Omid: scalable and highly available transaction processing for Apache Phoenix
Download as PPTX, PDF2 likes882 views

The document discusses Omid, a scalable and highly available transaction processing system integrated with Apache Phoenix, which transforms SQL queries into native HBase API calls. It outlines Phoenix's architecture, its transaction requirements, and the development of Omid since its inception at Yahoo Research. Omid offers features like snapshot isolation, secondary indexes, and enhances performance to support high transaction throughput for online transaction processing (OLTP) on Hadoop.









![Transaction requirements in Phoenix
10
Secondary index
Atomic update
(k1, [v1,v2,v3])
Table Index
(v1, k1)
Write (k1, ]v1,v2,v3])](https://image.slidesharecdn.com/omidscalableandhighlyavailabletransactionprocessing-180428011422/85/Omid-scalable-and-highly-available-transaction-processing-for-Apache-Phoenix-10-320.jpg)

























Omid: scalable and highly available transaction processing for Apache Phoenix
- 1. Omid: Scalable and highly available transaction processing for Apache Phoenix Ohad Shacham Yahoo Research Edward Bortnikov Yahoo Research James Taylor Salesforce RESEARCH
- 2. Agenda 2 Apache Phoenix Features, Scalability, and Performance Omid Phoenix-on-Omid Low-Latency Omid
- 3. What is Apache Phoenix? 3 A relational database layer for Apache HBase Transforms SQL queries into native HBase API calls Standard SQL interface with JDBC API’s to increase developer productivity Leveraging HBase Horizontal Scalability Pushes as much work as possible into the cluster
- 4. What is Apache Phoenix? 4 Project started by Salesforce in 2014. Currently a top level project at the Apache Software Foundation
- 5. Developer productivity 5 SELECT * FROM foo WHERE bar>30 HTable t = new HTable(“foo”); RegionScanner s = t.getScanner(new Scan(…, new ValueFilter(CompareOp.GT, new CustomTypedComparator(30)), …)); while ((Result r = s.next()) != null) { // Java Java Java } s.close(); t.close();
- 6. Phoenix architecture 6 Designed to scale to 10K nodes
- 7. Query processing in Phoenix 7 Data access can be much faster than via direct HBase API Pushes processing to the server via HBase coprocesors Maintains and utilizes secondary indexes Parallelizes queries Many other “tricks in the book”
- 8. Transaction requirements in Phoenix 8 ACID Multiple data accesses in a single logical operation Atomic “All or nothing” – no partial effect observable Consistent The DB transitions from one valid state to another Isolated Appear to execute in isolation Durable Committed data cannot disappear
- 9. Transaction requirements in Phoenix 9 SQL transactions Secondary index Atomic update On-the-fly index creation
- 10. Transaction requirements in Phoenix 10 Secondary index Atomic update (k1, [v1,v2,v3]) Table Index (v1, k1) Write (k1, ]v1,v2,v3])
- 11. Transaction requirements in Phoenix 11 Secondary index On-the-fly index creation (k1, v1) Table Index (k2, v2) (k3, v3) (kn, vn) . . . (v1, k1) (v2, k2) (v3, k3) (vn, kn) . . .
- 12. Omid 12 2011 Incepted @Yahoo Research “Omid1” 2014 Large-Scale Deployment @Yahoo 2014/5 Major Re- Design for Scalability & HA “Omid2” 2016 Apache Incubator 2017 Prototype Integration with Phoenix Transaction Processing Service for Apache HBase
- 13. Contributors 13 Ohad Shacham Yahoo Research Francisco Perez Sorrosal YahooEdward Bortnikov Yahoo Research Eshcar Hillel Yahoo Research Idit Keidar Yahoo, Technion Ivan Kelly MidokuraSameer Paranjpye Databricks Matthieu Morel Skyscanner Igor Katkov Atlassian Yonatan Gottesman Yahoo Research
- 14. Omid 14 Client Library + Runtime Service Database Agnostic (can work with other backends) Snapshot Isolation consistency Very Scalable (>400K peak tps) and Highly Available
- 15. Omid programming example 15 TransactionManager tm = HBaseTransactionManager.newInstance(); TTable txTable = new TTable("MY_TX_TABLE”); Transaction tx = tm.begin(); // Control path Put row1 = new Put(Bytes.toBytes("EXAMPLE_ROW1")); row1.add(family, qualifier, Bytes.toBytes("val1")); txTable.put(tx, row1); // Data path Put row2 = new Put(Bytes.toBytes("EXAMPLE_ROW2")); row2.add(family, qualifier, Bytes.toBytes("val2")); txTable.put(tx, row2); // Data path tm.commit(tx); // Control path
