





































Open Source Data Deduplication
- 1. Open Source Data Deduplication Nick Webb [email protected] www.redwireservices.com @RedWireServices (206) 829-8621 Last updated 8/10/2011
- 2. Introduction ● What is Deduplication? Different kinds? ● Why do you want it? ● How does it work? ● Advantages / Drawbacks ● Commercial Implementations ● Open Source implementations, performance, reliability, and stability of each
- 3. What is Data Deduplication Wikipedia: . . . data deduplication is a specialized data compression technique for eliminating coarse-grained redundant data, typically to improve storage utilization. In the deduplication process, duplicate data is deleted, leaving only one copy of the data to be stored, along with references to the unique copy of data. Deduplication is able to reduce the required storage capacity since only the unique data is stored. Depending on the type of deduplication, redundant files may be reduced, or even portions of files or other data that are similar can also be removed . . .
- 4. Why Dedupe? ● Save disk space and money (less disks) ● Less disks = less power, cooling, and space ● Improve write performance (of duplicate data) ● Be efficient – don’t re-copy or store previously stored data
- 5. Where does it Work Well? ● Secondary Storage ● Backups/Archives ● Online backups with limited bandwidth/replication ● Save disk space – additional full backups take little space ● Virtual Machines (Primary & Secondary) ● File Shares
- 6. Not a Fit ● Random data ● Video ● Pictures ● Music ● Encrypted files – many vendors dedupe, then encrypt
- 7. Types ● Source / Target ● Global ● Fixed/Sliding Block ● File Based (SIS)
- 8. Drawbacks ● Slow writes, slower reads ● High CPU/memory utilization (dedicated server is a must) ● Increases data loss risk / corruption ● Collision risk of 1.3x10^-49% chance per PB ● (256 bit hash & 8KB Blocks)
- 9. How Does it Work?
- 10. Without Dedupe
- 11. With Dedupe
- 12. Block Reclamation ● In general, blocks are not removed/freed when a file is removed ● We must periodically check blocks for references, a block with no reference can be deleted, freeing allocated space ● Process can be expensive, scheduled during off-peak
- 13. Commercial Implementations ● Just about every backup vendor ● Symantec, CommVault ● Cloud: Asigra, Baracuda, Dropbox (global), JungleDisk, Mozy ● NAS/SAN/Backup Targets ● NEC HydraStor ● DataDomain/EMC Avamar ● Quantum ● NetApp
- 14. Open Source Implementations ● Fuse Based ● Lessfs ● SDFS (OpenDedupe) ● Others ● ZFS ● btrfs (? Off-line only) ● Limited (file based / SIS) ● BackupPC (reliable!) ● Rdiff-backup
- 15. How Good is it? ● Many see 10-20x deduplicaiton meaning 10-20 times more logical object storage than physical ● Especially true in backup or virtual environments
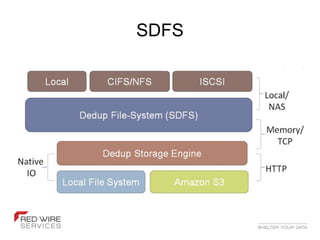
- 16. SDFS / OpenDedupe www.opendedup.org ● Java 7 Based / platform agnostic ● Uses fuse ● S3 storage support ● Snapshots ● Inline or batch mode deduplication ● Supposedly fast (290MBps+ on great H/W) ● Support for global/clustered dedupe ● Probably most mature OSS Dedupe (IMHO)
- 17. SDFS
- 18. SDFS Install & Go Install Java # rpm –Uvh SDFS-1.0.7-2.x86_64.rpm # sudo mkfs.sdfs --volume-name=sdfs_128k --io-max-file-write-buffers=32 --volume-capacity=550GB --io-chunk-size=128 --chunk-store-data-location=/mnt/data # sudo modprobe fuse # sudo mount.sdfs -v sdfs_128k -m /mnt/dedupe
- 19. SDFS ● Pro ● Works when configured properly ● Appears to be multithreaded ● Con ● Slow / resource intensive (CPU/Memory) ● Fragile, easy to mess up options, leading to crashes, little user feedback ● Standard POSIX utilities do not show accurate data (e.g. df, must use getfattr -d <mount point>, and calculate bytes → GB/TB and % free yourself) ● Slow with 4k blocks, recommended for VMs
