
















![Execute program
Fetch/
Decode
Execution
Context
ld r0, addr[r1]
mul r1, r0, r0
mul r1, r1, r0
...
...
...
...
...
...
st addr[r2], r0
Execution Unit
(ALU)
My very simple processor: executes one instruction per clock](https://image.slidesharecdn.com/01lecture-250403075021-4ccc798c/85/Parallel-and-Distributed-computing-why-parallellismpdf-18-320.jpg)
![Execute program
Fetch/
Decode
Execution
Context
ld r0, addr[r1]
mul r1, r0, r0
mul r1, r1, r0
...
...
...
...
...
...
st addr[r2], r0
Execution Unit
(ALU)
My very simple processor: executes one instruction per clock](https://image.slidesharecdn.com/01lecture-250403075021-4ccc798c/85/Parallel-and-Distributed-computing-why-parallellismpdf-19-320.jpg)
![Execute program
Fetch/
Decode
Execution
Context
Execution Unit
(ALU)
ld r0, addr[r1]
mul r1, r0, r0
mul r1, r1, r0
...
...
...
...
...
...
st addr[r2], r0
My very simple processor: executes one instruction per clock](https://image.slidesharecdn.com/01lecture-250403075021-4ccc798c/85/Parallel-and-Distributed-computing-why-parallellismpdf-20-320.jpg)
![Execute program
Fetch/
Decode
Execution
Context
ld r0, addr[r1]
mul r1, r0, r0
mul r1, r1, r0
...
...
...
...
...
...
st addr[r2], r0
Execution Unit
(ALU)
My very simple processor: executes one instruction per clock](https://image.slidesharecdn.com/01lecture-250403075021-4ccc798c/85/Parallel-and-Distributed-computing-why-parallellismpdf-21-320.jpg)




































![Load: an instruction for accessing the contents of memory
Fetch/
Decode
Execution
Context
ALU
(Execution Unit)
Professor Kayvon’s
Very Simple Processor
ld R0 ← mem[R2]
“Pleaseloadthefour-bytevalueinmemorystartingfromthe
addressstoredbyregisterR2andputthisvalueintoregisterR0.”
R0: 96
R1: 64
R2: 0xff681080
R3: 0x80486412
Memory
0xff681080: 42
0xff681084: 32
0xff681088: 0
0xff68107c: 1024
...
...](https://image.slidesharecdn.com/01lecture-250403075021-4ccc798c/85/Parallel-and-Distributed-computing-why-parallellismpdf-59-320.jpg)

![Stalls
▪ A processor“stalls” (can’t make progress) when it cannot run the next instruction in an
instruction stream because future instructions depend on a previous instruction that is
not yet complete.
▪ Accessing memory is a major source of stalls
ld r0 mem[r2]
ld r1 mem[r3]
add r0, r0, r1
▪ Memory access times ~ 100’s of cycles
- Memory“access time”is a measure of latency
Dependency: cannot execute‘add’instruction until data from
mem[r2] and mem[r3] have been loaded from memory](https://image.slidesharecdn.com/01lecture-250403075021-4ccc798c/85/Parallel-and-Distributed-computing-why-parallellismpdf-61-320.jpg)







![Data movement has high energy cost
▪ Rule of thumb in modern system design: always seek to reduce amount of data movement in a computer
▪ “Ballpark”numbers
- Integer op: ~ 1 pJ *
- Floating point op: ~20 pJ *
- Reading 64 bits from small local SRAM (1mm away on chip): ~ 26 pJ
- Reading 64 bits from low power mobile DRAM (LPDDR): ~1200 pJ
▪ Implications
- Reading 10 GB/sec from memory: ~1.6 watts
- Entire power budget for mobile GPU: ~1 watt
(remember phone is also running CPU, display, radios, etc.)
- iPhone 6 battery: ~7 watt-hours (note: my Macbook Pro laptop: 99 watt-hour battery)
- Exploiting locality matters!!!
* Cost to just perform the logical operation, not counting overhead of instruction decode, load data from registers, etc.
