Neural networks with python
2 likes1,691 views

This document discusses neural networks in Python using Theano and Lasagne libraries. It begins with an introduction to machine learning concepts like supervised learning and neural network training as minimizing a cost function. It then demonstrates how to build and train a simple neural network classifier for MNIST digits using Theano. Finally, it shows how to build a deeper multi-layer network for MNIST using Lasagne, obtaining better results through multiple layers and dropout regularization.






![8
8
To create a classifier we want the output y to look like a set of
probabilities. For example:
x1
x2
x3
xN
…
Σ
Σ
Σ
Y1 = 2
Y1 = 0.6
Y3 = 0.1
…
Is it a cat?
Is it a dog?
Is it a fish?
We have a set of scores y called ”logits” but in this version they
cannot be used as probabilities because:
• The are not values in the range [0,1]
• They do not add up to 1
Example](https://image.slidesharecdn.com/neuralnetworkswithpython-160419073810/85/Neural-networks-with-python-8-320.jpg)
![9
9
To convert logits into probabilities we can use the Softmax function:
S(𝑦𝑖) =
&'(
∑ &'
This guarantees all values are between [0,1] and they add up to 1.
At this point we can compare the result of a prediction with the expected
value coming from the label.
This is a cat so the ideal result should be [1,0,0]
x1
x2
x3
xN
…
Σ
Σ
Σ
Y1
Y2
Y3
softmax
0.72
0.18
0.10
S(y)
1
0
0
Label
(one-hot)
≠
Ideally S(y) == Label
Training means making S(y) as close to Label as possible.
Softmax and cross-entropy](https://image.slidesharecdn.com/neuralnetworkswithpython-160419073810/85/Neural-networks-with-python-9-320.jpg)




![14
14
from theano import function
import theano.tensor as T
a = T.dscalar()
b = T.dscalar()
c = a + b
f = theano.function([a,b], c)
assert 4.0 == f(1.5, 2.5)
A simple program to build a symbolic expression and run a computation
Note: Theano builds a symbolic representation of the math behind the function
so the expression can be manipulated or rearranged dynamically before the
actual computation happens.
Same happens for matrixes
x = T.dmatrix('x') # you can give a symbolic name to the variable
y = T.dmatrix('y')
z = x + y
f = function([x, y], z)
assert numpy.all(f([[1, 2],[3, 4]], [[10,20],[30,40]]) ==
numpy.array([[11.,22.],[33.,44.]]))
Theano examples/1](https://image.slidesharecdn.com/neuralnetworkswithpython-160419073810/85/Neural-networks-with-python-14-320.jpg)



![18
18
import theano
import theano.tensor as T
class NN1Layer(object):
def __init__(self, n_in, n_out, learning_rate=1.0):
# create two symbolic variables for our model
x = T.matrix('x') # matrix of [784, nsamples] input pixels
y = T.ivector('y') # 1D vector of [nsamples] output labels
# create the coefficient matrixes, pre-filled with zeros
self.W = theano.shared(value=numpy.zeros((n_in, n_out)))
self.b = theano.shared(value=numpy.zeros((n_out,)))
# expression of label probabilities
p_y_given_x = T.nnet.softmax(T.dot(x, self.W) + self.b)
# expression for the cost function
cost = -T.mean(T.log(p_y_given_x)[T.arange(y.shape[0]), y])
Example MNIST – The code/1](https://image.slidesharecdn.com/neuralnetworkswithpython-160419073810/85/Neural-networks-with-python-18-320.jpg)
![19
19
# gradients of the cost over the coefficients
grad_W = T.grad(cost=cost, wrt=self.W)
grad_b = T.grad(cost=cost, wrt=self.b)
updates = [(self.W, self.W - learning_rate * grad_W),
(self.b, self.b - learning_rate * grad_b)]
# the function for training
self.train_model = theano.function([x, y], cost,
updates=updates, allow_input_downcast=True)
# expression for prediction
y_pred = T.argmax(p_y_given_x, axis=1)
# the function for prediction
self.predict_model = theano.function([x], y_pred)
Example MNIST – The code/2](https://image.slidesharecdn.com/neuralnetworkswithpython-160419073810/85/Neural-networks-with-python-19-320.jpg)
![20
20
def train(self, data_x, data_y, val_x, val_y, n_epochs=1000):
for epoch in range(n_epochs):
avg_cost = self.train_model(data_x, data_y)
precision = 100*self.validate(val_x, val_y)
print("Epoch {}, cost={:.6f}, precision={:.2f}%”.format(
epoch, avg_cost, precision))
def predict(self, data_x):
return self.predict_model(data_x)
def validate(self, data_x, data_y):
# execute a prediction and check how many results are OK
pred_y = self.predict(data_x)
nr_good = 0
