Optimizing MySQL queries
Download as PPTX, PDF1 like722 views

This document provides an overview of optimizing MySQL queries. It discusses optimization at the database and hardware levels, understanding query execution plans, using EXPLAIN to analyze queries, optimizing specific query types like counts and groups, indexing strategies like covering indexes, and partitioning tables for performance. The goal is to help readers write efficient queries and properly structure databases and indexes for high performance.
















































Optimizing MySQL queries
- 2. OVERVIEW • Optimization Overview • Understanding the Query Execution • Using explain • Optimizing Specific Types of Queries • Indexing • Partitioning • Demo partitioning
- 3. 1. OPTIMIZATION OVERVIEW 1.1 Optimizing at the Database Level • tables • indexes • storage engine • locking strategy • Are all memory areas used for caching sized correctly?
- 4. 1. OPTIMIZATION OVERVIEW 1.2 Optimizing at the Hardware Level • Disk seeks • Disk reading and writing • CPU cycles • Memory bandwidth
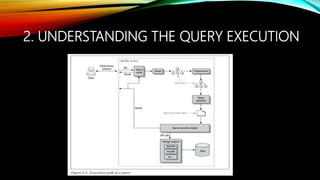
- 5. 2. UNDERSTANDING THE QUERY EXECUTION
- 6. 2. UNDERSTANDING THE QUERY EXECUTION 1. The client sends the SQL statement to the server. 2. The server checks the query cache. If there’s a hit, it returns the stored result from the cache; otherwise, it passes the SQL statement to the next step. 3. The server parses, preprocesses, and optimizes the SQL into a query execution plan. 4. The query execution engine executes the plan by making calls to the storage engine API. 5. The server sends the result to the client.
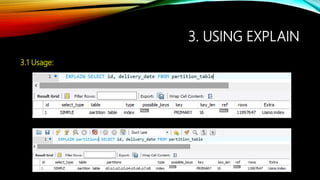
- 7. 3. USING EXPLAIN 3.1 Usage: • EXPLAIN is used to obtain a query execution plan. • EXPLAIN is useful for examining queries involving partitioned tables. • EXPLAIN works with SELECT, DELETE, INSERT, REPLACE, and UPDATE statements.
- 8. 3. USING EXPLAIN 3.1 Usage:
- 9. 3. USING EXPLAIN 3.3 What should I care about?
- 10. 3. USING EXPLAIN 3.3 What should I care about? • Partitions • Extra • Type
- 11. 3. USING EXPLAIN 3.3 What should I care about? Partitions: show which partitions were used.
- 12. 3. USING EXPLAIN 3.3 What should I care about? Extra • Using filesort • Using temporary • Using index • Using index for group-by • …
- 13. 3. USING EXPLAIN 3.3 What should I care about? Extra • Using filesort: MySQL must do an extra pass to find out how to retrieve the rows in sorted order. The sort is done by going through all rows according to the join type and storing the sort key and pointer to the row for all rows that match the WHERE clause. The keys then are sorted and the rows are retrieved in sorted order.
- 14. 3. USING EXPLAIN 3.3 What should I care about? Extra • Using temporary: To resolve the query, MySQL needs to create a temporary table to hold the result. This typically happens if the query contains GROUP BY and ORDER BY clauses that list columns differently.
- 15. 3. USING EXPLAIN 3.3 What should I care about? Extra • Using index: The column information is retrieved from the table using only information in the index tree without having to do an additional seek to read the actual row. This strategy can be used when the query uses only columns that are part of a single index.
- 16. 3. USING EXPLAIN 3.3 What should I care about? Extra • Using index for group-by: Similar to the Using index table access method, Using index for group-by indicates that MySQL found an index that can be used to retrieve all columns of a GROUP BY or DISTINCT query without any extra disk access to the actual table. Additionally, the index is used in the most efficient way so that for each group, only a few index entries are read.
- 17. 3. USING EXPLAIN 3.3 What should I care about? Type: describes how tables are joined. The following list describes the join types, ordered from the best type to the worst: • System • Const • Eq_ref • Ref • Fulltext
- 18. 3. USING EXPLAIN 3.3 What should I care about? Type: • Ref_or_null • Index_merge • Unique_subquery • Index_subquery • Range • Index • All
- 19. 4. OPTIMIZING SPECIFIC TYPES OF QUERIES 4.1 Count() • SELECT COUNT(*) FROM world.City WHERE ID > 5; • If you examine this query with SHOW STATUS, you’ll see that it scans 4,079 rows. If you negate the conditions and subtract the number of cities whose IDs are less than or equal to 5 from the total number of cities, you can reduce that to five rows: • SELECT (SELECT COUNT(*) FROM world.City) - COUNT(*) -> FROM world.City WHERE ID <= 5;
- 20. 4. OPTIMIZING SPECIFIC TYPES OF QUERIES 4.2 LIMIT and OFFSET • One simple technique to improve efficiency is to do the offset on a covering index, rather than the full rows. You can then join the result to the full row and retrieve the additional columns you need. This can be much more efficient. Consider the following query:
- 21. 4. OPTIMIZING SPECIFIC TYPES OF QUERIES 4.3 Group by • The most general way to satisfy a GROUP BY clause is to scan the whole table and create a new temporary table where all rows from each group are consecutive, and then use this temporary table to discover groups and apply aggregate functions (if any). In some cases, MySQL is able to do much better than that and to avoid creation of temporary tables by using index access.
