Optimization algorithms in machine learning
0 likes286 views

Gradient descent부터 AMSGrad까지 최적화 알고리즘에 대해 소개하는 자료입니다. 추가로 Hessian free 알고리즘인 SR1, DFP, BFGS에 대해서도 간략히 소개하고, 알고리즘을 시각화하여 비교한 자료입니다. This slide introduces the optimization algorithms from first-order(gradient descent) to second-order(hessian free). It deals with all the algorithms in the Keras optimizer. It was made by Taewon Heo.




![Adaptive method
6
Adagrad
𝐺𝑡 = 𝐺𝑡−1 + 𝛻𝜃 𝑡
𝐽 𝜃𝑡
2
𝜃𝑡+1 = 𝜃𝑡 −
η
𝐺𝑡 + 𝜀
𝛻𝜃 𝑡
𝐽 𝜃𝑡
𝐺𝑡: 𝑠𝑢𝑚 𝑜𝑓 𝑠𝑞𝑢𝑟𝑒𝑠 =
𝑖
4
𝛻𝜃 𝑖
𝐽 𝜃𝑖
2 (𝐿2 𝑛𝑜𝑟𝑚)
𝜀: 10−8
𝑑𝑒𝑓𝑎𝑢𝑙𝑡 0으로 나눠지는 걸 방지하는 term
RMSProp
𝐺𝑡 = 𝛽𝐺𝑡−1 + (1 − 𝛽)𝛻𝜃 𝑡
𝐽 𝜃𝑡
2
𝜃𝑡+1 = 𝜃𝑡 −
η
𝐺𝑡 + 𝜀
𝛻𝜃 𝑡
𝐽 𝜃𝑡
𝑅𝑀𝑆[𝑔] 𝑡 = 𝐺𝑡 + 𝜀
𝛽: 𝑒𝑥𝑝𝑜𝑛𝑒𝑛𝑡𝑖𝑎𝑙 𝑑𝑒𝑐𝑎𝑦 𝑟𝑎𝑡𝑒,
0 < 𝛽 < 1, 𝑑𝑒𝑓𝑎𝑢𝑙𝑡 𝛽 = 0.9
점화식으로 쓰는 이유는?
𝜃 업데이트 시 계산 효율 상 이전 값만 기억하
면 됨𝐺4 = 𝛻𝜃4
𝐽 𝜃4
2 + 𝛻𝜃3
𝐽 𝜃3
2 + 𝛻𝜃2
𝐽 𝜃2
2 + 𝛻𝜃1
𝐽 𝜃1
2 + 𝛻𝜃0
𝐽 𝜃0
2 =
𝑖
4
𝛻𝜃 𝑖
𝐽 𝜃𝑖
2
t가 커짐에 따라 𝑮𝒕 값이 계속 커지고 learning rate가 매우 작아지는
단점이 있음
𝐺4 = (1 − 𝛽)𝛻𝜃4
𝐽 𝜃4
2 + (1 − 𝛽)𝛽 𝛻𝜃3
𝐽 𝜃3
2 + (1 − 𝛽)𝛽2 𝛻𝜃2
𝐽 𝜃2
2 + (1 − 𝛽)𝛽3 𝛻𝜃1
𝐽 𝜃1
2 + (1 − 𝛽)𝛽4 𝛻𝜃0
𝐽 𝜃0
2
오래된 gradient의 영향이 지수함수적으로 감소(exponentially decaying average of squared
gradients)
𝐺𝑡 ≈ 𝑎𝑣𝑒𝑟𝑎𝑔𝑒 𝑜𝑓 𝑝𝑎𝑠𝑡
1
1−𝛽
, 𝛽가 0.9이면 𝐺𝑡는 지난 10개의 평균과 비슷함(accumulation is
restricted)
Exponentially weighted average](https://image.slidesharecdn.com/optimizationalgorithmsinmachinelearninglinkedin-190611071307/85/Optimization-algorithms-in-machine-learning-6-320.jpg)
![Adaptive method
7
Adadelta
𝐺𝑡 = 𝛽𝐺𝑡−1 + (1 − 𝛽)𝛻𝜃 𝑡
𝐽 𝜃𝑡
2
𝑆𝑡 = 𝛽𝑆𝑡−1 + (1 − 𝛽)∆𝜃𝑡
2
𝜃𝑡+1 = 𝜃𝑡 −
𝑆𝑡 + 𝜀
𝐺𝑡 + 𝜀
𝛻𝜃 𝑡
𝐽 𝜃𝑡
𝛽: 𝑒𝑥𝑝𝑜𝑛𝑒𝑛𝑡𝑖𝑎𝑙 𝑑𝑒𝑐𝑎𝑦 𝑟𝑎𝑡𝑒, 0 < 𝛽 < 1
Adagrad의 단점 극복
① 시간이 지남에 따라 learning rate가 계속 작아짐.