for i in range(len(data_y)):
if pred_y[i] == data_y[i]:
nr_good += 1
return 1.0*nr_good/len(data_y)
Example MNIST – The code/3](https://image.slidesharecdn.com/neuralnetworkswithpython-160419073810/85/Neural-networks-with-python-20-320.jpg)


![23
23
Example code with Lasagne
import lasagne
import lasagne.layers as LL
Import lasagne.nonlinearities as LNL
class MultiLayerPerceptron(object):
def __init__(self):
x = T.matrix('x')
y = T.ivector(’y')
network = self.build_mlp(x)
pred1 = network.get_output()
cost = lasagne.objectives.categorical_crossentropy(pred1, y).mean()
params = LL.get_all_params(network)
updates = lasagne.updates.nesterov_momentum(
cost, params, learning_rate=0.01, momentum=0.9)
self.train_model = theano.function([x, y], cost, updates=updates)
pred2 = network.get_output(deterministic=True)
self.prediction_model = theano.function([x, y], pred2)
def build_mlp(self, x):
l1 = LL.InputLayer(shape=(None, 784), input_var=x)
l2 = LL.DropoutLayer(l1, p=0.2)
l3 = LL.DenseLayer(l2, num_units=800, nonlinearity=LNL.rectify)
l4 = LL.DropoutLayer(l3, p=0.5)
l5 = LL.DenseLayer(l4, num_units=800, nonlinearity=LNL.rectify)
l6 = LL.DropoutLayer(l5, p=0.5)
return LL.DenseLayer(l6, num_units=10, nonlinearity=LNL.softmax)](https://image.slidesharecdn.com/neuralnetworkswithpython-160419073810/85/Neural-networks-with-python-23-320.jpg)



Neural networks with python
- 1. NEURAL NETWORKS IN PYTHON With Theano and Lasagne Presented by Simone Piunno OTT Technology Director| Buongiorno SpA April 17, 2016
- 2. 2 2 About me OTT Technology Director Buongiorno SpA NTT Docomo Group Using Big Data and Machine Learning for fraud detection and adv optimization Founder of ”Italy Big Data and Machine Learning” AKA Data Lovers community Technology enthusiast
- 3. 3 3 • What is Machine Learning • Simplest Neural Network: the Logistic Classifier • Training is a Minimization Problem • Is Python good for this kind of problem? • Theano • MNIST example • Deep Learning example with Lasagne Agenda
- 4. 4 4 Machine Learning is a family of algorithms that learn from examples and can improve accuracy through experience. ML addresses three main problem classes: • Supervised Learning using train set to build a prediction machine • Unsupervised Learning inferring patterns/features from raw data • Reinforcement Learning dynamically learning through trial & error Our focus Machine Learning
- 5. 5 5 Supervised classification is split in two phases: training and prediction Training means processing a set of labeled examples and producing a model After training, the model is used to predict the correct label for unlabeled inputs, or in – other words – to classify new input, previously unseen Feature extractor machine learning algorithm label 4 7 2 1 classifier model example features Inputpairs Feature extractor machine learning algoritm 4 7 2 1 example label classifier model features Supervised classification
- 6. 6 6 w1x1 + w2x2 + w3x3 + … + wNxN + b = y Σ y x1 x2 x3 xN … A brain neuron is a device receiving electrical inputs from many input connectors and combining them in one electrical output For our needs we model a neuron as just a weighted sum of numerical inputs with a bias How neurons work
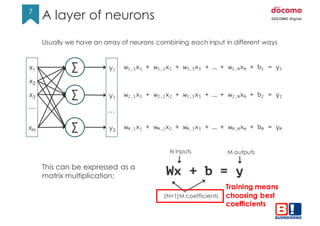
- 7. 7 7 Usually we have an array of neurons combining each input in different ways This can be expressed as a matrix multiplication: Wx + b = y N inputs M outputs (N+1)M coefficients Training means choosing best coefficients x1 x2 x3 xN … Σ Σ Σ y1 y1 y3 w1,1x1 + w1,2x2 + w3,3x3 + … + w1,NxN + b1 = y1 w2,1x1 + w2,2x2 + w2,3x3 + … + w2,NxN + b2 = y2 … wM,1x1 + wM,2x2 + wM,3x3 + … + wM,NxN + bM = yM A layer of neurons
- 8. 8 8 To create a classifier we want the output y to look like a set of probabilities. For example: x1 x2 x3 xN … Σ Σ Σ Y1 = 2 Y1 = 0.6 Y3 = 0.1 … Is it a cat? Is it a dog? Is it a fish? We have a set of scores y called ”logits” but in this version they cannot be used as probabilities because: • The are not values in the range [0,1] • They do not add up to 1 Example
- 9. 9 9 To convert logits into probabilities we can use the Softmax function: S(𝑦𝑖) = &'( ∑ &' This guarantees all values are between [0,1] and they add up to 1. At this point we can compare the result of a prediction with the expected value coming from the label. This is a cat so the ideal result should be [1,0,0] x1 x2 x3 xN … Σ Σ Σ Y1 Y2 Y3 softmax 0.72 0.18 0.10 S(y) 1 0 0 Label (one-hot) ≠ Ideally S(y) == Label Training means making S(y) as close to Label as possible. Softmax and cross-entropy
