NoLambda: Combining Streaming, Ad-Hoc, Machine Learning and Batch Analysis
16 likes4,167 views

The document discusses Tuplejump's integration of streaming, ad-hoc, machine learning, and batch analytics through their technologies, particularly in the context of using Apache Spark and Cassandra. It highlights the challenges of building scalable, fault-tolerant systems capable of handling massive data and emphasizes the advantages of their Filodb database for optimizing analytics and storage solutions. Key use cases include real-time processing and the benefits of a unified streaming architecture over traditional Lambda architectures, addressing issues of performance, complexity, and data consistency.


































![Kafka Streams
valbuilder=newKStreamBuilder()
valstream:KStream[K,V]=builder.stream(des,des,"raw.data.topic")
.flatMapValues(value->Arrays.asList(value.toLowerCase.split("")
.map((k,v)->newKeyValue(k,v))
.countByKey(ser,ser,des,des,"kTable")
.toStream()
stream.to("results.topic",...)
valstreams=newKafkaStreams(builder,props)
streams.start()
https://github.com/con uentinc/demos](https://image.slidesharecdn.com/stratasjstreamingadhocmachinelearninganalysis-160331160231/85/NoLambda-Combining-Streaming-Ad-Hoc-Machine-Learning-and-Batch-Analysis-35-320.jpg)


.where("wsid=?ANDyear=?ANDmonth=?",e.wsid,e.year,e.month)
.collectAsync()
.map(MonthlyTemperature(_,e.wsid,e.year,e.month))pipeTorequester
}](https://image.slidesharecdn.com/stratasjstreamingadhocmachinelearninganalysis-160331160231/85/NoLambda-Combining-Streaming-Ad-Hoc-Machine-Learning-and-Batch-Analysis-37-320.jpg)

.map(LabeledPoint.parse)
valtrainingStream=KafkaUtils.createDirectStream[_,_,_,_](..)
.map(transformFunc)
.map(LabeledPoint.parse)
trainingStream.saveToCassandra("ml_training_keyspace","raw_training_data")
valmodel=newStreamingLinearRegressionWithSGD()
.setInitialWeights(Vectors.dense(weights))
.trainOn(trainingStream)
model
.predictOnValues(testData.map(lp=>(lp.label,lp.features)))
.saveToCassandra("ml_predictions_keyspace","predictions")](https://image.slidesharecdn.com/stratasjstreamingadhocmachinelearninganalysis-160331160231/85/NoLambda-Combining-Streaming-Ad-Hoc-Machine-Learning-and-Batch-Analysis-38-320.jpg)






















.map(transformFunc)
.map(LabeledPoint.parse)
dataStream.foreachRDD(_.toDF.write.format("filodb.spark")
.option("dataset","training").save())
if(trainNow){
varmodel=newStreamingLinearRegressionWithSGD()
.setInitialWeights(Vectors.dense(weights))
.trainOn(dataStream.join(historicalEvents))
}
model.predictOnValues(dataStream.map(lp=>(lp.label,lp.features)))
.insertIntoFilo("predictions")](https://image.slidesharecdn.com/stratasjstreamingadhocmachinelearninganalysis-160331160231/85/NoLambda-Combining-Streaming-Ad-Hoc-Machine-Learning-and-Batch-Analysis-61-320.jpg)



















![Spark Streaming -> FiloDB
valratingsStream=KafkaUtils.createDirectStream[String,String,StringDecoder,Strin
ratingsStream.foreachRDD{
(message:RDD[(String,String)],batchTime:Time)=>{
valdf=message.map(_._2.split(",")).map(rating=>Rating(rating(0).trim.toInt,r
toDF("fromuserid","touserid","rating")
//addthebatchtimetotheDataFrame
valdfWithBatchTime=df.withColumn("batch_time",org.apache.spark.sql.functions.l
//savetheDataFrametoFiloDB
dfWithBatchTime.write.format("filodb.spark")
.option("dataset","ratings")
.save()
}
}
One-line change to write to FiloDB vs Cassandra](https://image.slidesharecdn.com/stratasjstreamingadhocmachinelearninganalysis-160331160231/85/NoLambda-Combining-Streaming-Ad-Hoc-Machine-Learning-and-Batch-Analysis-81-320.jpg)









NoLambda: Combining Streaming, Ad-Hoc, Machine Learning and Batch Analysis
- 1. NoLambda: Combining Streaming, Ad-Hoc, Machine Learning, and Batch Analytics andEvan Chan Helena Edelson March 2016
- 2. Evan Chan Distinguished Engineer, User and contributor to Spark since 0.9, Cassandra since 0.6 Co-creator and maintainer of Tuplejump @evanfchan http://velvia.github.io Spark Job Server