- 20. LessFS www.lessfs.com ● Written in C = Less CPU Overhead ● Have to build yourself (configure && make && make install) ● Has replication, encryption ● Uses fuse
- 21. LessFS Install wget http://...lessfs-1.4.2.tar.gz tar zxvf *.tar.gz wget http://...db-4.8.30.tar.gz yum install buildstuff… . . . echo never > /sys/kernel/mm/redhat_transparent_hugepage/defrag echo no > /sys/kernel/mm/redhat_transparent_hugepage/khugep aged/defrag
- 22. LessFS Go sudo vi /etc/lessfs.cfg BLOCKDATA_PATH=/mnt/data/dta/blockdata.dta META_PATH=/mnt/meta/mta BLKSIZE=4096 # only 4k supported on centos 5 ENCRYPT_DATA=on ENCRYPT_META=off mklessfs -c /etc/lessfs.cfg lessfs /etc/lessfs.cfg /mnt/dedupe
- 23. LessFS ● Pro ● Does inline compression by default as well ● Reasonable VM compression with 128k blocks ● Con ● Fragile ● Stats/FS info hard to see (per file accounting, no totals) ● Kernel >= 2.6.26 required for blocks > 4k (RHEL6 only) ● Running with 4k blocks is not really feasible
- 24. LessFS
- 25. Other OSS ● ZFS? ● Tried it, and empirically it was a drag, but I have no hard data (got like 3x dedupe with identical full backups of VMs) ● At least it’s stable…
- 26. Kick the Tires ● Test data set; ~330GB of data ● 22GB of documents, pictures, music ● Virtual Machines – 220GB Windows 2003 Server with SQL Data – 2003 AD DC ~60GB – 2003 Server ~8GB – Two OpenSolaris VMs, 1.5 & 2.7GB – 3GB Windows 2000 VM – 15GB XP Pro VM
- 27. Kick the Tires ● Test Environment ● AWS High CPU Extra Large Instance ● ~7GB of RAM ● ~Eight Cores ~2.5GHz each ● ext4
- 28. Compression Performance ● First round (all “unique” data) ● If another copy was put in (like another full), we should expect 100% reduction for that non-unique data (1x dedupe per run) FS Home % Home VM % VM Combined % Total MBps Data Reduction Data Reduction Reduction SDFS 4k 21GB 4.50% 109 64% 128GB 61% 16 GB lessfs 4k 24GB -9% N/A 51% N/A 50% 4 (est.) SDFS 128k 21GB 4.50% 255 16% 276GB 15% 40 GB lessfs 128k 21GB 4.50% 130 57% 183GB 44% 24 GB tar/gz --fast 21GB 4.50% 178 41% 199GB 39% 35 GB
- 30. Write Performance (don't trust this) MBps 40 35 30 25 20 MBps 15 10 5 0 raw SDFS 4k lessfs 4k SDFS 128k lessfs 128k tar/gz --fast
- 31. Kick the Tires: Part 2 ● Test data set – two ~204GB full backup archives from a popular commercial vendor ● Test Environment ● VirtualBox VM, 2GB RAM, 2 Cores, 2x7200RPM SATA drives (meta & data separated for LessFS) ● Physical CPU: Quad Core Xeon
- 32. Write Performance MBps 40 35 30 25 20 MBps 15 10 5 0 raw SDFS 128k W SDFS 128k Re-W LessFS 128k W LessFS 128k Re-W
- 34. Load (SDFS 128k)
- 35. Open Source Dedupe ● Pro ● Free ● Can be stable, if well managed ● Con ● Not in repos yet ● Efforts behind them seem very limited, 1 dev each ● No/Poor documentation
- 36. The Future ● Eventual Commodity? ● brtfs ● Dedupe planned (off-line only)
- 37. Conclusion/Recommendations ● Dedupe is great, if it works and it meets your performance and storage requirements ● OSS Dedupe has a way to go ● SDFS/OpenDedupe is best OSS option right now ● JungleDisk is good and cheap, but not OSS
- 38. About Red Wire Services If you found this presentation helpful, consider Red Wire Services for your next Backup, Archive, or IT Disaster Recovery Planning project. Learn more at www.RedWireServices.com
- 39. About Nick Webb Nick Webb is the founder of Red Wire Services, in Seattle, WA. Nick is available to speak on a variety of IT Disaster Recovery related topics, including: ● Preserving Your Digital Legacy ● Getting Started with your Small Business Disaster Recovery Plan ● Archive Storage for SMBs If interested in having Nick speak to your group, please call (206) 829-8621 or email [email protected]