
![Background
The recent success of neural language model is based on the scheme of
pre-train once, and fine-tune everywhere.
[Devlin et al. 19] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL 2019](https://image.slidesharecdn.com/neuralmaskgeneratorlearningtogenerateadaptivewordmaskingsforlanguagemodeladaptation-201113072119/85/Neural-Mask-Generator-Learning-to-Generate-Adaptive-Word-Maskings-for-Language-Model-Adaptation-2-320.jpg)
![Background
Recent Language Models (LM) are pre-trained on large and heterogeneous
dataset.
General Dataset
(e.g. Wikipedia)
Specific-Domain
Dataset
Further
Pre-training
[Beltagy et al. 19] SciBERT: A Pretrained Language Model for Scientific Text, EMNLP 2019.
[Lee et al. 20] BioBERT: a pre-trained biomedical language representation model for biomedical text mining, Bioinformatics 2020.
[Gururangan et al. 20] Don’t stop Pre-training: Adapt Language Models to Domains and Tasks, ACL 2020.
Some works propose further pre-training for LM adaptation.](https://image.slidesharecdn.com/neuralmaskgeneratorlearningtogenerateadaptivewordmaskingsforlanguagemodeladaptation-201113072119/85/Neural-Mask-Generator-Learning-to-Generate-Adaptive-Word-Maskings-for-Language-Model-Adaptation-3-320.jpg)
![Background
Masked Language Models (MLMs) objective has shown to be effective
for language model pre-training.
A myocardial infarction,
also known as a [MASK]
attack, occurs when blo
od flow decreases.
A myocardial infarction,
also known as a heart
attack, occurs when bl
ood flow decreases.
[Original] [Model Input] [Model Output]
heart
[Devlin et al. 19] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL 2019](https://image.slidesharecdn.com/neuralmaskgeneratorlearningtogenerateadaptivewordmaskingsforlanguagemodeladaptation-201113072119/85/Neural-Mask-Generator-Learning-to-Generate-Adaptive-Word-Maskings-for-Language-Model-Adaptation-4-320.jpg)

![Motivation
Although several heuristic masking policies have been proposed, none
of them is clearly superior over others.
A myo ##car ##dial in ##farc ##tion occurs when blood flow ....Original:
A [MASK] [MASK] [MASK] in ##farc ##tion occurs when blood flow ...Whole-word:
Span: A myo ##car ##dial in ##farc [MASK] [MASK] [MASK] blood flow ...
A myo [MASK] ##dial [MASK] ##farc ##tion occurs when [MASK] flow ...Random:
In this work, we propose to generate the masks adaptively for the
given domain, by learning the optimal masking policy.
[Joshi et al. 20] SpanBERT: Improving Pre-training by Representing and Predicting Spans, TACL 2020.
[Sun et al. 19] Enhanced Representation through Knowledge Integration, arXiv 2019.](https://image.slidesharecdn.com/neuralmaskgeneratorlearningtogenerateadaptivewordmaskingsforlanguagemodeladaptation-201113072119/85/Neural-Mask-Generator-Learning-to-Generate-Adaptive-Word-Maskings-for-Language-Model-Adaptation-6-320.jpg)

![Problem Formulation
Masked Language Model
Unannotated
Text corpus
[MASK]
Masked
Text corpus
Language Model
Parameters [MASK]
Original
Context
Masked
Context](https://image.slidesharecdn.com/neuralmaskgeneratorlearningtogenerateadaptivewordmaskingsforlanguagemodeladaptation-201113072119/85/Neural-Mask-Generator-Learning-to-Generate-Adaptive-Word-Maskings-for-Language-Model-Adaptation-8-320.jpg)
![Problem Formulation
Masked Language Model
A myo [MASK] ##dial [MASK]
##farc ##tion occurs when
[MASK] flow ...
Masked Context
A myo ##car ##dial in ##farc
##tion occurs when blood flo
w ...
Original Context
𝑤! = A
𝑤" = myo
𝑤# = ##car
𝑤$ = ##dial
𝑤% = in
𝑤& = ##farc
𝑤' = ##tion
…
Words (Tokens)
𝑧( = $
1,
0,
𝑖𝑓 𝑖-𝑡ℎ word is masked
𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒](https://image.slidesharecdn.com/neuralmaskgeneratorlearningtogenerateadaptivewordmaskingsforlanguagemodeladaptation-201113072119/85/Neural-Mask-Generator-Learning-to-Generate-Adaptive-Word-Maskings-for-Language-Model-Adaptation-9-320.jpg)





![Problem Formulation
Reinforcement learning formulation
The probability of
masking T tokens
Transition
Probability
The cat is cute .
The [MASK] is cute .
The [MASK] is [MASK] .
t=1
t=2
t=3
Example (MDP)
The cat is cute .
The [MASK] is [MASK] .
Example (Approximation)](https://image.slidesharecdn.com/neuralmaskgeneratorlearningtogenerateadaptivewordmaskingsforlanguagemodeladaptation-201113072119/85/Neural-Mask-Generator-Learning-to-Generate-Adaptive-Word-Maskings-for-Language-Model-Adaptation-15-320.jpg)