[Sources: Bill Dally (NVIDIA),Tom Olson (ARM)]](https://image.slidesharecdn.com/01lecture-250403075021-4ccc798c/85/Parallel-and-Distributed-computing-why-parallellismpdf-70-320.jpg)

Parallel and Distributed computing: why parallellismpdf
- 1. Why Parallelism? Why Efficiency? Lecture 1: Parallel and Distributed Computing
- 2. One common definition A parallel computer is a collection of processing elements that cooperate to solve problems quickly We care about performance, and we care about efficiency We’re going to use multiple processing elements to get it
- 3. Speedup One major motivation of using parallel processing: achieve a speedup For a given problem: speedup( using P processors ) = execution time (using 1 processor) execution time (using P processors)
- 4. Course theme 1: Designing and writing parallel programs ... that scale! ▪ Parallel thinking 1. Decomposing work into pieces that can safely be performed in parallel 2. Assigning work to processors 3. Managing communication/synchronization between the processors so that it does not limit speedup ▪ Abstractions/mechanisms for performing the above tasks - Writing code in popular parallel programming languages
- 5. Course theme 2: Parallel computer hardware implementation: how parallel computers work ▪ Mechanisms used to implement abstractions efficiently - Performance characteristics of implementations - Design trade-offs: performance vs. convenience vs. cost ▪ Why do I need to know about hardware? - Because the characteristics of the machine really matter (recall speed of communication issues in earlier demos) - Because you care about efficiency and performance (you are writing parallel programs after all!)
- 6. Course theme 3: Thinking about efficiency ▪ FAST != EFFICIENT ▪ Just because your program runs faster on a parallel computer, it does not mean it is using the hardware efficiently - Is 2x speedup on computer with 10 processors a good result? ▪ Programmer’s perspective: make use of provided machine capabilities ▪ HW designer’s perspective: choosing the right capabilities to put in system (performance/cost, cost = silicon area?, power?, etc.)
- 8. Some historical context: why avoid parallel processing? Year Relative CPU Performance Image credit: Olukutun and Hammond, ACM Queue 2005 ▪ Single-threaded CPU performance doubling ~ every 18 months ▪ Implication: working to parallelize your code was often not worth the time - Software developer does nothing, code gets faster next year.Woot!
- 9. Until ~15 years ago: two significant reasons for processor performance improvement 1. Exploiting instruction-level parallelism (superscalar execution) 2. Increasing CPU clock frequency
- 10. What is a computer program?
- 11. Here is a program written in C int main(int argc, char** argv) { int x = 1; for (int i=0; i<10; i++) { x = x + x; } printf(“%dn”, x); return 0; }
- 12. What is a program? (from a processor’s perspective) int main(int argc, char** argv) { int x = 1; for (int i=0; i<10; i++) { x = x + x; } printf(“%dn”, x); return 0; } Compile code _main: 100000f10: pushq %rbp 100000f11: movq %rsp, %rbp 100000f14: subq $32, %rsp 100000f18: movl $0, -4(%rbp) 100000f1f: movl %edi, -8(%rbp) 100000f22: movq %rsi, -16(%rbp) 100000f26: movl $1, -20(%rbp) 100000f2d: movl $0, -24(%rbp) 100000f34: cmpl $10, -24(%rbp) 100000f38: jge 23 <_main+0x45> 100000f3e: movl -20(%rbp), %eax 100000f41: addl -20(%rbp), %eax 100000f44: movl %eax, -20(%rbp) 100000f47: movl -24(%rbp), %eax 100000f4a: addl $1, %eax 100000f4d: movl %eax, -24(%rbp) 100000f50: jmp -33 <_main+0x24> 100000f55: leaq 58(%rip), %rdi 100000f5c: movl -20(%rbp), %esi 100000f5f: movb $0, %al 100000f61: callq 14 100000f66: xorl %esi, %esi 100000f68: movl %eax, -28(%rbp) 100000f6b: movl %esi, %eax 100000f6d: addq $32, %rsp 100000f71: popq %rbp 100000f72: rets A program is just a list of processor instructions!
- 13. Stanford CS149, Fall 2024 Kind of like the instructions in a recipe for your favorite meals Mmm, carne asada
- 14. What does a processor do?