- 3. Helena Edelson |@helenaedelson github.com/helena VP of Product Engineering, Cloud Engineer, Big Data, Event-Driven systems Committer: Kafka Connect Cassandra, Spark Cassandra Connector Contributor: Akka, Spring Integration Speaker: Kafka Summit, Spark Summit, Strata, QCon, Scala Days, Scala World, Philly ETE Tuplejump
- 4. Tuplejump is a big data technology leader providing solutions and development partnership. Tuplejump
- 5. Open Source: on GitHubTuplejump - Distributed Spark + Cassandra analytics database - Kafka-Cassandra Source and Sink - The rst Spark Cassandra integration - Lucene indexer for Cassandra - HDFS for Cassandra FiloDB Kafka Connect Cassandra Calliope Stargate SnackFS
- 6. Tuplejump Consulting & Development
- 8. Topics Modern streaming and batch/ad-hoc architectures Pitfalls and Simpli cation Precise and scalable streaming ingestion FiloDB and fast analytics with competitive storage cost Machine learning with Spark, Cassandra, and FiloDB
- 9. Delivering Meaning Derived From Many data streams Disparate sources and schemas Originating from many locations
- 10. The Problem Domain Build scalable, adaptable, self-healing, distributed data processing systems for 24 / 7 Uptime Auto scale out Complex analytics and learning tasks Aggregate global data Ops for global, multi-dc clustered data ows Decoupled services Idempotent & Acceptable Consistency No data loss
- 11. Factors & Constraints in Architecture Corner cases, Industry use cases Legal constraints - user data crossing borders % Writes on ingestion, % Reads How much in memory? Counters? Geo-locational? JDK version for cloud deployments Dimensions of data in queries What needs real time feedback loops The list goes on...
- 12. Need Self-Healing Systems Massive event spikes & bursty traf c Fast producers / slow consumers Network partitioning & out of sync systems DC down Not DDOS'ing ourselves from fast streams No data loss when auto-scaling down Monitor Everything Everything fails, all the time
- 13. Use Case I need fast access to historical data on the y for predictive modeling with real time data from the stream
- 14. Only, It's Not A Stream It's A Flood Trillions of event writes per day Billions of event reads per day Massive events per second at peak Petabytes of total streaming data
- 15. Not All Streams Are Created The Same Daily, Hourly, Frequency, Event Spikes at Peak, Overall Volume Sub-second, low latency stream processing Higher latency stream processing Scheduled or on request batch processing
- 16. Real Time Just means Event Driven or processing events as they arrive Doesn't automatically equal sub-second latency requirements Event Time When an event is created, e.g. on sensor Events should be uniquely timestamped on ingestion for tracking, metrics and replay
- 17. Based on the schema of data in a given stream Some can aggregate with sliding windows (T1...Tn,Tn+1...) using window length + slide interval: stream.reduceByKeyAndWindow((a:Int,b:Int)=>(a+b),Seconds(30),Seconds(10)) Some must aggregate by buckets /Event_Type/YYYY/MM/DD/HH/MM/... CREATETABLEtimeseries.raw_data_fu( sensor_idtext,yearint,monthint,dayint,hourint,... PRIMARYKEY((sensor_id),year,month,day,hour) )WITHCLUSTERINGORDERBY(yearDESC,monthDESC,dayDESC,hourDESC);
- 18. Stream Processing Kafka - Foundation to streaming architecture Samza - Just streaming Gearpump - Real-time big data streaming Analytics Stream Processing Storm - Real-time Analytics, ML, needs Trident to stream Flink - Real-time Analytics, ML, Graph Spark Streaming - Micro-batch Analytics, ML, Graph
- 19. Legacy Infrastructure Highly-invested-in existing architecture around Hadoop Existing analytics logic for scheduled MR jobs
- 20. Lambda Architecture A data-processing architecture designed to handle massive quantities of data by taking advantage of both batch and stream processing methods.
