLP v3 (платно для коммерческого использования) 3. Используйте OpenNLP в остальных случаях 1. Лицензия Apache (всегда бесплатно) 2. Есть реализация под .NET Core @sergey_tihon 80
- 82. Dan Jurafsky & Chris Manning: Natural Language 82@sergey_tihon
- 83. Natural Language Processing with Deep Learning (Winter 2017) http://web.stanford.edu/class/cs224n/ 83@sergey_tihon
Editor's Notes
- #4: По простому – это извлечение данных их текста на одном из человеческих языков. Какие задачи попадают под это определение мы увидим в процессе доклада.
- #7: Примеров кода будет не много
- #8: Мне не приходилось решать задачи обработки русских текстов
- #10: По этой теме наверняка можно подготовить полноценный доклад сравнивая качество работы различных утилит Стоит упомянуть два ресурса с которых стоит начать изучать этот вопрос NLPub вики и доступных инструментах Yandex – можно предположить что они не плохо справляются
- #13: Синтактическое дерево является важной подзадачей для решение Sentiment Analysis Information Extraction Question Answering Grammar checking
- #15: НЕ ПОИСК РАДИ ПОИСКА - Специфический домен (контент) Более узкая задача
- #16: Пользователи наиболее походящее и удобное им хранилище для документов Внутри компании часто есть внутренние самодельные системы где хранятся документы
- #17: Собираем документы в одну систему\базу чтобы не зависеть от других систем работать автономно Минимизировать нагрузку на другие системы Переопределить права доступа к документам МИНУС: удваивается место занимаемое документами.
- #18: Анализируем и извлекаем потенциально переиспользуемые части документом Слайды Вопросы \ ответы Описание кейсов \ опыта компании ПЕРВЫЙ NLP компонент Что есть вопрос?
- #19: Индексирование файлов и обогащение метаданными Классификация документов Кейсы \ резюме \ Технологии ВТОРОЙ NLP компонент – Information Retrival
- #20: Добавляем поиска и персонально ассистента, который Помогает понять как пользоваться системой и что она умеет Помогает понять что ищет пользователь и как преобразовать его намеренье (intent) в поисковой запрос Помогает настраивать релевантность
- #21: помогает искать материалы разбросанные по разным системам не меняя процессы внутри компании Много возможностей по применению NLP
- #22: Особенности системы ( по сравнению с
- #23: Особенности системы ( по сравнению с
- #26: Наибольшие проблемы распознавания речи Отделения шума от речи Акценты и произношения
- #30: Компании которые делают поисковики или ботов, выставляют часть своей инфраструктуры в виде АПИ, чтобы еще заработать =)
- #31: По архитектуре от MS
- #39: Intent Entity Pretrained entities Sample intent
- #40: Определили наиболее вероятное намеренье
- #41: Нашли сущности, с которыми надо произвести действие
- #43: Какие языки поддерживает - Arabic, English, Spanish, French, Brazilian Portuguese, Japanese, and Mandarin В реальном времени - скорость распознавания равно времени аудио
- #44: К сожалению мы пока не можем сортировать результаты поиска в NuGet по количеству скачиваний, но может воспользоваться NuGet API
- #51: 10 лет занимается созданием и оборудованием умного дома general purpose natural language engine for any command, control or query application
- #59: Есть сайтик для .NET версии с коллекцией примеров на C# и F# Почему больше всего скачиваний? Широкий класс решаемых задач Хорошее качество моделей Много примеров и ответов на SO (особенно про Java версию)
- #61: посмотрите сами, примеры на сайте
- #62: посмотрите сами, примеры на сайте
- #72: Весьма хорошие гайды по тренировке своих моделей (по сравнению со Stanford NLP) Лицензия Apache – используй где хочешь !
- #73: OpenNLP – немного устаревшая и не особо активно обновляющаяся версия
- #75: Парсер возвращает дерево, которое описывает грамматическую структуру предложение - Является подзадачей для более сложных задач
- #77: Часто возникает задача распознавания кастомных сущностей Распознавание технологий Номеров заказов Законов Договоров
- #83: Появился в 2014
- #84: Появился в 2017