𝑹𝑴𝑺[𝒈] 𝒕를 분모항에 넣어 가중치 learning rate가 0에 수렴하는 것을 방지
② Global learning rate를 사람이 정해야 함.
𝑺 𝒕+𝟏 = 𝜷𝑺 𝒕 + (𝟏 − 𝜷)∆𝜽 𝒕
𝟐
Global learning rate 대신 지난 update(∆𝜽)의 Exponentially weighted average(𝑹𝑴𝑺[∆𝜽] 𝒕)를 사용
𝑅𝑀𝑆[𝑔] 𝑡 = 𝐸[𝑔2] 𝑡 + 𝜀
𝑅𝑀𝑆[∆𝜃] 𝑡= 𝐸[𝜃2] 𝑡 + 𝜀
𝜃𝑡+1
= 𝜃𝑡 −
𝑅𝑀𝑆[∆𝜃] 𝑡−1
𝑅𝑀𝑆[𝑔] 𝑡
𝛻𝜃 𝑡
𝐽 𝜃𝑡
=](https://image.slidesharecdn.com/optimizationalgorithmsinmachinelearninglinkedin-190611071307/85/Optimization-algorithms-in-machine-learning-7-320.jpg)
![Adam
8
𝑣 𝑡 = 𝛽1 𝑣 𝑡−1 + (1 − 𝛽1)𝛻𝜃𝑡
𝐽 𝜃𝑡
𝐺𝑡 = 𝛽2 𝐺𝑡−1 + (1 − 𝛽2)𝛻𝜃𝑡
𝐽 𝜃𝑡
2
𝜃𝑡+1 = 𝜃𝑡 −
η
𝐺𝑡 + 𝜀
ො𝑣 𝑡
𝛽: 𝑒𝑥𝑝𝑜𝑛𝑒𝑛𝑡𝑖𝑎𝑙 𝑑𝑒𝑐𝑎𝑦 𝑟𝑎𝑡𝑒, 0 < 𝛽 < 1
𝑑𝑒𝑓𝑎𝑢𝑙𝑡 𝛽1 = 0.9 , 𝛽2 = 0.999
ො𝑣 𝑡 =
𝑣 𝑡
1 − 𝛽1
𝑡
𝐺𝑡 =
𝐺𝑡
1 − 𝛽2
𝑡
Momentum + Adaptive
Exponential weighted average에서 초기 값이 실제보다 작아지는 문제를 해결하기 위해 bias correction 항 사용
① Exponentially decaying momentum
② RMSProp와 같이 𝑅𝑀𝑆[𝑔] 𝑡를 분모항에 넣어 가중치 learning rate가 0에 수렴하는 것을 방지
Bias correction
Bias
Exponentially decaying
momentum](https://image.slidesharecdn.com/optimizationalgorithmsinmachinelearninglinkedin-190611071307/85/Optimization-algorithms-in-machine-learning-8-320.jpg)







𝑎 = 𝑠𝑖𝑔𝑛 𝑠 𝑇
𝑦 − 𝐵𝑠 , 𝛿 = ± 𝑠 𝑇
𝑦 − 𝐵𝑠 −1/2
𝐵+ = 𝐵 +
𝑦 − 𝐵𝑠 𝑦 − 𝐵𝑠 𝑇
𝑦 − 𝐵𝑠 𝑇 𝑠
Inverse hessian H을 근사하는 𝐵−1을 업데이트 할 수 있다면?
𝑥+
= 𝑥 + 𝑡𝑝 = 𝑥 + 𝑡𝐵−
𝛻𝑓(𝑥)
𝐻+
= 𝐻 +
𝑠 − 𝐻𝑦 𝑠 − 𝐻𝑦 𝑇
𝑠 − 𝐻𝑦 𝑇 𝑦
Update form
위 등식을 만족하는 파라미터 𝛿와 𝑎
위의 값을 𝐵+ = 𝐵 + 𝑎𝑢𝑢 𝑇에 대입
Rank-1의 symmetric matrix를 𝑎 ∈ −1,1 과 𝑢 ∈ 𝑅 𝑛의 곱으로 분해
SR1의 단점
① 분모 항인 𝑦 − 𝐵𝑠 𝑇 𝑠가 0에 가까워지면 업데이트에 실패할 수 있다.
② B와 H가 positive definiteness를 유지하지 못할 수 있다.