- 22. 4. OPTIMIZING SPECIFIC TYPES OF QUERIES 4.3 Group by Loose Index Scan If loose index scan is applicable to a query, the EXPLAIN output shows Using index for group-by in the Extra column.
- 23. 4. OPTIMIZING SPECIFIC TYPES OF QUERIES 4.3 Group by Loose Index Scan Condition: • The query is over a single table. • The GROUP BY names only columns that form a leftmost prefix of the index and no other columns. (If, instead of GROUP BY, the query has a DISTINCT clause, all distinct attributes refer to columns that form a leftmost prefix of the index.) • The only aggregate functions used in the select list (if any) are MIN() and MAX(), and all of them refer to the same column. The column must be in the index and must immediately follow the columns in the GROUP BY.
- 24. 4. OPTIMIZING SPECIFIC TYPES OF QUERIES 4.3 Group by Loose Index Scan Condition: • Any other parts of the index than those from the GROUP BY referenced in the query must be constants (that is, they must be referenced in equalities with constants), except for the argument of MIN() or MAX() functions. • For columns in the index, full column values must be indexed, not just a prefix. For example, with c1 VARCHAR(20), INDEX (c1(10)), the index cannot be used for loose index scan.
- 25. 4. OPTIMIZING SPECIFIC TYPES OF QUERIES 4.3 Group by Loose Index Scan Example: index(c1, c2, c3)
- 26. 4. OPTIMIZING SPECIFIC TYPES OF QUERIES 4.3 Group by Loose Index Scan
- 27. 4. OPTIMIZING SPECIFIC TYPES OF QUERIES 4.3 Group by Tight Index Scan
- 28. 4. OPTIMIZING SPECIFIC TYPES OF QUERIES 4.3 UNION • UNION ALL is much faster than UNION • Move the WHERE inside each subquery Example: • Slow: (SELECT type, release FROM short_sleeve) UNION (SELECT type, release FROM long_sleeve); WHERE release >=2013; • Fast: (SELECT type, release FROM short_sleeve WHERE release >=2013) UNION (SELECT type, release FROM long_sleeve WHERE release >=2013);
- 29. 5. INDEXING 5.1 B-Tree • When people talk about an index without mentioning a type, they’re probably referring to a B-Tree index • A B-Tree index speeds up data access because the storage engine doesn’t have to scan the whole table to find the desired data. Instead, it starts at the root node (not shown in this figure).
- 31. 5. INDEXING 5.1 B-Tree • Consider InnoDB whose page size is 16KB and suppose we have an index on a integer column of size 4bytes, so a node can contain at most 16 * 1024 / 4 = 4096 keys, and a node can have at most 4097 children. • So for a B+tree of height 1, the root node has 4096 keys and the nodes at height 1 (the leaf nodes) have 4096 * 4097 = 16781312 key values.
- 33. 5. INDEXING 5.1 B-Tree Benefits: • Match the full value: find a person named Cuba Allen who was born on 1960-01-01. • Match a leftmost prefix: find all people with the last name Allen • Match a column prefix: all people whose last names begin with J • Match a range of values: find people whose last names are between Allen and Barrymore • Match one part exactly and match a range on another part: find everyone whose last name is Allen and whose first name starts with the letter K (Kim, Karl, etc.)
- 34. 5. INDEXING 5.1 B-Tree Limits: • They are not useful if the lookup does not start from the leftmost side of the indexed columns. • You can’t skip columns in the index.
- 35. 5. INDEXING 5.2 Hash indexes A hash index is built on a hash table and is useful only for exact lookups that use every column in the index. For each row, the storage engine computes a hash code of the indexed columns, which is a small value that will probably differ from the hash codes computed for other rows with different key values. It stores the hash codes in the index and stores a pointer to each row in a hash table.