- 10. 10 10 Recap: • Prediction works best when discrepancyis minimum • Discrepancy is minimum when Cross-entropy D(S(Wx+b,L)) is minimum • We have to find those values of (W, b) that make D(S(Wx+b),L) minimum! We transformed a training problem into a minimization problem. A common measure of the discrepancy between the two values is the ”Cross-entropy” D(S(y), L) = − ∑ 𝐿0 log(𝑆 𝑦0 )0 Actually we want to do this over all examples in the training set, as an average: Davg(S(y), L) = − 5 6 ∑ ∑ 𝐿0 log(𝑆 𝑦0 )0 Training = cross-entropy minimization
- 11. 11 11 Function minimization is a well known math problem. The simplest solution is called Gradient Descent . It starts in at random coordinates and requires iteratively computing the gradient moving to a new point in the opposite direction. Gradient Descent grad(W) = 𝜕𝐷𝑎𝑣 𝑔 𝜕𝑊 grad(b) = 𝜕𝐷𝑎𝑣 𝑔 𝜕𝑏
- 12. 12 12 Training a neural network is a computation intensive task. Even simple neural networks might involve matrix multiplications with millions of values and application of symbolic math to find function derivatives. Thanks to the gaming market modern GPUs are very fast at matrix multiplication but only hard core C libraries are available to code GPUs. Traditionally all of this requires compiled languages like C but luckily enough Python can easily bind in C extensions and bridge the gap! Currently there are two main libraries for doing this kind of things in Python: • Theano • Google Tensorflow Is Python good for this?
- 13. 13 13 Theano is a Python library that allows you to define,optimize, and efficientlyevaluate mathematical expressions involving multi-dimensional arrays. Theano features: • Automatically and dynamically compiling math expressions to C • Tight integration with NumPy • Tansparent use of a GPU compute up to 140x faster than on a CPU • Efficientsymbolic differentiation that can compute derivatives for functions of one or many inputs. • Speed and stability optimizations to avoid precision errors Theano was developed at University of Montreal and has been powering large-scale computationally intensive scientificresearch since 2007 Theano
- 14. 14 14 from theano import function import theano.tensor as T a = T.dscalar() b = T.dscalar() c = a + b f = theano.function([a,b], c) assert 4.0 == f(1.5, 2.5) A simple program to build a symbolic expression and run a computation Note: Theano builds a symbolic representation of the math behind the function so the expression can be manipulated or rearranged dynamically before the actual computation happens. Same happens for matrixes x = T.dmatrix('x') # you can give a symbolic name to the variable y = T.dmatrix('y') z = x + y f = function([x, y], z) assert numpy.all(f([[1, 2],[3, 4]], [[10,20],[30,40]]) == numpy.array([[11.,22.],[33.,44.]])) Theano examples/1
- 15. 15 15 >>> a = T.dscalar() >>> b = a**2 >>> db = T.grad(b, a) >>> db.eval({a: 10}) array(20.0) Since Theano keeps a symbolic representation of expressions it can easily build and compute derivative functions. With Theano switching to GPU computation is completely transparent, you just set an environment variable and your are done $ export THEANO_FLAGS=device=gpu $ python your_script.py Theano examples/2
- 16. 16 16 As an example we will create a neural network to recognize numbers. We will use a database of images of numbers called MNIST. In MNIST all images are monochrome squares 28x28 pixels. Example: MNIST
- 17. 17 17 We will use a network with 28x28 = 784 inputs and 10 outputs W is a matrix of 784x10 = 7480 coefficients b is a vector of 10 coefficients So we have to compute 7490 derivatives at every iteration For a dataset of 50000 image examples it takes 374M derivatives per round! Example: MNIST
- 18. 18 18 import theano import theano.tensor as T class NN1Layer(object): def __init__(self, n_in, n_out, learning_rate=1.0): # create two symbolic variables for our model x = T.matrix('x') # matrix of [784, nsamples] input pixels y = T.ivector('y') # 1D vector of [nsamples] output labels # create the coefficient matrixes, pre-filled with zeros self.W = theano.shared(value=numpy.zeros((n_in, n_out))) self.b = theano.shared(value=numpy.zeros((n_out,))) # expression of label probabilities p_y_given_x = T.nnet.softmax(T.dot(x, self.W) + self.b) # expression for the cost function cost = -T.mean(T.log(p_y_given_x)[T.arange(y.shape[0]), y]) Example MNIST – The code/1