![Experiments
• No Pre-training
• Random Masking (Devlin et al. 19)
• Whole-Random Masking (Devlin et al. 19)
• Span-Random Masking (Joshi et al. 20)
• Entity-Random Masking (Sun et al. 19)
• Punctuation-Random Masking
Baselines
[Joshi et al. 20] SpanBERT: Improving Pre-training by Representing and Predicting Spans, TACL 2020.
[Sun et al. 19] Enhanced Representation through Knowledge Integration, arXiv 2019.
[Devlin et al. 19] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL 2019](https://image.slidesharecdn.com/neuralmaskgeneratorlearningtogenerateadaptivewordmaskingsforlanguagemodeladaptation-201113072119/85/Neural-Mask-Generator-Learning-to-Generate-Adaptive-Word-Maskings-for-Language-Model-Adaptation-26-320.jpg)

![[Text Classification Results] [Ablation Results]
Results](https://image.slidesharecdn.com/neuralmaskgeneratorlearningtogenerateadaptivewordmaskingsforlanguagemodeladaptation-201113072119/85/Neural-Mask-Generator-Learning-to-Generate-Adaptive-Word-Maskings-for-Language-Model-Adaptation-28-320.jpg)
![Analysis
[Example from NewsQA]
[Top6 Part-Of-Speech Tag of Masked Words on NewsQA]](https://image.slidesharecdn.com/neuralmaskgeneratorlearningtogenerateadaptivewordmaskingsforlanguagemodeladaptation-201113072119/85/Neural-Mask-Generator-Learning-to-Generate-Adaptive-Word-Maskings-for-Language-Model-Adaptation-29-320.jpg)