- 36. 5. INDEXING 5.2 Hash indexes
- 37. 5. INDEXING 5.2 Hash indexes Limits: • MySQL can’t use the values in the index to avoid reading the rows • can’t use hash indexes for sorting • don’t support partial key matching • support only equality comparisons that use the =, IN(), and <=> operators • When there are collisions (multiple values with the same hash): slow
- 38. 5. INDEXING 5.3 Indexing Strategies for High Performance Isolating the Column • MySQL generally can’t use indexes on columns unless the columns are isolated in the query. “Isolating” the column means it should not be part of an expression or be inside a function in the query. SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5; • Here’s another example of a common mistake: mysql> SELECT ... WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(date_col) <= 10;
- 39. 5. INDEXING 5.3 Indexing Strategies for High Performance Prefix Indexes and Index Selectivity • Sometimes you need to index very long character columns, which makes your indexes large and slow. The trick is to choose a prefix that’s long enough to give good selectivity, but short enough to save space.
- 40. 5. INDEXING 5.3 Indexing Strategies for High Performance Choosing a Good Column Order • place the most selective columns first in the index. • Let’s use the following query as an example: SELECT * FROM payment WHERE staff_id = 2 AND customer_id = 584; • index on (staff_id, customer_id) OR (customer_id , staff_id) ???
- 41. 5. INDEXING 5.3 Indexing Strategies for High Performance Choosing a Good Column Order
- 42. 5. INDEXING 5.3 Indexing Strategies for High Performance Covering Indexes • MySQL can also use an index to retrieve a column’s data, so it doesn’t have to read the row at all. After all, the index’s leaf nodes contain the values they index; • MySQL can use only B-Tree indexes to cover queries. • The general rule is to choose the columns for filtering first (WHERE clause with equality conditions), then sorting/grouping (GROUP BY and ORDER BY clauses) and finally the data projection (SELECT clause).
- 43. 5. INDEXING 5.3 Indexing Strategies for High Performance Covering Indexes
- 44. 5. INDEXING 5.3 Indexing Strategies for High Performance Using Index Scans for Sorts MySQL has two ways to produce ordered results: it can use a sort operation, or it can scan an index in order. You can tell when MySQL plans to scan an index by looking for “index” in the type column in EXPLAIN.
- 45. 5. INDEXING 5.3 Indexing Strategies for High Performance Using Index Scans for Sorts Index on (rental_date, inventory_id, Customer_id)
- 46. 5. INDEXING 5.3 Indexing Strategies for High Performance Using Index Scans for Sorts Index on (rental_date, inventory_id, customer_id)
- 47. 5. INDEXING 5.3 Indexing Strategies for High Performance Using Index Scans for Sorts Index on (rental_date, inventory_id, Customer_id)
- 48. 6. PARTITIONING 6.1 scenarios: • When the table is much too big to fit in memory, or when you have “hot” rows at the end of a table that has lots of historical data. • Partitioned data is easier to maintain than nonpartitioned data. For example, it’s easier to discard old data by dropping an entire partition, which you can do quickly. You can also optimize, check, and repair individual partitions. • If you really need to, you can back up and restore individual partitions, which is very helpful with extremely large datasets.
- 49. 6. PARTITIONING 6.2 How Partitioning Works: When you query a partitioned table, the partitioning layer opens and locks all of the underlying partitions, the query optimizer determines whether any of the partitions can be ignored (pruned), and then the partitioning layer forwards the handler API calls to the storage engine that manages the partitions.
- 50. 6. PARTITIONING 6.3 Types of Partitioning: • MySQL supports several types of partitioning. The most common type we’ve seen used is range partitioning.
Editor's Notes
- #9: https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
- #13: https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain-extra-information
- #14: https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain-extra-information
- #15: https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain-extra-information
- #16: https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain-extra-information
- #17: https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain-extra-information
- #18: https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain-join-types
- #21: This “deferred join” works because it lets the server examine as little data as possible in an index without accessing rows, and then, once the desired rows are found, join them against the full table to retrieve the other columns from the row.
- #29: https://www.iheavy.com/2013/06/13/how-to-optimize-mysql-union-for-high-speed/
- #31: https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html http://www.ovaistariq.net/733/understanding-btree-indexes-and-how-they-impact-performance/#.WsMCtIhuaUk
- #40: http://code-epicenter.com/prefixed-index-in-mysql-database/
- #43: https://community.toadworld.com/platforms/mysql/b/weblog/archive/2017/04/06/speed-up-your-queries-using-the-covering-index-in-mysql
- #45: If MySQL isn’t using the index to cover the query, it will have to look up each row it finds in the index. This is basically random I/O, so reading data in index order is usually much slower than a sequential table scan, especially for I/Obound workloads.
- #46: Ordering the results by the index works only when the index’s order is exactly the same as the ORDER BY clause and all columns are sorted in the same direction (ascending or descending).12 If the query joins multiple tables, it works only when all columns in the ORDER BY clause refer to the first table. The ORDER BY clause also has the same limitation as lookup queries: it needs to form a leftmost prefix of the index. In all other cases, MySQL uses a sort.