- 22. λ The Good Immutability - retaining master data With timestamped events Appended versus overwritten events Attempt to beat CAP Pre-computed views for further processing faster ad-hoc querying
- 23. λ The Bad Two Analytics systems to support Operational complexity By the time a scheduled job is run 90% of the data is stale Many moving parts: KV store, real time platform, batch technologies Running similar code and reconciling queries in dual systems Analytics logic changes on dual systems
- 24. λ The Overly Complicated Immutable sequence of records is ingested and fed into a batch processing system and a stream processing system in parallel Ultimately Very High TCO And...
- 26. Are Batch and Streaming Systems Fundamentally Different? Both accumulate events from *T1...Tn, Tn+1...Tn+x,...* Or bucketed by Year-Month-Day-Hour? Streaming frameworks have schedulers
- 27. A Unified Streaming Architecture Everything On The Streaming Platform Scala / Spark Streaming Mesos Akka Cassandra Kafka
- 29. High Throughput Distributed Messaging High Scalability - billions of events per day Durability - no data loss Immutability Support Massive Number of Consumers Very ef cient and low latency Decouples Data Pipelines Automatic recovery from broker failures
- 30. Stream Processing Simplified Kafka Streams In master, coming in v0.10 Removes the need to run another framework like Storm alongside Kafka Removes the need for separate infrastructures Common stream operations, e.g. join, lter, map, etc. Windowing Proper time modeling, e.g. event time vs. processing time Local state management with persistence and replication Schema and Avro support
- 31. Spark Streaming Iterative ML, Interactive Querying, Graph, DataFrames One runtime for streaming and batch processing Join streaming and static data sets No code duplication Easy Kafka stream integration Easy to reconcile queries against multiple sources Easy integration of KV durable storage
- 32. Apache Cassandra Horizontally scalable Multi-Region / Multi-Datacenter Always On - Survive regional outages Extremely fast writes: - perfect for ingestion of real time / machine data Very exible data modelling (lists, sets, custom data types) Easy to operate Best of breed storage technology, huge community BUT: Simple queries only OLTP-oriented/center
- 33. High performance concurrency framework for Scala and Java Fault Tolerance Asynchronous messaging and data processing Parallelization Location Transparency Local / Remote Routing Akka: Cluster / Persistence / Streams
- 34. Enables Streaming and Batch In One System Streaming ML and Analytics for Predictions In The Stream
- 36. Spark Streaming Kafka Immutable Raw Data From Kafka Stream Replaying data streams: for fault tolerance, logic changes.. classKafkaStreamingActor(ssc:StreamingContext)extendsMyAggregationActor{ valstream=KafkaUtils.createDirectStream(...) .map(RawWeatherData(_)) stream .foreachRDD(_.toDF.write.format("filodb.spark") .option("dataset","rawdata").save()) /*Pre-Aggregatedatainthestreamforfastqueryingandaggregationlater.*/ stream.map(hour=> (hour.wsid,hour.year,hour.month,hour.day,hour.oneHourPrecip) ).saveToCassandra(timeseriesKeyspace,dailyPrecipTable) }