- 15. A processor executes instructions Execution Context ALU (Execution Unit) Professor Kayvon’s Very Simple Processor Registers: maintain program state: store value of variables used as inputs and outputs to operations Execution unit: performs the operation described by an instruction, which may modify values in the processor’s registers or the computer’s memory Register 0 (R0) Register 1 (R1) Register 2 (R2) Register 3 (R3) Fetch/ Decode Determine what instruction to run next
- 16. One example instruction: add two numbers Execution Context Professor Kayvon’s Very Simple Processor Step 1: Processor gets next program instruction from memory (figure out what the processor should do next) add R0 ← R0, R1 “PleaseaddthecontentsofregisterR0tothecontentsof registerR1andputtheresultoftheadditionintoregisterR0” R0: 32 R1: 64 R2: 0xff681080 R3: 0x80486412 Contents of R0 input to execution unit: Contents of R1 input to execution unit: Execution unit performs arithmetic, the result is: 32 64 96 Step 2: Get operation inputs from registers Step 3: Perform addition operation: ALU (Execution Unit) Fetch/ Decode
- 17. One example instruction: add two numbers Execution Context Professor Kayvon’s Very Simple Processor Step 1: Processor gets next program instruction from memory (figure out what the processor should do next) add R0 ← R0, R1 “PleaseaddthecontentsofregisterR0tothecontentsof registerR1andputtheresultoftheadditionintoregisterR0” R0: 96 R1: 64 R2: 0xff681080 R3: 0x80486412 ALU (Execution Unit) Fetch/ Decode Step 4: Store result back to register R0 Contents of R0 input to execution unit: Contents of R1 input to execution unit: Execution unit performs arithmetic, the result is: 32 64 96 Step 2: Get operation inputs from registers Step 3: Perform addition operation: 96
- 18. Execute program Fetch/ Decode Execution Context ld r0, addr[r1] mul r1, r0, r0 mul r1, r1, r0 ... ... ... ... ... ... st addr[r2], r0 Execution Unit (ALU) My very simple processor: executes one instruction per clock
- 19. Execute program Fetch/ Decode Execution Context ld r0, addr[r1] mul r1, r0, r0 mul r1, r1, r0 ... ... ... ... ... ... st addr[r2], r0 Execution Unit (ALU) My very simple processor: executes one instruction per clock
- 20. Execute program Fetch/ Decode Execution Context Execution Unit (ALU) ld r0, addr[r1] mul r1, r0, r0 mul r1, r1, r0 ... ... ... ... ... ... st addr[r2], r0 My very simple processor: executes one instruction per clock
- 21. Execute program Fetch/ Decode Execution Context ld r0, addr[r1] mul r1, r0, r0 mul r1, r1, r0 ... ... ... ... ... ... st addr[r2], r0 Execution Unit (ALU) My very simple processor: executes one instruction per clock
- 22. Review of how computers work… What is a computer program? (from a processor’s perspective) Itisalistofinstructionstoexecute! What is an instruction? Itdescribesanoperationforaprocessortoperform. Executinganinstructiontypicallymodifiesthecomputer’sstate. What do I mean when I talk about a computer’s“state”? Thevaluesofprogramdata,whicharestoredinaprocessor’sregistersorinmemory.
- 23. Lets consider a very simple piece of code a = x*x + y*y + z*z Assume register R0 = x, R1 = y, R2 = z mul R0, R0, R0 mul R1, R1, R1 mul R2, R2, R2 add R0, R0, R1 add R3, R0, R2 R3 now stores value of program variable ‘a’ Consider the following five instruction program: This program has five instructions, so it will take five clocks to execute, correct? Can we do better? 1 2 3 4 5
- 24. What if up to two instructions can be performed at once? a = x*x + y*y + z*z Assume register R0 = x, R1 = y, R2 = z mul R0, R0, R0 mul R1, R1, R1 mul R2, R2, R2 add R0, R0, R1 add R3, R0, R2 R3 now stores value of program variable ‘a’ 1 2 3 4 5 Processor 1 Processor 2 1 2 3 4 5 time 1. mul R0, R0, R0 2. mul R1, R1, R1 3. mul R2, R2, R2 4. add R0, R0, R1 5. add R3, R0, R2
- 25. What if up to two instructions can be performed at once? a = x*x + y*y + z*z Assume register R0 = x, R1 = y, R2 = z mul R0, R0, R0 mul R1, R1, R1 mul R2, R2, R2 add R0, R0, R1 add R3, R0, R2 R3 now stores value of program variable ‘a’ 1 2 3 4 5 Processor 1 Processor 2 1 2 3 4 5 time 1. mul R0, R0, R0 2. mul R1, R1, R1 3. mul R2, R2, R2 4. add R0, R0, R1 5. add R3, R0, R2
- 26. QUESTION: What does it mean for our parallel to scheduling to that“respects program order”? Hint:What is expected of the output.
