Parallelization Stategies of DeepLearning Neural Network Training
1 like907 views

The document discusses strategies for parallelizing large-scale deep learning neural networks on distributed systems like Apache Spark. It describes four main types of parallelization: inter-model parallelism by exploring different hyperparameter models in parallel; data parallelism by distributing data across identical models and averaging parameters; intra-model parallelism by partitioning layers of a single large model; and pipelined parallelism by processing samples in an assembly line fashion through layers. The strategies aim to speed up model training by leveraging multiple computing resources.






























































Parallelization Stategies of DeepLearning Neural Network Training
- 1. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler Building Brains - Parallelisation Strategies of Large- Scale Deep Learning Neural Networks on Parallel Scale Out Architectures Like Apache Spark Romeo Kienzler, IBM Watson IoT
- 2. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler
- 3. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler
- 4. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler
- 5. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler
- 6. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler the forward pass
- 7. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler back propagation
- 8. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler back propagation
- 9. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler gradient descent
- 10. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler gradient descent
- 11. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler gradient descent
- 12. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler gradient descent
- 13. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler gradient descent
- 14. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler gradient descent
- 15. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler ‣inter-model parallelism ‣data parallelism ‣intra-model parallelism ‣pipelined parallelism parallelisation
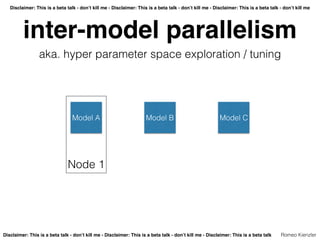
- 16. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler inter-model parallelism aka. hyper parameter space exploration / tuning Model A
- 17. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler inter-model parallelism aka. hyper parameter space exploration / tuning Model A Model B
- 18. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler inter-model parallelism aka. hyper parameter space exploration / tuning Model A Model B Model C
- 19. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler inter-model parallelism aka. hyper parameter space exploration / tuning Model A Model B Model C Node 1
- 20. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler inter-model parallelism aka. hyper parameter space exploration / tuning Model A Model B Model C Node 1 Node 2
- 21. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler inter-model parallelism aka. hyper parameter space exploration / tuning Model A Model B Model C Node 1 Node 2 Node 3
- 22. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler inter-model parallelism aka. hyper parameter space exploration / tuning Model A Model B Model C Node 1 Node 2 Node 3
- 23. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler data parallelism aka. “Jeff Dean style” parameter averaging Model A
- 24. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler Model A Model A data parallelism aka. “Jeff Dean style” parameter averaging
- 25. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler Model A Model A Model A data parallelism aka. “Jeff Dean style” parameter averaging
- 26. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler Node 1 Model A Model A Model A data parallelism aka. “Jeff Dean style” parameter averaging
- 27. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler Node 1 Node 2 Model A Model A Model A data parallelism aka. “Jeff Dean style” parameter averaging
- 28. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler Node 1 Node 2 Node 3 Model A Model A Model A data parallelism aka. “Jeff Dean style” parameter averaging
- 29. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler Node 1 Node 2 Node 3 Model A Model A Model A data parallelism aka. “Jeff Dean style” parameter averaging Parameter Server
- 30. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler Node 1 Node 2 Node 3 Model A Part 1 Model A Part 2 Model A Part 3 intra-model parallelism Parameter Server
- 31. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler intra-model parallelism
- 32. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler v intra-model parallelism
- 33. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler v v intra-model parallelism
- 34. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler v v v intra-model parallelism
- 35. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler v v v v intra-model parallelism
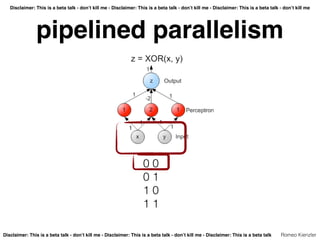
- 36. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler pipelined parallelism
- 37. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler pipelined parallelism 0 0 0 1 1 0 1 1
- 38. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler pipelined parallelism 0 0 0 1 1 0 1 1
- 39. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler pipelined parallelism 0 0 0 1 1 0 1 1
- 40. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler pipelined parallelism 0 0 0 1 1 0 1 1
- 41. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler pipelined parallelism 0 0 0 1 1 0 1 1
- 42. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler Apache SparkDriver JVM Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM
- 43. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler DeepLearning4J vs.