- 37. Reading Data From Cassandra On Request, Further Aggregation Compute isolation in Akka Actor classTemperatureActor(sc:SparkContext)extendsAggregationActor{ importakka.pattern.pipe defreceive:Actor.Receive={ casee:GetMonthlyHiLowTemperature=>highLow(e,sender) } defhighLow(e:GetMonthlyHiLowTemperature,requester:ActorRef):Unit= sc.cassandraTable[DailyTemperature](timeseriesKeyspace,dailyTempAggregTable) .where("wsid=?ANDyear=?ANDmonth=?",e.wsid,e.year,e.month) .collectAsync() .map(MonthlyTemperature(_,e.wsid,e.year,e.month))pipeTorequester }
- 38. Spark Streaming, MLLib Kafka, Cassandra valssc=newStreamingContext(sparkConf,Seconds(5) ) valtestData=ssc.cassandraTable[String](keyspace,table) .map(LabeledPoint.parse) valtrainingStream=KafkaUtils.createDirectStream[_,_,_,_](..) .map(transformFunc) .map(LabeledPoint.parse) trainingStream.saveToCassandra("ml_training_keyspace","raw_training_data") valmodel=newStreamingLinearRegressionWithSGD() .setInitialWeights(Vectors.dense(weights)) .trainOn(trainingStream) model .predictOnValues(testData.map(lp=>(lp.label,lp.features))) .saveToCassandra("ml_predictions_keyspace","predictions")
- 39. What's Missing? One Pipeline For Fast + Big Data
- 40. Using Cassandra for Batch Analytics / Event Storage / ML? Storage ef ciency and scan speeds for reading large volumes of data (for complex analytics, ML) become important concerns Regular Cassandra CQL tables are not very good at either storage ef ciency or scan speeds A different, analytics-optimized solution is needed...
- 41. All hard work leads to pro t, but mere talk leads to poverty. - Proverbs 14:23
- 42. Introducing FiloDB A distributed, versioned, columnar analytics database. Built for Streaming. github.com/tuplejump/FiloDB
- 43. Fast Analytics Storage Scan speeds competitive with Apache Parquet Up to 200x faster scan speeds than with Cassandra 2.x Flexible ltering along two dimensions Much more ef cient and exible partition key ltering Ef cient columnar storage, up to 40x more ef cient than Cassandra 2.x
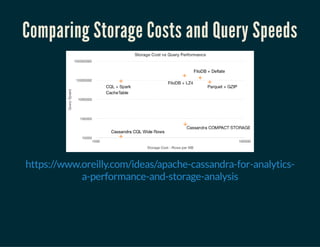
- 44. Comparing Storage Costs and Query Speeds https://www.oreilly.com/ideas/apache-cassandra-for-analytics- a-performance-and-storage-analysis
- 45. Robust Distributed Storage Apache Cassandra as the rock-solid storage engine. Scale out with no SPOF. Cross-datacenter replication. Proven storage and database technology.
- 46. Cassandra-Like Data Model Column A Column B Partition key 1 Segment 1 Segment 2 Segment 1 Segment 2 Partition key 2 Segment 1 Segment 2 Segment 1 Segment 2 partition keys - distributes data around a cluster, and allows for ne grained and exible ltering segment keys - do range scans within a partition, e.g. by time slice primary key based ingestion and updates
- 47. Flexible Filtering Unlike Cassandra, FiloDB offers very exible and ef cient ltering on partition keys. Partial key matches, fast IN queries on any part of the partition key. No need to write multiple tables to work around answering different queries.