- 27. What about three instructions at once? a = x*x + y*y + z*z 1 2 3 4 5 time 1 2 3 4 5 Assume register R0 = x, R1 = y, R2 = z mul R0, R0, R0 mul R1, R1, R1 mul R2, R2, R2 add R0, R0, R1 add R3, R0, R2 R3 now stores value of program variable ‘a’ Processor 1 Processor 2 Processor 3
- 28. What about three instructions at once? a = x*x + y*y + z*z 1 2 3 4 5 time 1 2 3 4 5 Assume register R0 = x, R1 = y, R2 = z mul R0, R0, R0 mul R1, R1, R1 mul R2, R2, R2 add R0, R0, R1 add R3, R0, R2 R3 now stores value of program variable ‘a’ Processor 1 Processor 2 Processor 3 1. mul R0, R0, R0 2. mul R1, R1, R1 3. mul R2, R2, R2 4. add R0, R0, R1 5. add R3, R0, R2
- 29. Instruction level parallelism (ILP) example ▪ ILP = 3 a = x*x + y*y + z*z x + a + ILP = 3 ILP = 1 ILP = 1 x * y y * z z *
- 30. Superscalar processor execution a = x*x + y*y + z*z Idea #1: Superscalar execution: processor automatically finds* independent instructions in an instruction sequence and executes them in parallel on multiple execution units! In this example: instructions 1, 2, and 3 can be executed in parallel without impacting program correctness (on a superscalar processor that determines that the lack of dependencies exists) But instruction 4 must be executed after instructions 1 and 2 And instruction 5 must be executed after instruction 4 Assume register R0 = x, R1 = y, R2 = z mul R0, R0, R0 mul R1, R1, R1 mul R2, R2, R2 add R0, R0, R1 add R3, R0, R2 1 2 3 4 5 * Or the compiler finds independent instructions at compile time and explicitly encodes dependencies in the compiled binary.
- 31. Superscalar processor Fetch/ Decode 1 Execution Context Exec 1 This processor can decode and execute up to two instructions per clock Fetch/ Decode 2 Exec 2 Out-of-order control logic
- 32. Aside: Old Intel Pentium 4 CPU Image credit: http://ixbtlabs.com/articles/pentium4/index.html
- 33. A more complex example a = 2 b = 4 tmp2 = a + b // 6 tmp3 = tmp2 + a // 8 tmp4 = b + b // 8 tmp5 = b * b // 16 tmp6 = tmp2 + tmp4 // 14 tmp7 = tmp5 + tmp6 // 30 if (tmp3 > 7) print tmp3 else print tmp7 00 01 02 03 04 05 06 07 08 09 10 PC Instruction Instruction dependency graph Program (sequence of instructions) 00 01 02 03 04 06 08 09 10 05 07 Computedvalue
- 34. Diminishing returns of superscalar execution 0 1 2 3 0 4 8 12 16 Instruction issue capability of processor (instructions/clock) Speedup Most available ILP is exploited by a processor capable of issuing four instructions per clock (Little performance benefit from building a processor that can issue more) Source: Culler & Singh (data from Johnson 1991)
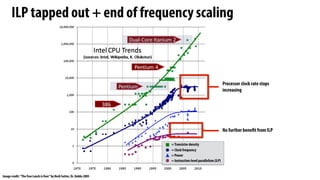
- 36. ILP tapped out + end of frequency scaling No further benefit from ILP Processor clock rate stops increasing Image credit:“The free Lunch is Over”by Herb Sutter, Dr. Dobbs 2005 =Transistor density = Clock frequency = Instruction-level parallelism (ILP) = Power
- 37. The“power wall” Dynamic power capacitive load × voltage2 × frequency Static power: transistors burn power even when inactive due to leakage Power consumed by a transistor: High power = high heat Power is a critical design constraint in modern processors Intel Core i9 10900K (in desktop CPU): 95W Apple M1 laptop: 13W NVIDIA RTX 4090 GPU 450W TDP Standard microwave oven 900W Mobile phone processor 1/2 - 2W World’s fastest supercomputer megawatts Source: Intel, NVIDIA,Wikipedia,Top500.org ∝
- 38. Power draw as a function of clock frequency Dynamic power capacitive load × voltage2 × frequency Static power: transistors burn power even when inactive due to leakage Maximum allowed frequency determined by processor’s core voltage ∝ Image credit:“Idontcare”: posted at: http://forums.anandtech.com/showthread.php?t=2281195
