Neural Discrete Representation Learning - A paper review
0 likes•124 views

1) The paper introduces Vector Quantization Variational Autoencoders (VQ-VAEs), which use discrete rather than continuous latent codes. This allows the prior to be learned from the data distribution rather than assuming a fixed prior. 2) VQ-VAEs train with a loss that enforces the encoder outputs to be close to embeddings in a learned codebook. This allows generating new samples by sampling the prior rather than relying only on reconstruction. 3) Experiments show VQ-VAEs can generate images, video, and speech that retains semantic content, while achieving likelihoods comparable to continuous latent variable models. The discrete latent space captures long-term dependencies without supervision.


















Neural Discrete Representation Learning - A paper review
- 1. Abhishek Koirala Neural Discrete Representation Learning Neural Discrete Representation Learning (DeepMind Research) Paper Review Authors: ● Aaron van den Oord ● Oriol Vinyals ● Koray Kavukcuoglu
- 2. Abhishek Koirala Neural Discrete Representation Learning What the paper introduces? Concept of VQ-VAEs Different from VAEs in two ways 1) Encoder network outputs discrete rather than continuous codes 2) Prior is learnt from the latent distribution rather than static priors
- 3. Abhishek Koirala Neural Discrete Representation Learning AutoEncoders Limitations of AutoEncoders ● Fixed dimensional latent space ● Cannot generate new samples directly from latent space ○ Due to unstructured and messy latent space ● Difficulty in generating new variety of samples ○ Autoencoders only relies on reconstruction loss which limits variability
- 4. Abhishek Koirala Neural Discrete Representation Learning Variational AutoEncoders (VAE) ● Probabilistic modelling of latent space ● Generally enforcing a prior which is standard normal distribution ● Structured latent space ○ VAEs enforce probabilistic prior resulting in structured latent space ● Regularization and control over latent space ● Sampling based generation ○ Enables generation of new samples by sampling from the learned latent space distribution Limitation of VAEs ● Disentanglement of latent features ● Static prior ● Posterior collapse Joseph Rocca, Understanding Variational AutoEncoders
- 5. Abhishek Koirala Neural Discrete Representation Learning Vector Quantization - Variational AutoEncoders(VQ-VAE) ● Discrete latent representation ● Prior is learnt from the data rather than assuming it as static ● Avoid posterior collapse Additional Contributions ● Discrete latent model performs as well as its continuous counterpart ● When paired with a powerful prior, the samples are high quality on a wide range of applications such as image, speech and video generation
- 6. Abhishek Koirala Neural Discrete Representation Learning Vector Quantization - Variational AutoEncoders(VQ-VAE) Posterior Distribution Prior Distribution p(z) Posterior and priors in VAEs are assumed normally distributed In VQ-VAE ● Discrete latent variables ● Novel training method inspired by Vector Quantization ● Posterior and prior distributions are categorical Yang, Y. et. al(2019). Improving the classification effectiveness of intrusion detection by using improved conditional variational autoencoder and deep neural network. Sensors, 19(11), 2528.