Sherman-Morrison formula를 이용하면 𝐵−도 동일한 형태로 업데이트 할 수
있다. (𝐻 = 𝐵−)](https://image.slidesharecdn.com/optimizationalgorithmsinmachinelearninglinkedin-190611071307/85/Optimization-algorithms-in-machine-learning-15-320.jpg)


![Reference
19
Papers & Lecture notes
[1] John Duchi, Elad Hazan, Yoram Singer, Adaptive Subgradient Methods for Online Learning and Stochastic Optimization, The Journal of
Machine Learning Research, Volume 12, 2121-2159, 2011
[3] Diederik P. Kingma, Jimmy Ba, Adam: A method for stochastic optimization, arXiv:1412.6980
[4] Matthew D. Zeiler, ADADELTA: An Adaptive Learning Rate Method, arXiv:1212.5701
[5] G. Hinton’s lecture 6a, 6c
[6] Timothy Dozat, Incorporating Nesterov Momentum into Adam
[7] Sashank J. Reddi, Satyen Kale & Sanjiv Kumar, On the Convergence of Adam and Beyond, arXiv:1904.09237
[7] Pradeep Ravikumar, Aarti Singh, lecture notes : Convex Optimization 10-725/36-725, Carnegie Mellon University
Websites
[1] https://tensorflow.blog/2017/03/22/momentum-nesterov-momentum/#3
[2] http://ruder.io/optimizing-gradient-descent/index.html#fn19
[3] http://www.cs.cmu.edu/~pradeepr/convexopt/](https://image.slidesharecdn.com/optimizationalgorithmsinmachinelearninglinkedin-190611071307/85/Optimization-algorithms-in-machine-learning-19-320.jpg)
Optimization algorithms in machine learning
- 1. Nonlinear Programming Tutorial for Optimization Algorithms in Machine Learning 1 연세대학교 산업공학과 System Intelligence Lab 허태원 석사과정
- 4. Gradient Method Algorithms 4 Momentum NAG Adaptive Adagrad RMSProp AdaDelta Adam AMSGrad Nadam AdaMax L2 norm L2 norm 𝐿∞ norm L2 norm Momentum L2 norm