- 39. Single-core performance scaling The rate of single-instruction stream performance scaling has decreased (almost to zero) 1. Frequency scaling limited by power 2. ILP scaling tapped out Architects are now building faster processors by adding more execution units that run in parallel (Or units that are specialized for a specific task: like graphics, or audio/video playback) Software must be written to be parallel to see performance gains. No more free lunch for software developers! Image credit:“The free Lunch is Over”by Herb Sutter, Dr. Dobbs 2005 =Transistor density = Clock frequency = ILP = Power
- 40. Example: multi-core CPU Intel“Comet Lake”10th Generation Core i9 10-core CPU (2020) Core 1 Core 4 Core 2 Core 3 Core 6 Core 9 Core 7 Core 8 Core 5 Core 10
- 41. ▪ Example: assignment 1 (coming up!) - Running on a quad-core Intel CPU - Four CPU cores - AVX SIMD vector instructions + hyper-threading - Baseline: single-threaded C program compiled with -O3 - Parallelized program that uses all parallel execution resources on this CPU… One thing you will learn in this course ▪ How to write code that efficiently uses the resources in a modern multi-core CPU ~32-40x faster! We’ll talk about these terms next time!
- 42. AMD RyzenThreadripper 3990X 64 cores, 4.3 GHz Four 8-core chiplets
- 43. NVIDIA AD102 GPU 18,432 fp32 multipliers organized in 144 processing blocks (called SMs) GeForce RTX 4090 (2022) 76 billion transistors
- 44. Stanford CS149, Fall 2024 GPU-accelerated supercomputing Frontier (at Oak Ridge National Lab) (world’s #1 in Fall 2022) 9472 x 64 core AMD CPUs (606,208 CPU cores) 37,888 Radeon GPUs 21 Megawatts
- 45. Image Credit:TechInsights Inc. Apple A15 Bionic (in iPhone 13, 14) Mobile parallel processing Power constraints also heavily influence the design of mobile systems 15 billion transistors 6-core CPU Multi-core GPU 4“small”CPU cores 2“big”CPU cores 5 GPU blocks
- 46. Mobile parallel processing Raspberry Pi 3 Quad-core ARM A53 CPU
- 47. But in modern computing software must be more than just parallel… IT MUST ALSO BE EFFICIENT
- 48. Q.What is a big concern in mobile computing? all
- 49. A. Power
- 50. Two reasons to save power Run at higherperformance for a fixed amount of time. Run at sufficientperformance for a longer amount of time. Power = heat If a chip gets too hot, it must be clocked down to cool off * Power = battery Long battery life is a desirable feature in mobile devices * Another reason: hotter systems cost more to cool.
- 51. Mobile phone example 3227 mAmp hours (12.4Watt hours) Apple iPhone 13
- 52. Image Credit:TechInsights Inc. Apple A15 Bionic (in iPhone 13, 14) 6-core GPU 2“big”CPU cores 4“small”CPU cores Apple-designed multi-core GPU Neural Engine (NPU) for DNN acceleration + Image/video encode/decode processor + Motion (sensor) processor Specialized processing is ubiquitous in mobile systems 15 billion transistors
- 53. Parallel + specialized HW ▪ Achieving high efficiency will be a key theme in this class ▪ We will discuss how modern systems not only use many processing units, but also utilize specialized processing units to achieve high levels of power efficiency
- 54. Stanford CS149, Fall 2024 Specialization for datacenter-scale applications GoogleTPU pods Image Credit:TechInsights Inc. TPU =Tensor Processing Unit: specialized processor for ML computations
- 55. Specialized hardware to accelerate DNN inference/training GoogleTPU3 Huawei Kirin NPU Apple Neural Engine GraphCore IPU Ampere GPU with Tensor Cores CerebrasWafer Scale Engine SambaNova Cardinal SN10 AWSTrainium
- 56. Achieving efficient processing almost always comes down to accessing data efficiently.