Neural Mask Generator : Learning to Generate Adaptive Word Maskings for Language Model Adaptation
- 1. Neural Mask Generator: Learning to Generate Adaptive Word Maskings for Language Model Adaptation Minki Kang1*, Moonsu Han1*, and Sung Ju Hwang1,2 KAIST1, Daejeon, South Korea AITRICS2, Seoul, South Korea 1
- 2. Background The recent success of neural language model is based on the scheme of pre-train once, and fine-tune everywhere. [Devlin et al. 19] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL 2019
- 3. Background Recent Language Models (LM) are pre-trained on large and heterogeneous dataset. General Dataset (e.g. Wikipedia) Specific-Domain Dataset Further Pre-training [Beltagy et al. 19] SciBERT: A Pretrained Language Model for Scientific Text, EMNLP 2019. [Lee et al. 20] BioBERT: a pre-trained biomedical language representation model for biomedical text mining, Bioinformatics 2020. [Gururangan et al. 20] Don’t stop Pre-training: Adapt Language Models to Domains and Tasks, ACL 2020. Some works propose further pre-training for LM adaptation.
- 4. Background Masked Language Models (MLMs) objective has shown to be effective for language model pre-training. A myocardial infarction, also known as a [MASK] attack, occurs when blo od flow decreases. A myocardial infarction, also known as a heart attack, occurs when bl ood flow decreases. [Original] [Model Input] [Model Output] heart [Devlin et al. 19] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL 2019
- 5. Motivation Will it be effective to further train the pre-trained language model on a domain-specific corpus using randomly generated masks? A myocardial infarction, also known as a heart attack, occurs when bl ood flow decreases. Language Model A myocardial infarction, also known as a heart attack, occurs when bl ood flow decreases. TrivialImportant
- 6. Motivation Although several heuristic masking policies have been proposed, none of them is clearly superior over others. A myo ##car ##dial in ##farc ##tion occurs when blood flow ....Original: A [MASK] [MASK] [MASK] in ##farc ##tion occurs when blood flow ...Whole-word: Span: A myo ##car ##dial in ##farc [MASK] [MASK] [MASK] blood flow ... A myo [MASK] ##dial [MASK] ##farc ##tion occurs when [MASK] flow ...Random: In this work, we propose to generate the masks adaptively for the given domain, by learning the optimal masking policy. [Joshi et al. 20] SpanBERT: Improving Pre-training by Representing and Predicting Spans, TACL 2020. [Sun et al. 19] Enhanced Representation through Knowledge Integration, arXiv 2019.
- 7. Motivation Our objective is to find the task-dependent masking policy via a learnable mask generator.
- 8. Problem Formulation Masked Language Model Unannotated Text corpus [MASK] Masked Text corpus Language Model Parameters [MASK] Original Context Masked Context
- 9. Problem Formulation Masked Language Model A myo [MASK] ##dial [MASK] ##farc ##tion occurs when [MASK] flow ... Masked Context A myo ##car ##dial in ##farc ##tion occurs when blood flo w ... Original Context 𝑤! = A 𝑤" = myo 𝑤# = ##car 𝑤$ = ##dial 𝑤% = in 𝑤& = ##farc 𝑤' = ##tion … Words (Tokens) 𝑧( = $ 1, 0, 𝑖𝑓 𝑖-𝑡ℎ word is masked 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒
- 10. Problem Formulation Bi-level formulation: Masking {3, 5, 10} List of word indices to be masked Probability of each word being masked … ##car in 𝒊 = 𝟏 𝒊 = 𝑵 Arbitrary Function parameterized by 𝜆
- 11. Problem Formulation Bi-level formulation: Further Pre-Training (Inner Loop) Further Pre-trained Language Model parameterized by 𝜆
- 12. Problem Formulation Bi-level formulation: Fine-tuning on the task (Inner Loop) Downstream task Solver model Loss function of Supervised Learning Training Dataset
- 13. Problem Formulation Bi-level formulation: Outer-level objective (Outer Loop)
- 14. Problem Formulation Reinforcement learning formulation Probability of each word being masked … ##car in 𝒊 = 𝟏 𝒊 = 𝑵 A myo ##car ##dial in ##farc ##tion occurs when blood flo w ... Input Context 𝑅 = − = Accuracy on the test set. Policy Actions Reward
- 15. Problem Formulation Reinforcement learning formulation The probability of masking T tokens Transition Probability The cat is cute . The [MASK] is cute . The [MASK] is [MASK] . t=1 t=2 t=3 Example (MDP) The cat is cute . The [MASK] is [MASK] . Example (Approximation)
- 17. Neural Mask Generator Training objective 1. Advantageous Actor-Critic 2. Off-Policy learning with Prioritized Experience Replay 3. Importance Sampling
- 18. Neural Mask Generator Training objective Sampled Replays Entropy Regularization
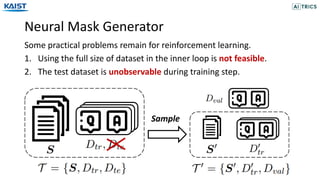
- 19. Neural Mask Generator Some practical problems remain for reinforcement learning. 1. Using the full size of dataset in the inner loop is not feasible. 2. The test dataset is unobservable during training step. Sample
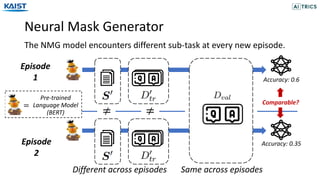
- 20. Neural Mask Generator The NMG model encounters different sub-task at every new episode. Episode 1 Episode 2 Same across episodesDifferent across episodes ≠ Comparable? Accuracy: 0.35 ≠ Pre-trained Language Model (BERT) = Accuracy: 0.6
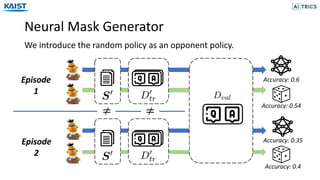
- 21. Neural Mask Generator We introduce the random policy as an opponent policy. Accuracy: 0.6 Accuracy: 0.35 Accuracy: 0.54 Accuracy: 0.4 Episode 1 Episode 2 ≠≠
- 22. Neural Mask Generator We add another neural policy to induce the Self-Play. Accuracy: 0.6 Accuracy: 0.54 Neural Policy (Player) + Neural Policy (Opponent) Accuracy: 0.62 Random Policy (Opponent) a = {𝟏, 5, 𝟕} a-. = {1, 5, 9} a! = {4, 5, 7} Positive Reward Negative Reward
- 23. Neural Mask Generator In each episode, the language model for each policy is initialized. Episode 2 Episode 1 Initialized Initialized “Omit other policies for brevity.”Further Pre-training Fine-tuning Evaluation
- 24. Neural Mask Generator Continual adaptation - Instead, load the LM from former episode. Episode 2 Episode 1 Initialized Load “Omit other policies for brevity.”Further Pre-training Fine-tuning Evaluation
- 25. Experiments 1) Question Answering • SQuAD v1.1 • emrQA • NewsQA 2) Text Classification • IMDb • ChemProt Datasets 1) Question Answering • BERT • DistilBERT 2) Text Classification • BERT Language Models
- 26. Experiments • No Pre-training • Random Masking (Devlin et al. 19) • Whole-Random Masking (Devlin et al. 19) • Span-Random Masking (Joshi et al. 20) • Entity-Random Masking (Sun et al. 19) • Punctuation-Random Masking Baselines [Joshi et al. 20] SpanBERT: Improving Pre-training by Representing and Predicting Spans, TACL 2020. [Sun et al. 19] Enhanced Representation through Knowledge Integration, arXiv 2019. [Devlin et al. 19] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL 2019
- 27. Results
- 28. [Text Classification Results] [Ablation Results] Results
- 29. Analysis [Example from NewsQA] [Top6 Part-Of-Speech Tag of Masked Words on NewsQA]
- 30. Conclusion • We proposed Neural Mask Generator (NMG), which learns the adaptive masking policy to adapt the language model to a new domain. • We formulate the problem of learning the optimal masking policy as a bi-level meta-learning framework, with reinforcement learning for optimization. • Experimental results on multiple NLU tasks show that NMG generates adaptive word masking for a given domain, which yields better or at least comparable performance over the best-working heuristic masking policy. Code is available at https://github.com/Nardien/NMG
- 31. Thank you