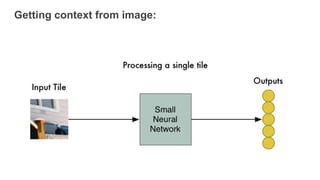
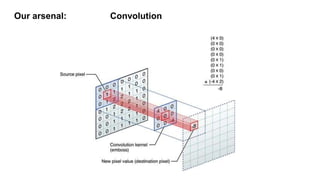
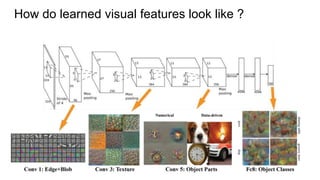
Semantic image segmentation uses word embeddings to provide context from images. Convolutional neural networks are used to extract visual features from images at different levels, from low level to higher semantic levels. Models like SegNet and Pyramid Pooling are used for segmentation. Word embeddings represent words as vectors in a continuous concept space, where cosine distance reflects semantic similarity. Image classes are mapped to word embeddings to provide semantic context during training, with the loss measuring cosine distance between predicted and true word vectors for each image region. This allows vocabulary-free semantic segmentation based on conceptual relationships between words and image regions.