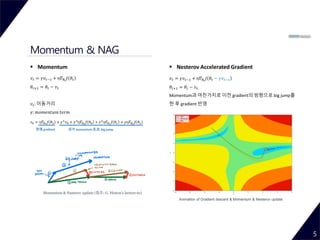
- 5. Momentum & NAG 5 Momentum 𝑣 𝑡 = 𝛾𝑣 𝑡−1 + η𝛻𝜃𝑡 𝐽 𝜃𝑡 𝜃𝑡+1 = 𝜃𝑡 − 𝑣 𝑡 𝑣 𝑡: 이동거리 𝛾: 𝑚𝑜𝑚𝑒𝑛𝑡𝑢𝑚 𝑡𝑒𝑟𝑚 𝑣4 = η𝛻𝜃3 𝐽 𝜃3 + 𝛾3 𝑣0 + 𝛾3η𝛻𝜃0 𝐽 𝜃0 + 𝛾2η𝛻𝜃1 𝐽 𝜃1 + 𝛾η𝛻𝜃2 𝐽 𝜃2 현재 gradient 과거 momentum 효과, big jump Nesterov Accelerated Gradient 𝑣 𝑡 = 𝛾𝑣 𝑡−1 + η𝛻𝜃𝑡 𝐽 𝜃𝑡 − 𝛾𝑣 𝑡−1 𝜃𝑡+1 = 𝜃𝑡 − 𝑣 𝑡 Momentum과 마찬가지로 이전 gradient의 방향으로 big jump를 한 후 gradient 반영 Momentum & Nesterov update (참조: G. Hinton’s lecture 6c) Animation of Gradient descent & Momentum & Nesterov update
- 6. Adaptive method 6 Adagrad 𝐺𝑡 = 𝐺𝑡−1 + 𝛻𝜃 𝑡 𝐽 𝜃𝑡 2 𝜃𝑡+1 = 𝜃𝑡 − η 𝐺𝑡 + 𝜀 𝛻𝜃 𝑡 𝐽 𝜃𝑡 𝐺𝑡: 𝑠𝑢𝑚 𝑜𝑓 𝑠𝑞𝑢𝑟𝑒𝑠 = 𝑖 4 𝛻𝜃 𝑖 𝐽 𝜃𝑖 2 (𝐿2 𝑛𝑜𝑟𝑚) 𝜀: 10−8 𝑑𝑒𝑓𝑎𝑢𝑙𝑡 0으로 나눠지는 걸 방지하는 term RMSProp 𝐺𝑡 = 𝛽𝐺𝑡−1 + (1 − 𝛽)𝛻𝜃 𝑡 𝐽 𝜃𝑡 2 𝜃𝑡+1 = 𝜃𝑡 − η 𝐺𝑡 + 𝜀 𝛻𝜃 𝑡 𝐽 𝜃𝑡 𝑅𝑀𝑆[𝑔] 𝑡 = 𝐺𝑡 + 𝜀 𝛽: 𝑒𝑥𝑝𝑜𝑛𝑒𝑛𝑡𝑖𝑎𝑙 𝑑𝑒𝑐𝑎𝑦 𝑟𝑎𝑡𝑒, 0 < 𝛽 < 1, 𝑑𝑒𝑓𝑎𝑢𝑙𝑡 𝛽 = 0.9 점화식으로 쓰는 이유는? 𝜃 업데이트 시 계산 효율 상 이전 값만 기억하 면 됨𝐺4 = 𝛻𝜃4 𝐽 𝜃4 2 + 𝛻𝜃3 𝐽 𝜃3 2 + 𝛻𝜃2 𝐽 𝜃2 2 + 𝛻𝜃1 𝐽 𝜃1 2 + 𝛻𝜃0 𝐽 𝜃0 2 = 𝑖 4 𝛻𝜃 𝑖 𝐽 𝜃𝑖 2 t가 커짐에 따라 𝑮𝒕 값이 계속 커지고 learning rate가 매우 작아지는 단점이 있음 𝐺4 = (1 − 𝛽)𝛻𝜃4 𝐽 𝜃4 2 + (1 − 𝛽)𝛽 𝛻𝜃3 𝐽 𝜃3 2 + (1 − 𝛽)𝛽2 𝛻𝜃2 𝐽 𝜃2 2 + (1 − 𝛽)𝛽3 𝛻𝜃1 𝐽 𝜃1 2 + (1 − 𝛽)𝛽4 𝛻𝜃0 𝐽 𝜃0 2 오래된 gradient의 영향이 지수함수적으로 감소(exponentially decaying average of squared gradients) 𝐺𝑡 ≈ 𝑎𝑣𝑒𝑟𝑎𝑔𝑒 𝑜𝑓 𝑝𝑎𝑠𝑡 1 1−𝛽 , 𝛽가 0.9이면 𝐺𝑡는 지난 10개의 평균과 비슷함(accumulation is restricted) Exponentially weighted average
- 7. Adaptive method 7 Adadelta 𝐺𝑡 = 𝛽𝐺𝑡−1 + (1 − 𝛽)𝛻𝜃 𝑡 𝐽 𝜃𝑡 2 𝑆𝑡 = 𝛽𝑆𝑡−1 + (1 − 𝛽)∆𝜃𝑡 2 𝜃𝑡+1 = 𝜃𝑡 − 𝑆𝑡 + 𝜀 𝐺𝑡 + 𝜀 𝛻𝜃 𝑡 𝐽 𝜃𝑡 𝛽: 𝑒𝑥𝑝𝑜𝑛𝑒𝑛𝑡𝑖𝑎𝑙 𝑑𝑒𝑐𝑎𝑦 𝑟𝑎𝑡𝑒, 0 < 𝛽 < 1 Adagrad의 단점 극복 ① 시간이 지남에 따라 learning rate가 계속 작아짐. 𝑹𝑴𝑺[𝒈] 𝒕를 분모항에 넣어 가중치 learning rate가 0에 수렴하는 것을 방지 ② Global learning rate를 사람이 정해야 함. 𝑺 𝒕+𝟏 = 𝜷𝑺 𝒕 + (𝟏 − 𝜷)∆𝜽 𝒕 𝟐 Global learning rate 대신 지난 update(∆𝜽)의 Exponentially weighted average(𝑹𝑴𝑺[∆𝜽] 𝒕)를 사용 𝑅𝑀𝑆[𝑔] 𝑡 = 𝐸[𝑔2] 𝑡 + 𝜀 𝑅𝑀𝑆[∆𝜃] 𝑡= 𝐸[𝜃2] 𝑡 + 𝜀 𝜃𝑡+1 = 𝜃𝑡 − 𝑅𝑀𝑆[∆𝜃] 𝑡−1 𝑅𝑀𝑆[𝑔] 𝑡 𝛻𝜃 𝑡 𝐽 𝜃𝑡 =