- 44. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler DeepLearning4J vs. data parallelism
- 45. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler ND4J (DeepLearning4J) • Tensor support (Linear Buffer + Stride) • Multiple implementations, one interface • vectorized c++ code (JavaCPP), off-heap data storage, BLAS (OpenBLAS, Intel MKL, cuBLAS) • GPU (CUDA 8)
- 46. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler ND4J (DeepLearning4J) • Tensor support (Linear Buffer + Stride) • Multiple implementations, one interface • vectorized c++ code (JavaCPP), off-heap data storage, BLAS (OpenBLAS, Intel MKL, cuBLAS) • GPU (CUDA 8) intra-m odel parallelism
- 47. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler Apache SystemML • Custom machine learning algorithms • Declarative ML • Transparent distribution on data-parallel framework • Scale-up • Scale-out • Cost-based optimiser generates low level execution plans
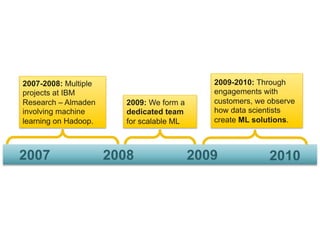
- 48. 200920082007 2007-2008: Multiple projects at IBM Research – Almaden involving machine learning on Hadoop. 2010 2009-2010: Through engagements with customers, we observe how data scientists create ML solutions. 2009: We form a dedicated team for scalable ML
- 50. 20162015 June 2015: IBM Announces open- source SystemML September 2015: Code available on Github November 2015: SystemML enters Apache incubation June 2016: Second Apache release (0.10) February 2016: First release (0.9) of Apache SystemML
- 51. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler Apache SystemML U"="rand(nrow(X),"r,"min"="01.0,"max"="1.0);"" V"="rand(r,"ncol(X),"min"="01.0,"max"="1.0);"" while(i"<"mi)"{" """i"="i"+"1;"ii"="1;" """if"(is_U)" """"""G"="(W"*"(U"%*%"V"0"X))"%*%"t(V)"+"lambda"*"U;" """else" """"""G"="t(U)"%*%"(W"*"(U"%*%"V"0"X))"+"lambda"*"V;" """norm_G2"="sum(G"^"2);"norm_R2"="norm_G2;""""" """R"="0G;"S"="R;" """while(norm_R2">"10E09"*"norm_G2"&"ii"<="mii)"{" """""if"(is_U)"{" """""""HS"="(W"*"(S"%*%"V))"%*%"t(V)"+"lambda"*"S;" """""""alpha"="norm_R2"/"sum"(S"*"HS);" """""""U"="U"+"alpha"*"S;""" """""}"else"{" """""""HS"="t(U)"%*%"(W"*"(U"%*%"S))"+"lambda"*"S;" """""""alpha"="norm_R2"/"sum"(S"*"HS);" """""""V"="V"+"alpha"*"S;""" """""}" """""R"="R"0"alpha"*"HS;" """""old_norm_R2"="norm_R2;"norm_R2"="sum(R"^"2);" """""S"="R"+"(norm_R2"/"old_norm_R2)"*"S;" """""ii"="ii"+"1;" """}""" """is_U"="!"is_U;" }"
- 52. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler Apache SystemML U"="rand(nrow(X),"r,"min"="01.0,"max"="1.0);"" V"="rand(r,"ncol(X),"min"="01.0,"max"="1.0);"" while(i"<"mi)"{" """i"="i"+"1;"ii"="1;" """if"(is_U)" """"""G"="(W"*"(U"%*%"V"0"X))"%*%"t(V)"+"lambda"*"U;" """else" """"""G"="t(U)"%*%"(W"*"(U"%*%"V"0"X))"+"lambda"*"V;" """norm_G2"="sum(G"^"2);"norm_R2"="norm_G2;""""" """R"="0G;"S"="R;" """while(norm_R2">"10E09"*"norm_G2"&"ii"<="mii)"{" """""if"(is_U)"{" """""""HS"="(W"*"(S"%*%"V))"%*%"t(V)"+"lambda"*"S;" """""""alpha"="norm_R2"/"sum"(S"*"HS);" """""""U"="U"+"alpha"*"S;""" """""}"else"{" """""""HS"="t(U)"%*%"(W"*"(U"%*%"S))"+"lambda"*"S;" """""""alpha"="norm_R2"/"sum"(S"*"HS);" """""""V"="V"+"alpha"*"S;""" """""}" """""R"="R"0"alpha"*"HS;" """""old_norm_R2"="norm_R2;"norm_R2"="sum(R"^"2);" """""S"="R"+"(norm_R2"/"old_norm_R2)"*"S;" """""ii"="ii"+"1;" """}""" """is_U"="!"is_U;" }" SystemML: compile and run at scale no performance code needed!
- 55. Architecture High-Level Operations (HOPs) General representation of statements in the data analysis language Low-Level Operations (LOPs) General representation of operations in the runtime framework High-level language front-ends Multiple execution environments Cost Based Optimizer
- 56. Architecture High-Level Operations (HOPs) General representation of statements in the data analysis language Low-Level Operations (LOPs) General representation of operations in the runtime framework High-level language front-ends Multiple execution environments Cost Based Optimizer data parallelism
- 57. Architecture High-Level Operations (HOPs) General representation of statements in the data analysis language Low-Level Operations (LOPs) General representation of operations in the runtime framework High-level language front-ends Multiple execution environments Cost Based Optimizer intra-m odel parallelism
- 58. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler TensorFrames Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM
- 59. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler TensorFrames Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM
- 60. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler TensorFrames Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM inter-m odel parallelism
- 61. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler TensorSparkParameter Server on Driver Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM
- 62. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler TensorSparkParameter Server on Driver Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM Compute Node Executor JVM Executor JVM Executor JVM data parallelism
- 63. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler CaffeOnSpark
- 64. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler CaffeOnSpark data parallelism
- 65. Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk - don’t kill me - Disclaimer: This is a beta talk Romeo Kienzler ?