- 19. 19 19 # gradients of the cost over the coefficients grad_W = T.grad(cost=cost, wrt=self.W) grad_b = T.grad(cost=cost, wrt=self.b) updates = [(self.W, self.W - learning_rate * grad_W), (self.b, self.b - learning_rate * grad_b)] # the function for training self.train_model = theano.function([x, y], cost, updates=updates, allow_input_downcast=True) # expression for prediction y_pred = T.argmax(p_y_given_x, axis=1) # the function for prediction self.predict_model = theano.function([x], y_pred) Example MNIST – The code/2
- 20. 20 20 def train(self, data_x, data_y, val_x, val_y, n_epochs=1000): for epoch in range(n_epochs): avg_cost = self.train_model(data_x, data_y) precision = 100*self.validate(val_x, val_y) print("Epoch {}, cost={:.6f}, precision={:.2f}%”.format( epoch, avg_cost, precision)) def predict(self, data_x): return self.predict_model(data_x) def validate(self, data_x, data_y): # execute a prediction and check how many results are OK pred_y = self.predict(data_x) nr_good = 0 for i in range(len(data_y)): if pred_y[i] == data_y[i]: nr_good += 1 return 1.0*nr_good/len(data_y) Example MNIST – The code/3
- 21. 21 21 $ time python nntut.py Loaded 50000 training samples Loaded 10000 test samples Training on 5000 samples Epoch 0, cost=2.302585, precision=73.99% Epoch 1, cost=1.469972, precision=67.82% Epoch 2, cost=1.265133, precision=71.25% Epoch 3, cost=1.275743, precision=67.29% Epoch 4, cost=1.168924, precision=66.39% ... ... Epoch 999, cost=0.138175, precision=90.92% Prediction accuracy = 89.92% real 1m28.135s user 2m27.099s sys 0m26.667s Example MNIST – Execution
- 22. 22 22 In order to achieve better results we need to chain several layers. For example: Deep Learning This becomes more difficult: • Need ready-to–use building blocks • Need a way to automatically propagate gradient back in the chain (backpropagation) For this we can use the Lasagne library! Softmax Non-linearity Non-linearity 800 x 10 W4,b4 784 x 800 W1,b1 800 x 800 W2,b2 800 x 800 W3,b3 Non-linearity x y
- 23. 23 23 Example code with Lasagne import lasagne import lasagne.layers as LL Import lasagne.nonlinearities as LNL class MultiLayerPerceptron(object): def __init__(self): x = T.matrix('x') y = T.ivector(’y') network = self.build_mlp(x) pred1 = network.get_output() cost = lasagne.objectives.categorical_crossentropy(pred1, y).mean() params = LL.get_all_params(network) updates = lasagne.updates.nesterov_momentum( cost, params, learning_rate=0.01, momentum=0.9) self.train_model = theano.function([x, y], cost, updates=updates) pred2 = network.get_output(deterministic=True) self.prediction_model = theano.function([x, y], pred2) def build_mlp(self, x): l1 = LL.InputLayer(shape=(None, 784), input_var=x) l2 = LL.DropoutLayer(l1, p=0.2) l3 = LL.DenseLayer(l2, num_units=800, nonlinearity=LNL.rectify) l4 = LL.DropoutLayer(l3, p=0.5) l5 = LL.DenseLayer(l4, num_units=800, nonlinearity=LNL.rectify) l6 = LL.DropoutLayer(l5, p=0.5) return LL.DenseLayer(l6, num_units=10, nonlinearity=LNL.softmax)
- 24. 24 24 Example code with Lasagne $ python lasagne_test.py Loaded 50000 training samples Loaded 10000 test samples Epoch 1 took 12.5s - training loss=1.236773, validation accuracy=88.63 % Epoch 2 took 12.3s - training loss=0.567314, validation accuracy=91.00 % Epoch 3 took 12.4s - training loss=0.464701, validation accuracy=92.35 % Epoch 4 took 12.3s - training loss=0.412483, validation accuracy=93.01 % Epoch 5 took 12.3s - training loss=0.376988, validation accuracy=93.56 % ... ... Epoch 491 took 13.9s - training loss=0.016746, validation accuracy=98.75 % ... ...
- 25. 25 25 References Italy Big Data & Machine Learning Meetup http://www.meetup.com/Italy-Big-Data-Machine-Learning-Meetup/ A tutorial on Deep Learning http://deeplearning.net/tutorial/ MNIST database http://yann.lecun.com/exdb/mnist/ Theano library http://deeplearning.net/software/theano/ Lasagne library https://lasagne.readthedocs.org/en/latest/
- 26. THANK YOU Presented by Simone Piunno OTT Technology Director| Buongiorno SpA [email protected]