- 48. Spark SQL Queries! CREATETABLEgdeltUSINGfilodb.sparkOPTIONS(dataset"gdelt"); SELECTActor1Name,Actor2Name,AvgToneFROMgdeltORDERBYAvgToneDESCLIMIT15 INSERTINTOgdeltSELECT*FROMNewMonthData; Read to and write from Spark Dataframes Append/merge to FiloDB table from Spark Streaming Use Tableau or any other JDBC tool
- 49. What's in the name? Rich sweet layers of distributed, versioned database goodness
- 50. SNACK (SMACK) stack for all your Analytics Regular Cassandra tables for highly concurrent, aggregate / key-value lookups (dashboards) FiloDB + C* + Spark for ef cient long term event storage Ad hoc / SQL / BI Data source for MLLib / building models Data storage for classi ed / predicted / scored data
- 52. Being Productionized as we speak... One enterprise with many TB of nancial and reporting data is moving their data warehouse to FiloDB + Cassandra + Spark Another startup uses FiloDB as event storage, feeds the events into Spark MLlib, scores incoming data, then stores the results back in FiloDB for low-latency use cases From their CTO: “I see close to MemSQL / Vertica or even better” “More cost effective than Redshift”
- 53. FiloDB Use Cases Data Warehousing / BI < 10 second SLA, nontrivial reports, some concurrency need to store and query lots of data ef ciently Time series idempotent write API, simultaneous write and read workloads In-memory SQL web server 700 queries per second using in-memory column store
- 54. FiloDB vs HDFS/Parquet FiloDB Parquet Ingestion Idempotent primary-key based; appends and replaces; deletes coming File-based append API only Filtering Partition-key and segment- key ltering Mostly le-based Scan speeds Parquet-like Good for OLAP Storage cost Within 35% of Parquet
- 55. FiloDB vs HDFS/Parquet In practice, with good data modeling, FiloDB is a far better t for low-latency / concurrent BI / reporting / dashboard applications.
- 56. FiloDB vs Druid Different use cases: Druid is optimized mostly for OLAP cube / slice and dice analysis. Append only, keeps only aggregates, not a raw event store. FiloDB stores raw data - can be used to build ML models, visualize and analyze raw time series data, do complex event ow analysis - much more exible FiloDB can update/replace data FiloDB does not require data denormalization - can handle traditional BI star schemas with slowly changing dimension tables
- 57. Come check out the demo! Visit FiloDB at the Developer Showcase (Expo hall) today!
- 58. Machine Learning with Spark, Cassandra, and FiloDB
- 59. Building a static model of NYC Taxi Trips Predict time to get to destination based on pickup point, time of day, other vars Need to read all data (full table scan)
- 60. Dynamic models are better than static models Everything changes! Continuously re ne model based on recent streaming data + historical data + existing model
- 63. The FiloDB Advantage for ML Able to update dynamic models based on massive data ow/updates Integrate historical and recent events to build models More data -> better models! Can store scored raw data / predictions back in FiloDB for fast user queries
- 64. FiloDB - Roadmap Your input is appreciated! Productionization and automated stress testing Kafka input API / connector (without needing Spark) In-memory caching for signi cant query speedup True columnar querying and execution, using late materialization and vectorization techniques. GPU/SIMD. Projections. Often-repeated queries can be sped up signi cantly with projections.
- 66. EXTRA SLIDES
- 67. What are my storage needs? Non-persistent / in-memory: concurrent viewers Short term: latest trends Longer term: raw event and aggregate storage ML Models, predictions, scored data
- 68. Spark RDDs Immutable, cache in memory and/or on disk Spark Streaming: UpdateStateByKey IndexedRDD - can update bits of data Snapshotting for recovery
- 69. Using Cassandra for Short Term Storage 1020s 1010s 1000s Bus A Speed, GPS Bus B Bus C Primary key = (Bus UUID, timestamp) Easy queries: location and speed of single bus for a range of time Can also query most recent location + speed of all buses (slower)
- 70. Data Warehousing with FiloDB
- 71. Scenarios BI Reporting, concurrency + seconds latency Ad-hoc queries Needing to do JOINs with fact tables + dimension tables Slowly changing dim tables / hard to denormalize Need to work with legacy BI tools
- 72. Real-world DW Architecture Stack Ef cient columnar storage + ltering = low latency BI
- 73. Modeling Fact Tables for FiloDB Single partition queries are really fast and take up only one thread Given the following two partition key columns: entity_number, year_month WHERE entity_number = '0453' AND year_month = '2014 December' Exact match for partition key is pushed down as one partition Consider the partition key carefully
- 74. Cassandra often requires multiple tables What about the queries that do not translate to one partition? Cassandra has many restrictions on partition key ltering (as of 2.x). Table 1: partition key = (entity_number, year_month) Can push down: WHERE entity_number = NN AND year_month IN ('2014 Jan', '2014 Feb')as well as equals Table 2: partition key = (year_month, entity_number) Can push down: WHERE year_month = YYMM AND entity_number IN (123, 456)as well as equals IN clause must be the last column to be pushed down. Two tables are needed just for ef cient IN queries on either entity_number or year_month.