- 7. Abhishek Koirala Neural Discrete Representation Learning Vector Quantization ● Codebook initialization: Create initial set of representative codewords serving as prototype for discrete latent variables ● Encoding: Map the input data to nearest codeword in codebook, quantizing the continuous values into discrete latent variables ● Discrete latent variables: Represent the input data using discrete latent variables obtained from encoding step ● Decoding: Reconstruct the data from discrete latent variables by mapping them back to the corresponding codewords in the codebook ● Training
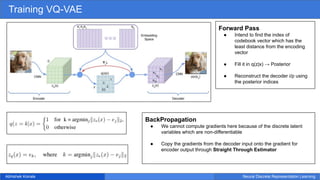
- 8. Abhishek Koirala Neural Discrete Representation Learning Training VQ-VAE Forward Pass ● Intend to find the index of codebook vector which has the least distance from the encoding vector ● Fill it in q(z|x) → Posterior ● Reconstruct the decoder i/p using the posterior indices BackPropagation ● We cannot compute gradients here because of the discrete latent variables which are non-differentiable ● Copy the gradients from the decoder input onto the gradient for encoder output through Straight Through Estimator
- 9. Abhishek Koirala Neural Discrete Representation Learning Training VQ-VAE Loss Function Reconstruction loss VQ Loss Commitment Loss Enforces reconstruction closer to input Enforces embedding space close to encoder input Enforces encoder output close to embedding space Stop Gradients (sg) used in both VQ loss and commitment loss for updating of embedding space parameters and encoder parameters respectively. Decoders → optimizes the reconstruction loss Encoder → optimizes the reconstruction loss and commitment loss Embeddings/Codebook → optimized by VQ loss The term β used in commitment loss depends on the scale of reconstruction loss . Higher the reconstruction loss~higher the β value to amplify the impact of commitment loss
- 10. Abhishek Koirala Neural Discrete Representation Learning Prior ● The prior is kept constant and uniform. ● An autoregressive distribution is fit over z, p(z) to generate x via ancestral sampling ● 2 autoregressive models discussed here ○ PixelCNN over discrete latent for images ○ WaveNet for raw audio Training of prior and VQ-VAE jointly is left as a future research
- 11. Abhishek Koirala Neural Discrete Representation Learning Experiments 1) Comparison with continuous variables CIFAR 10 dataset, ADAM optimizer, 50 samples used in training objective for VIMCO Models Features Results(bits/dim) VQ-VAE Discrete latent representation 4.67 VIMCO Gaussian or categorical priors 5.14 VAE Continuous variables 4.51 Note: bits/dim measures the average number of bits required to represent each dimension of input data. A lower value indicates better compression and reconstruction performance VQ-VAE becomes the first model that challenges the performance of continuous VAEs
- 12. Abhishek Koirala Neural Discrete Representation Learning Experiments 1) Images Experiment 1 ● Model achieves a reduction of approximately 42.6 bits per images ● A powerful prior model called PixelCNN is trained over the discrete latent space to capture global structures instead of low level image statistics ● Results are slightly blurry but still retain the overall content
- 13. Abhishek Koirala Neural Discrete Representation Learning Experiments 1) Images Experiment 2 ● Trained a PixelCNN prior on the 32*32*1 latent space using spatial masking ● Samples drawn from PixelCNN were mapped to pixel-space with decoder of VQ-VAE
- 14. Abhishek Koirala Neural Discrete Representation Learning Experiments 1) Images Experiment 3 ● Same experiment as 2 for 84*84*3 frames drawn from the DeepMind Lab environment ● Reconstruction looked nearly identical to their originals
- 15. Abhishek Koirala Neural Discrete Representation Learning Experiments 1) Images Experiment 4 ● Training of second VQ-VAE with a PixelCNN decoder on top of 21*21*1 latent space obtained from first vQ-VAE trained on DM-LAB frames ● Interesting setup, because VAE would suffer from “posterior collapse” due to powerful decoder enough to perfectly model the input data ● Posterior collapse not observed
- 16. Abhishek Koirala Neural Discrete Representation Learning Experiments 2) Audio Reconstructions Samples from prior Aäron van den Oord, Neural Discrete Representation Learning Aäron van den Oord, Neural Discrete Representation Learning Although the reconstructed waveforms are different, but the semantic meaning in the audio is retained without knowing any information about the language or speaker details
- 17. Abhishek Koirala Neural Discrete Representation Learning Experiments 2) Video
- 18. Abhishek Koirala Neural Discrete Representation Learning Conclusion ● Introduced VQ-VAE: combines VAEs with vector quantization. ● VQ-VAEs capture long-term dependencies in data. ● Successful experiments: generate images, video sequences, and meaningful speech. ● Discrete latent space learns important features without supervision. ● VQ-VAEs achieve comparable likelihoods to continuous latent variable models, model long-range sequences, and learn speech descriptors related to phonemes in an unsupervised fashion.
- 19. Abhishek Koirala Neural Discrete Representation Learning