- 58. A program’s memory address space ▪ A computer’s memory is organized as an array of bytes ▪ Each byte is identified by its“address”in memory (its position in this array) (We’ll assume memory is byte-addressable) “Thebytestoredataddress0x10(16)hasthevalue128.” “Thebytestoredataddress0x8hasthevalue32.” Address Value 0x0 0x1 0x2 0x3 0x4 0x5 0x6 0x7 0x8 0x9 0xA 0xB 0xC 0xD 0xE 0xF 0x10 16 255 14 0 128 0 0 0 6 32 48 255 255 255 0 0 0 0x1F . . . . . . 0 In the illustration on the right, the program’s memory address space is 32 bytes in size (so valid addresses range from 0x0 to 0x1F)
- 59. Load: an instruction for accessing the contents of memory Fetch/ Decode Execution Context ALU (Execution Unit) Professor Kayvon’s Very Simple Processor ld R0 ← mem[R2] “Pleaseloadthefour-bytevalueinmemorystartingfromthe addressstoredbyregisterR2andputthisvalueintoregisterR0.” R0: 96 R1: 64 R2: 0xff681080 R3: 0x80486412 Memory 0xff681080: 42 0xff681084: 32 0xff681088: 0 0xff68107c: 1024 ... ...
- 60. Terminology ▪ Memory access latency - The amount of time it takes the memory system to provide data to the processor - Example: 100 clock cycles, 100 nsec Memory Data request Latency ~ 2 sec
- 61. Stalls ▪ A processor“stalls” (can’t make progress) when it cannot run the next instruction in an instruction stream because future instructions depend on a previous instruction that is not yet complete. ▪ Accessing memory is a major source of stalls ld r0 mem[r2] ld r1 mem[r3] add r0, r0, r1 ▪ Memory access times ~ 100’s of cycles - Memory“access time”is a measure of latency Dependency: cannot execute‘add’instruction until data from mem[r2] and mem[r3] have been loaded from memory
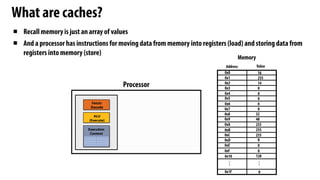
- 62. What are caches? Memory Address Value 0x0 0x1 0x2 0x3 0x4 0x5 0x6 0x7 0x8 0x9 0xA 0xB 0xC 0xD 0xE 0xF 0x10 16 255 14 0 128 0 0 0 6 32 48 255 255 255 0 0 0 0x1F . . . . . . 0 Fetch/ Decode Execution Context ALU (Execute) Processor ▪ Recall memory is just an array of values ▪ And a processor has instructions for moving data from memory into registers (load) and storing data from registers into memory (store)
- 63. What are caches? Implementation of memory abstraction ▪ A cache is a hardware implementation detail that does not impact the output of a program, only its performance ▪ Cache is on-chip storage that maintains a copy of a subset of the values in memory ▪ If an address is stored“in the cache”the processor can load/store to this address more quickly than if the data resides only in DRAM Address Value 0x0 0x1 0x2 0x3 0x4 0x5 0x6 0x7 0x8 0x9 0xA 0xB 0xC 0xD 0xE 0xF 0x10 16 255 14 0 128 0 0 0 6 32 48 255 255 255 0 0 0 0x1F . . . . . . 0 Data Cache Line Address Values in line 0x4 0 0 6 0 0xC 255 0 0 0 Fetch/ Decode Execution Context ALU (Execute) Processor ▪ Caches operate at the granularity of“cache lines”. In the figure, the cache: - Has a capacity of 2 lines - Each line holds 4 bytes of data DRAM
- 64. How does a processor decide what data to keep in cache? ▪ Outside the scope of this course, but I suggest googling these terms… - Direct mapped cache - Set-associative cache - Cache line ▪ For now, just assume that the cache of size N bytes stores values for the last N addresses accessed - LRU replacement policy (“least recently used”) - to make room for new data, throw out the data in the cache that was accessed the longest time ago
- 65. Cache example 1 Assume: Total cache capacity of 8 bytes Cache with 4-byte cache lines (So 2 lines fit in cache) Least recently used (LRU) replacement policy 0x0 Address accessed Cache state (after load is complete) Address Value 0x0 0x1 0x2 0x3 0x4 0x5 0x6 0x7 0x8 0x9 0xA 0xB 0xC 0xD 0xE 0xF 16 255 14 0 0 0 0 6 32 48 255 255 255 0 0 0 Array of 16 bytes in memory 0x1 0x2 0x3 0x2 0x1 time 0x0 “cold miss”, load 0x0 0x0 hit 0x0 hit 0x0 hit Cache action Line 0x0 Line 0x4 Line 0x8 Line 0xC 0x0 hit 0x0 hit 0x4 0x0 0x4 “cold miss”, load 0x4 0x1 0x0 0x4 hit There are two forms of“data locality”in this sequence: Spatial locality: loading data in a cache line“preloads”the data needed for subsequent accesses to different addresses in the same line, leading to cache hits Temporal locality: repeated accesses to the same address result in hits.