- 16. Transactions and snapshot isolation Aborts only on write-write conflicts Read point Write point begin commitread(x) write(y) write(x) read(y)
- 17. Omid architecture Client Begin/Commit Data Data Data Commit Table Persist Commit Verify commitRead/Write Conflict Detection 17 Transaction Manager (TSO)Results/Timestamp
- 18. Client Begin Data Data Data Commit Table t1 Write (k1, v1, t1) Write (k2, v2, t1) Read (k’, last committed t’ < t1) (k1, v1, t1) (k2, v2, t1) Execution example tr = t1 TSO 18
- 19. Client Commit: t1, {k1, k2} Data Data Data Commit Table t2 (k1, v1, t1) (k2, v2, t1) Write (t1, t2) (t1, t2) Execution example tr = t1 tc = t2 19 TSO
- 20. Client Data Data Data Commit Table Read (k1, t3) (k1, v1, t1) (k2, v2, t1) (t1, t2) Read (t1) Execution example tr = t3 20 Bottleneck! TSO
- 21. Client Data Data Data Commit Table t2 (t1, t2)(k1,v1,t1,t2) (k2,v2,t1,t2) Delete(t1) Post-Commit tr = t1 tc = t2 Update commit cells 21 TSO
- 22. Data Data Data Commit Table Read (k1, t3) Using Commit Cells Client tr = t3 22 TSO (k1,v1,t1,t2) (k2,v2,t1,t2)
- 23. Omid architecture Client Begin/Commit Data Data Data Commit Table Persist Commit Verify commitRead/Write Single point of failure 23 Transaction Manager (TSO)Results/Timestamp
- 24. Omid architecture Client Begin/Commit Data Data Data Commit Table Verify commitRead/Write 24 Results/Timestamp Transaction Manager (TSO) Transaction Manager (TSO) Recovery state
- 25. Phoenix-Omid Integration 25 Omid support: https://issues.apache.org/jira/browse/OMID-82 Phoenix plan: https://issues.apache.org/jira/browse/PHOENIX-3623
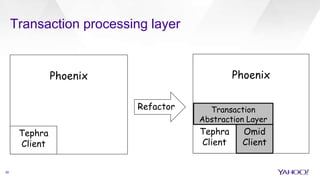
- 26. Transaction processing layer 26 Transaction Abstraction Layer Tephra Client Omid Client PhoenixPhoenix Tephra Client Refactor
- 27. New scenarios for Omid 27 Secondary Indexes On-the-Fly Index Creation Atomic Updates Extended Snapshot Isolation Read-Your-Own-Writes Queries
- 28. On-the-fly secondary index creation 28 CREATE INDEX (CI) in parallel with writes to the base table Need to distinguish between the pre-CI and post-CI data Augment Omid with a fence command, called in every CI 1. All data committed before fence: scanned, bulk-inserted into index 2. All data generated after fence: triggers random update of index 3. All transactions in flight at fence: aborted
- 29. Secondary index: creation and maintenance 29 T1 T2 T3 CREATE INDEX started T4 CREATE INDEX complete T5 T6 Bulk-Insert into index Abort (enforced upon commit) Added by a coproces sor Added by a coproces sor Index update (stored procedure)
- 30. Extended snapshot isolation 30 BEGIN; INSERT INTO T SELECT ID+10 FROM T; INSERT INTO T SELECT ID+100 FROM T; COMMIT; CREATE TABLE T (ID INT); ...
- 31. Moving snapshot implementation 31 Checkpoint for Statement 1 Checkpoint for Statement 2 Writes by Statement 1 Timestamps allocated by TM in blocks. Client promotes the checkpoint.
- 32. Omid required features 32 Scan Phoenix uses a coprocessor to filter/aggregate close to data Part of the Omid client logic moves downstream Secondary index Phoenix uses a coprocessor to populate an index in a bulk Omid auto commit, GC should be disabled Phoenix uses another coprocessor for incremental updates Omid must take care of shadow cell manipulation
- 33. Omid required features 33 Row level conflict analysis Conflict analysis free writes Time based timestamp
- 34. Low latency Omid 34 Omid design is throughput oriented writes to Commit Table batched at the TSO Distribute the Writes to the commit table The client, rather than the TSO, persists the Commit Timestamp
- 35. Benchmark: Single-Write Transaction Workload Easily scales beyond 500K tps Latency problem solved TSO latency bottleneck!
- 36. Summary 36 Apache Phoenix need a scalable and HA Tps Omid is Battle-Tested, Highly Scalable, Low-Latency Phoenix-Omid integration provides an efficient OLTP for Hadoop