- 8. Adam 8 𝑣 𝑡 = 𝛽1 𝑣 𝑡−1 + (1 − 𝛽1)𝛻𝜃𝑡 𝐽 𝜃𝑡 𝐺𝑡 = 𝛽2 𝐺𝑡−1 + (1 − 𝛽2)𝛻𝜃𝑡 𝐽 𝜃𝑡 2 𝜃𝑡+1 = 𝜃𝑡 − η 𝐺𝑡 + 𝜀 ො𝑣 𝑡 𝛽: 𝑒𝑥𝑝𝑜𝑛𝑒𝑛𝑡𝑖𝑎𝑙 𝑑𝑒𝑐𝑎𝑦 𝑟𝑎𝑡𝑒, 0 < 𝛽 < 1 𝑑𝑒𝑓𝑎𝑢𝑙𝑡 𝛽1 = 0.9 , 𝛽2 = 0.999 ො𝑣 𝑡 = 𝑣 𝑡 1 − 𝛽1 𝑡 𝐺𝑡 = 𝐺𝑡 1 − 𝛽2 𝑡 Momentum + Adaptive Exponential weighted average에서 초기 값이 실제보다 작아지는 문제를 해결하기 위해 bias correction 항 사용 ① Exponentially decaying momentum ② RMSProp와 같이 𝑅𝑀𝑆[𝑔] 𝑡를 분모항에 넣어 가중치 learning rate가 0에 수렴하는 것을 방지 Bias correction Bias Exponentially decaying momentum
- 9. AdaMax 9 𝑣 𝑡 = 𝛽1 𝑣 𝑡−1 + (1 − 𝛽1)𝛻𝜃𝑡 𝐽 𝜃𝑡 ො𝑣 𝑡 = 𝑣𝑡 1 − 𝛽1 𝑡 𝐺𝑡 = 𝛽2 𝐺𝑡−1 + (1 − 𝛽2)𝛻𝜃𝑡 𝐽 𝜃𝑡 2 → 𝐺𝑡 = 𝛽2 𝑝 𝐺𝑡−1 + (1 − 𝛽2 𝑝 )𝛻𝜃𝑡 𝐽 𝜃𝑡 𝑝 𝑢 𝑡 = lim 𝑝→∞ (𝐺𝑡)1/𝑝 = lim 𝑝→∞ (1 − 𝛽2 𝑝 )1/𝑝 𝑖=1 𝑡 𝛽2 𝑝(𝑡−1) ∙ 𝑔𝑖 𝑝 1/𝑝 = max(𝛽2 𝑡−1 𝑔1 , 𝛽2 𝑡−2 𝑔2 , ⋯ , 𝛽2 𝑔𝑡−1 , 𝑔𝑡 ) 𝜃𝑡+1 = 𝜃𝑡 − η 𝑢 𝑡 ො𝑣 𝑡 𝛽: 𝑒𝑥𝑝𝑜𝑛𝑒𝑛𝑡𝑖𝑎𝑙 𝑑𝑒𝑐𝑎𝑦 𝑟𝑎𝑡𝑒, 0 < 𝛽 < 1 𝑑𝑒𝑓𝑎𝑢𝑙𝑡 𝛽1 = 0.9 , 𝛽2 = 0.999 Special case of Adam ① Adam과 AdaMax 모두 sparse(ex. Word embedding)하거나 noisy한 조건에서 다른 알고리즘보다 좋은 성능을 보임. ② AdaMax의 경우 데이터의 변화가 큰 경우에 빠르게 수렴하는 특성이 있음. 일반적으로 p가 증가할수록 수치적으로 불안정해지기 때문 에 𝑙1과 𝑙2 𝑛𝑜𝑟𝑚이 많이 쓰이지만 𝑙∞ 는 안정적임 𝑙∞ 𝑖𝑠 𝑚𝑎𝑥𝑖𝑚𝑢𝑚 𝑣𝑎𝑙𝑢𝑒 𝑜𝑓 𝑖𝑛𝑑𝑖𝑣𝑖𝑠𝑢𝑎𝑙 𝑒𝑙𝑒𝑚𝑒𝑛𝑡𝑠
- 10. Nadam 10 NAG+Adam ① NAG는 classical momentum 보다 우수하며 gradient 방향으로 좀 더 정확하게 이동 ② 알고리즘을 합치기 위해 트릭을 썼지만 개념은 동일함. 𝑣 𝑡 = 𝛽1 𝑣 𝑡−1 + (1 − 𝛽1)𝛻𝜃𝑡 𝐽 𝜃𝑡 𝐺𝑡 = 𝛽2 𝐺𝑡−1 + (1 − 𝛽2)𝛻𝜃𝑡 𝐽 𝜃𝑡 2 𝜃𝑡+1 = 𝜃𝑡 − η 𝐺𝑡 + 𝜀 ො𝑣 𝑡 = 𝜃𝑡 − η 𝐺𝑡 + 𝜀 𝛽1 𝑣 𝑡−1 1 − 𝛽1 𝑡 − (1 − 𝛽1)𝛻𝜃𝑡 𝐽 𝜃𝑡 1 − 𝛽1 𝑡 𝛽: 𝑒𝑥𝑝𝑜𝑛𝑒𝑛𝑡𝑖𝑎𝑙 𝑑𝑒𝑐𝑎𝑦 𝑟𝑎𝑡𝑒, 0 < 𝛽 < 1 𝑑𝑒𝑓𝑎𝑢𝑙𝑡 𝛽1 = 0.9 , 𝛽2 = 0.999 ො𝑣 𝑡 = 𝑣 𝑡 1 − 𝛽1 𝑡 𝐺𝑡 = 𝐺𝑡 1 − 𝛽2 