- 75. FiloDB Flexible Partition Filters = WIN With ONE table, FiloDB offers FAST, arbitrary partition key ltering. All of the below are pushed down: WHERE year_month IN ('2014 Jan', '2014 Feb') (all entities) WHERE entity_number = 146(all year months) Any combo of =, IN Space savings: 27 *2 = 54x
- 76. Multi-Table JOINs with just Cassandra
- 77. Sub-second Multi-Table JOINs with FiloDB
- 78. Sub-second Multi-Table JOINs with FiloDB Four tables, all of them single-partition queries Two tables were switched from regular Cassandra tables to FiloDB tables. 40-60 columns each, ~60k items in partition. Scan times went down from 5-6 seconds to < 250ms For more details, please see this .Planet Cassandra blog post
- 79. Scalable Time-Series / Event Storage with FiloDB
- 80. Designed for Streaming New rows appended via Spark Streaming or Kafka Writes are idempotent - easy exactly once ingestion Converted to columnar chunks on ingest and stored in C* FiloDB keeps your data sorted as it is being ingested
- 81. Spark Streaming -> FiloDB valratingsStream=KafkaUtils.createDirectStream[String,String,StringDecoder,Strin ratingsStream.foreachRDD{ (message:RDD[(String,String)],batchTime:Time)=>{ valdf=message.map(_._2.split(",")).map(rating=>Rating(rating(0).trim.toInt,r toDF("fromuserid","touserid","rating") //addthebatchtimetotheDataFrame valdfWithBatchTime=df.withColumn("batch_time",org.apache.spark.sql.functions.l //savetheDataFrametoFiloDB dfWithBatchTime.write.format("filodb.spark") .option("dataset","ratings") .save() } } One-line change to write to FiloDB vs Cassandra
- 82. Modeling example: NYC Taxi Dataset The public contains telemetry (pickup, dropoff locations, times) info on millions of taxi rides in NYC. NYC Taxi Dataset Medallion pre x 1/1 - 1/6 1/7 - 1/12 AA records records AB records records Partition key - :stringPrefix medallion 2- hash multiple drivers trips into ~300 partitions Segment key - :timeslice pickup_datetime 6d Row key - hack_license, pickup_datetime Allows for easy ltering by individual drivers, and slicing by time.
- 83. DEMO TIME New York City Taxi Data Demo (Spark Notebook) To follow along: https://github.com/tuplejump/FiloDB/blob/master/doc/FiloDB_Taxi_G
- 84. Fast, Updatable In-Memory Columnar Storage Unlike RDDs and DataFrames, FiloDB can ingest new data, and still be fast Unlike RDDs, FiloDB can lter in multiple ways, no need for entire table scan FAIR scheduler + sub-second latencies => web speed queries
- 85. 700 Queries Per Second in Apache Spark! Even for datasets with 15 million rows! Using FiloDB's InMemoryColumnStore, single host / MBP, 5GB RAM SQL to DataFrame caching For more details, see .this blog post
- 86. FiloDB - How?
- 87. Multiple ways to Accelerate Queries Columnar projection - read fewer columns, saves I/O Partition key ltering - read less data Sort key / PK ltering - read from subset of keys Possible because FiloDB keeps data sorted Versioning - write to multiple versions, read from the one you choose
- 88. Cassandra CQL vs Columnar Layout Cassandra stores CQL tables row-major, each row spans multiple cells: PartitionKey 01: rst 01:last 01:age 02: rst 02:last 02:age Sales Bob Jones 34 Susan O'Connor 40 Engineering Dilbert P ? Dogbert Dog 1 Columnar layouts are column-major: PartitionKey rst last age Sales Bob, Susan Jones, O'Connor 34, 40 Engineering Dilbert, Dogbert P, Dog ?, 1
- 90. FiloDB Architecture ColumnStore API - currently Cassandra and InMemory, you can implement other backends - ElasticSearch? etc.