- 66. Cache example 2 Assume: Total cache capacity of 8 bytes Cache with 4-byte cache lines (So 2 lines fit in cache) Least recently used (LRU) replacement policy 0x0 Address accessed Cache state (after load is complete) Address Value 0x0 0x1 0x2 0x3 0x4 0x5 0x6 0x7 0x8 0x9 0xA 0xB 0xC 0xD 0xE 0xF 16 255 14 0 0 0 0 6 32 48 255 255 255 0 0 0 Array of 16 bytes in memory 0x1 0x2 0x3 0x4 0x5 0x6 0x7 0x8 0x9 0xA 0xB 0xC 0xD 0xE 0xF 0x0 time 0x0 “cold miss”, load 0x0 0x0 hit 0x0 hit 0x0 hit 0x0 0x4 “cold miss”, load 0x4 0x0 0x4 hit 0x0 0x4 hit 0x0 0x4 hit 0x4 0x8 “cold miss”, load 0x8 (evict 0x0) 0x4 0x8 hit 0x4 0x8 hit 0x4 0x8 hit 0x8 0xC “cold miss”, load 0xC (evict 0x4) 0x8 0xC hit 0x8 0xC hit 0x8 0xC hit 0xC 0x0 “capacity miss”, load 0x0 (evict 0x8) Cache action Line 0x0 Line 0x4 Line 0x8 Line 0xC
- 67. Caches reduce length of stalls (reduce memory access latency) ▪ Processors run efficiently when they access data that is resident in caches ▪ Caches reduce memory access latency when processors accesses data that they have recently accessed! * * Caches also provide high bandwidth data transfer
- 68. The implementation of the linear memory address space abstraction on a modern computer is complex DRAM (64 GB) L3 cache (20 MB) L1 cache (32 KB) L2 cache (256 KB) Processor The instruction“load the value stored at address X into register R0”might involve a complex sequence of operations by multiple data caches and access to DRAM Common organization: hierarchy of caches: Level 1 (L1), level 2 (L2), level 3 (L3) Smaller capacity caches near processor →lower latency Larger capacity caches farther away →larger latency
- 69. Data access times Data in L1 cache Data in L2 cache Data in L3 cache Data in DRAM (best case) 4 12 38 ~248 Latency (number of cycles at 4 GHz) (Kaby Lake CPU)
- 70. Data movement has high energy cost ▪ Rule of thumb in modern system design: always seek to reduce amount of data movement in a computer ▪ “Ballpark”numbers - Integer op: ~ 1 pJ * - Floating point op: ~20 pJ * - Reading 64 bits from small local SRAM (1mm away on chip): ~ 26 pJ - Reading 64 bits from low power mobile DRAM (LPDDR): ~1200 pJ ▪ Implications - Reading 10 GB/sec from memory: ~1.6 watts - Entire power budget for mobile GPU: ~1 watt (remember phone is also running CPU, display, radios, etc.) - iPhone 6 battery: ~7 watt-hours (note: my Macbook Pro laptop: 99 watt-hour battery) - Exploiting locality matters!!! * Cost to just perform the logical operation, not counting overhead of instruction decode, load data from registers, etc. [Sources: Bill Dally (NVIDIA),Tom Olson (ARM)]
- 71. Summary ▪ Today, single-thread-of-control performance is improving very slowly - To run programs significantly faster, programs must utilize multiple processing elements or specialized processing hardware - Which means you need to know how to reason about and write parallel and efficient code ▪ Writing parallel programs can be challenging - Requires problem partitioning, communication, synchronization - Knowledge of machine characteristics is important - In particular, understanding data movement! ▪ I suspect you will find that modern computers have tremendously more processing power than you might realize, if you just use it efficiently!