𝑡 Trick of NAG algorithm(Simplified NAG) 𝑣 𝑡 = 𝜇𝑣 𝑡−1 − 𝜖𝑔 𝜃𝑡 𝜃𝑡+1 = 𝜃𝑡 + 𝜇 𝜇𝑣 𝑡−1 − 𝜖𝑔 𝜃𝑡 − 𝜖𝑔 𝜃𝑡 𝑣 𝑡 = 𝛾𝑣 𝑡−1 − η𝛻𝜃𝑡 𝐽 𝜃𝑡 − 𝛾𝑣 𝑡−1 𝜃𝑡+1 = 𝜃𝑡 − (𝛾𝑣 𝑡−1 + η𝛻𝜃𝑡 𝐽 𝜃𝑡 − 𝛾𝑣 𝑡−1 ) 𝑣 𝑡 = 𝛾𝑣 𝑡−1 − η𝛻𝜃𝑡 𝐽 𝜃𝑡 𝜃𝑡+1 = 𝜃𝑡 − (𝛾𝑣 𝑡 + η𝛻𝜃𝑡 𝐽 𝜃𝑡 ) NAG rewritten 𝜃𝑡+1 = 𝜃𝑡 − η 𝐺𝑡 + 𝜀 ො𝑣 𝑡 − (1 − 𝛽1)𝑔𝑡 1 − 𝛽1 𝑡𝜃𝑡+1 = 𝜃𝑡 − η 𝐺𝑡 + 𝜀 ො𝑣 𝑡−1 − (1 − 𝛽1)𝑔𝑡 1 − 𝛽1 𝑡
- 11. AMSGrad 11 Adaptive methods의 단점 ① Exponential moving averages of squared past gradients로 스케일링된 adaptive methods는 출력 공간이 큰 학습에서 optimal 수렴에 실패하는 것 이 관측됨. ② The non-convergence of Adam: positive definiteness가 훼손 됐을 때, Adam이나 RMSProp은 종종 undesirable convergence를 보임. AMSGrad의 특징 ① Exponential weighted average의 문제라고 인식하여 𝐺𝑡 = max( 𝐺𝑡−1, 𝐺𝑡)를 사용. Non-increasing step size. Step size가 한번 작아지면 커지지 않는다. 𝑣 𝑡 = 𝛽1 𝑣 𝑡−1 + (1 − 𝛽1)𝛻𝜃𝑡 𝐽 𝜃𝑡 𝐺𝑡 = 𝛽2 𝐺𝑡−1 + (1 − 𝛽2)𝛻𝜃𝑡 𝐽 𝜃𝑡 2 𝐺𝑡 = max( 𝐺𝑡−1, 𝐺𝑡) 𝜃𝑡+1 = 𝜃𝑡 − η 𝐺𝑡 + 𝜀 ො𝑣 𝑡 𝛽: 𝑒𝑥𝑝𝑜𝑛𝑒𝑛𝑡𝑖𝑎𝑙 𝑑𝑒𝑐𝑎𝑦 𝑟𝑎𝑡𝑒, 0 < 𝛽 < 1 𝑑𝑒𝑓𝑎𝑢𝑙𝑡 𝛽1 = 0.9 , 𝛽2 = 0.999 성능 비교 I. Training and test loss for CIFARNET
- 12. Visualization 12 알고리즘 별 수렴 속도 비교 Animation of Gradient descent & Momentum & Nesterov updateAnimation of Adaptive Algorithms Case1: Adagrad < RMSProp < Adadelta < Adam Case2: Adamax < Nadam ≤ AMSGrad < Adam
- 14. Quasi-Newton Methods 14 Gradient descent method: 𝑥+ = 𝑥 − 𝑡𝛻𝑓(𝑥) Newton’s method: 𝑥+ = 𝑥 − 𝑡𝛻2 𝑓(𝑥)−1 𝛻𝑓(𝑥) Quasi-Newton’s method: 𝑥+ = 𝑥 + 𝑡𝑝 𝐵𝑝 = −𝛻𝑓 𝑥 B는 𝛻2 𝑓(𝑥)를 근사한 값이다. Optimal point에 점진적으로 다가갈 수 있도록 B를 업데이트 해나가는 것이 Quasi-Newton method의 특징 즉, B를 통해 𝑛𝑒𝑥𝑡 𝑠𝑡𝑒𝑝인 𝐵+ 구하는 방법에 따라 세분화 된다. Secant equation B는 𝐻𝑒𝑠𝑠𝑖𝑎𝑛 𝛻2 𝑓(𝑥)를 근사하는 행렬 𝑥 𝑘+1 = 𝑥 𝑘 + 𝑠 𝑘 이고 𝑓가 두 번 이상 미분 가능할 때, first-order Taylor expansion에 의 해 다음의 성질을 가진다. 𝛻2 𝑓 𝑥 𝑘 ≈ 𝛻𝑓 𝑥 𝑘 + 𝑠 𝑘 − 𝛻𝑓 𝑥 𝑘 𝑠 𝑘 𝐵 𝑘+1 𝑠 𝑘 = 𝑦 𝑘 𝑜𝑟 𝐵+ 𝑠 = 𝑦
- 15. Symmetric Rank-1 (SR1) 15 SR1 update는 rank-1의 symmetric matrix로 B를 업데이트 함으로써 B+(next B)가 symmetric를 유지하고 secant equation을 계속해서 만족하도록 업데이트하는 방법이다. 알고리즘이 간단한 것이 장점이다. Secant equation form을 만들기 위해 양변에 s를 곱한다. 𝑢를 𝑦 − 𝐵𝑠를 임의의 𝑠𝑐𝑎𝑙𝑎𝑟 𝛿와의 곱으로 표현 𝐵+ = 𝐵 + 𝑎𝑢𝑢 𝑇 𝐵+ 𝑠 = 𝐵𝑠 + 𝑎𝑢 𝑇 𝑠 𝑢 𝑢 = 𝛿(𝑦 − 𝐵𝑠) 𝑦 − 𝐵𝑠 = 𝑎𝛿2[𝑠 𝑇(𝑦 − 𝐵𝑠)](𝑦 − 𝐵𝑠) 𝑎 = 𝑠𝑖𝑔𝑛 𝑠 𝑇 𝑦 − 𝐵𝑠 , 𝛿 = ± 𝑠 𝑇 𝑦 − 𝐵𝑠 −1/2 𝐵+ = 𝐵 + 𝑦 − 𝐵𝑠 𝑦 − 𝐵𝑠 𝑇 𝑦 − 𝐵𝑠 𝑇 𝑠 Inverse hessian H을 근사하는 𝐵−1을 업데이트 할 수 있다면? 𝑥+ = 𝑥 + 𝑡𝑝 = 𝑥 + 𝑡𝐵− 𝛻𝑓(𝑥) 𝐻+ = 𝐻 + 𝑠 − 𝐻𝑦 𝑠 − 𝐻𝑦 𝑇 𝑠 − 𝐻𝑦 𝑇 𝑦 Update form 위 등식을 만족하는 파라미터 𝛿와 𝑎 위의 값을 𝐵+ = 𝐵 + 𝑎𝑢𝑢 𝑇에 대입 Rank-1의 symmetric matrix를 𝑎 ∈ −1,1 과 𝑢 ∈ 𝑅 𝑛의 곱으로 분해 SR1의 단점 ① 분모 항인 𝑦 − 𝐵𝑠 𝑇 𝑠가 0에 가까워지면 업데이트에 실패할 수 있다. ② B와 H가 positive definiteness를 유지하지 못할 수 있다. Sherman-Morrison formula를 이용하면 𝐵−도 동일한 형태로 업데이트 할 수 있다. (𝐻 = 𝐵−)
- 16. 𝐻+ = 𝐻 + 𝑎𝑢𝑢 𝑇 + 𝑏𝑣𝑣 𝑇 𝐻+ 𝑦 = 𝐻𝑦 + 𝑎𝑢 𝑇 𝑦 𝑢 + 𝑏𝑣 𝑇 𝑦 𝑣 𝐻+ = 𝐻 − 𝐻𝑦𝑦 𝑇 𝐻 𝑦 𝑇 𝐻𝑦 + 𝑠𝑠 𝑇 𝑦 𝑇 𝑠 𝐵+ = 𝐵 + 𝑦 − 𝐵𝑠 𝑦 𝑇 𝑦 𝑇 𝑠 + 𝑦 𝑦 − 𝐵𝑠 𝑇 𝑦 𝑇 𝑠 − 𝑦 − 𝐵𝑠 𝑇 𝑠 (𝑦 𝑇 𝑠)2 𝑦𝑦 𝑇 = 𝐼 − 𝑦𝑠 𝑇 𝑦 𝑇 𝑠 𝐵 𝐼 − 𝑠𝑦 𝑇 𝑦 𝑇 𝑠 + 𝑦𝑦 𝑇 𝑦 𝑇 𝑠 DFP Algorithm 16 Davidon-Fletcher-Powell(DFP) update는 rank-2의 symmetric matrix로 𝐻(= 𝐵− )를 업데이트하는 방법이다. Secant equation form을 만들기 위해 양변에 y를 곱한다. 𝑢 = 𝑠, 𝑣 = 𝐻𝑦로 두고 a와 b에 대해 푼다. Update form Secant equation에 의해 𝐵+ 𝑠 = 𝑦 ↔ 𝐻+ 𝑦 = 𝑠 SR1의 지속성 문제 해결 ① B가 positive definite 이면 𝐼 − 𝑦𝑠 𝑇 𝑦 𝑇 𝑠 𝐵 𝐼 − 𝑠𝑦 𝑇 𝑦 𝑇 𝑠 는 positive semidefinite이 된다. 이때 𝑦𝑦 𝑇 𝑦 𝑇 𝑠 가 positive definite이면 𝐵+ = 𝐼 − 𝑦𝑠 𝑇 𝑦 𝑇 𝑠 𝐵 𝐼 − 𝑠𝑦 𝑇 𝑦 𝑇 𝑠 + 𝑦𝑦 𝑇 𝑦 𝑇 𝑠 는 positive definite임이 보장되어 SR1의 문제가 해결된다. SR1과 마찬가지로 Sherman-Morrison formula 를 이용하여 B에 대한 updating formula 유도
- 17. 𝐵+ = 𝐵 + 𝑎𝑢𝑢 𝑇 + 𝑏𝑣𝑣 𝑇 𝐵+ 𝑠 = 𝐵𝑠 + 𝑎𝑢 𝑇 𝑠 𝑢 + 𝑏𝑣 𝑇 𝑠 𝑣 𝐵+ = 𝐵 − 𝐵𝑠𝑠 𝑇 𝐵 𝑠 𝑇 𝐵𝑠 + 𝑦𝑦 𝑇 𝑦 𝑇 𝑠 𝐻+ = 𝐻 + 𝑠 − 𝐻𝑦 𝑠 𝑇 𝑦 𝑇 𝑠 + 𝑠 𝑠 − 𝐻𝑦 𝑇 𝑦 𝑇 𝑠 − 𝑠 − 𝐻𝑦 𝑇 𝑦 (𝑦 𝑇 𝑠)2 𝑠𝑠 𝑇 = 𝐼 − 𝑠𝑦 𝑇 𝑦 𝑇 𝑠 𝐻 𝐼 − 𝑦𝑠 𝑇 𝑦 𝑇 𝑠 + 𝑠𝑠 𝑇 𝑦 𝑇 𝑠 BFGS Algorithm 17 BFGS의 아이디어는 DFP와 동일하고 B와 H의 역할이 바뀌었다는 것이 차이점이다. Secant equation form을 만들기 위해 양변에 y를 곱한다. 𝑢 = 𝑦, 𝑣 = 𝐵𝑠로 두고 a와 b에 대해 푼다. Update form Secant equation에 의해 𝐵+ 𝑠 = 𝑦 ↔ 𝐻+ 𝑦 = 𝑠 SR1의 지속성 문제 해결 ① DFP와 마찬가지로 SR1의 지속성 문제를 해결할 수 있다. ② In practice BFGS seems to work better than DFP DFP과 마찬가지로 Sherman-Morrison formula 를 이용하여 H에 대한 updating formula 유도
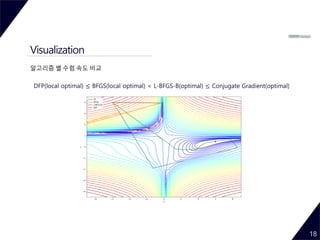
- 18. Visualization 18 알고리즘 별 수렴 속도 비교 DFP(local optimal) ≤ BFGS(local optimal) < L-BFGS-B(optimal) ≤ Conjugate Gradient(optimal)
- 19. Reference 19 Papers & Lecture notes [1] John Duchi, Elad Hazan, Yoram Singer, Adaptive Subgradient Methods for Online Learning and Stochastic Optimization, The Journal of Machine Learning Research, Volume 12, 2121-2159, 2011 [3] Diederik P. Kingma, Jimmy Ba, Adam: A method for stochastic optimization, arXiv:1412.6980 [4] Matthew D. Zeiler, ADADELTA: An Adaptive Learning Rate Method, arXiv:1212.5701 [5] G. Hinton’s lecture 6a, 6c [6] Timothy Dozat, Incorporating Nesterov Momentum into Adam [7] Sashank J. Reddi, Satyen Kale & Sanjiv Kumar, On the Convergence of Adam and Beyond, arXiv:1904.09237 [7] Pradeep Ravikumar, Aarti Singh, lecture notes : Convex Optimization 10-725/36-725, Carnegie Mellon University Websites [1] https://tensorflow.blog/2017/03/22/momentum-nesterov-momentum/#3 [2] http://ruder.io/optimizing-gradient-descent/index.html#fn19 [3] http://www.cs.cmu.edu/~pradeepr/convexopt/