Patterns for Success in Data Science Engagements
0 likes251 views

The document outlines lessons learned from four short-term data science engagements with various clients, focusing on their problems, data accessibility, existing models, and outcomes. Key takeaways emphasize starting with simple problems, aligning client expectations with measurable outcomes, and the importance of knowledge transfer and effective communication of methodologies. Overall, it highlights strategies for successful data science projects to ensure client buy-in and effective implementation.




























Patterns for Success in Data Science Engagements
- 1. Patterns for Success in Data Science Engagements Dr. David Michel
- 2. Overview
- 3. Overview ThoughtWorks has been expanding the quantity and depth of our data related engagements across the EU and globally under our Intelligent Empowerment offering. This talk will focus on lessons learned from 4 short term engagements with four different clients over the last 18 months ● Length of engagements varied between 2 weeks - 2 months ● Commonalities/differences in necessary approach ● Themes for success ● Pitfalls to avoid
- 4. Project Summary CLIENT 1 CLIENT 2 CLIENT 3 CLIENT 4 Web presence for South American media conglomerate Home recipe delivery service offered by major UK retailer Major UK automobile reseller Major UK retailer Wanted to predict age/sex of anonymous users based on behaviour of registered users Wanted to more accurately predict demand for new recipes and different combinations of existing ones Wanted better insight and put themselves on the path towards making more data driven decisions Wanted to determine optimum shelf capacity for preset product range Existing model and infrastructure in place Set of heuristics in use Lots of reports and excel spreadsheets. No modelling to speak of Existing tool in use. Series of SQL queries run directly off data warehouse
- 5. Client 1
- 6. Client 1 (Web Branch for Media Company) ● Problem clearly defined ○ Identify men/women ○ Identify men 18-35, women 25-49 ● Data clearly accessible (though latency was high) ○ Jupyter sandbox with access to BigQuery data store ● Existing model in place ○ XGBoost with ~250 features ○ Updated weekly with ~2 hour training time ● Metrics in place (though likely suboptimal) ○ Accuracy in all three demos as defined by Nielsen
- 7. Client 1 (Web Branch for Media Company) ● Limited time period (5 weeks) required scaling level of ambition and comprehensiveness of work ● Focus limited to three areas: ○ Quality of training data ○ Time period over which features were aggregated ○ Sub selection of training data to better serve usecase ● Emphasis placed on logging and reproducibility of results
- 8. Results in Six Graphs
- 9. Client 2
- 10. Client 2 (Home Recipe Box) ● Problem clearly defined ○ Better forecast demand three weeks in advance of recipe offerings (when ingredients are ordered) to lower waste ● Data clearly accessible (and small) ○ ~35 week order history comprising ~6000 orders from ~5000 unique customers ● No model in place ○ Set of heuristics whose usefulness were visibly depreciating over time as number of recipes and variety combinations increased ● Metrics in place (though likely suboptimal) ○ Percentage over/undershoot of prediction compared to actual orders
- 11. Client 2 (Home Recipe Box) ● Limited time period (3 weeks to deliver) ● Emphasis placed on creating functional forecasting tool and with large amounts of time budgeted for training and handover ● Self updating forecasting/visualisation tool built in Colaboratory Notebook ○ Recipe metadata and historical sales used to retrain random forest (initial attempts with regularised linear models were problematic) weekly with rolling 10 week windows of historical sales
- 12. Results ● Internal forecasting for 9 weeks worth of data: ○ Mean error: 2.6% ○ Median error: 2.0% ○ Max overestimate: 10% ○ Max underestimate: 10% ● New model: ○ Mean error: 2.0% ○ Median error: 1.5% ○ Max overestimate: 7.2% ○ Max underestimate: 8.7%
- 13. Client 3
- 14. Client 3 (B2B Auto reseller) ● No real problem defined ○ Interest in sales channel allocation, but no internal agreement on desired output ● Data clearly accessible (in varying degrees of quality and latency) ○ SQL server 2008 enterprise warehouse with vehicle information ○ Refurb and auction information available only via spreadsheets downloaded from partner portals ● No existing model in place ● Metrics for success not defined
- 15. Client 3 (B2B Auto reseller) ● 2 weeks to investigate available data and provide POC ● Lots of room to choose right/wrong problem ● Area chosen was POC for sale price forecasting based on channel and vehicle specifications ● Was thought to be the lowest hanging fruit that would allow for higher return on investment for each asset ○ Website vs Auction ○ Optimal refurb parameters for specific vehicles
- 17. Client 4
- 18. Client 4 (Major Grocer) ● Problem (reasonably) well defined ○ Investigate efficacy of current tool in use to determine shelf capacity (given fixed product range) ● Data accessible, but not discoverable and with numerous (often conflicting) sources of truth ● No existing model in place ○ Existing product used fixed calculation that was run via a series of SQL queries inside data warehouse ● No metrics in use to benchmark existing product
- 19. Client 4 (Major Grocer) ● ~8 weeks to investigate ● With no metric to evaluate existing metric this was the obvious place to start ● What makes an ideal shelf capacity: ○ Availability (minimise lost sales) ○ Minimise labour costs re: stocking ○ Minimise waste ● Versions of these of varying quality/usefulness available internally
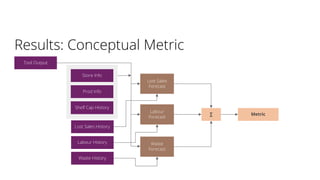
- 20. Results: Conceptual Metric Tool Output Store Info Prod Info Shelf Cap History Lost Sales History Labour History Waste History Lost Sales Forecast Labour Forecast Waste Forecast ∑ Metric
- 21. Results: Forecasting ● Two years sample data ● Subset of stores and products ○ ~500 “essential” products ○ 2 stores of varying design and location (most recent 20% set aside for validation) ● Forecasting POC done for labour costs and lost sales ○ Cross validation grid with PCA used to reduce feature space ○ Random forest regressor gave better results than regularised linear models
- 22. Results: Lost Sales Forecasting
- 24. Lessons learned
- 25. Important Questions to Ask Technology/information ● Do they have historical data and what is its consistency? ● Multiple sources? ● Access in volume and at speed? ● Discoverable? Enthusiasm ● Have they defined a problem or class of problems they would like to solve? ● How comfortable are they with more modern ML/AI based approaches?
- 26. Important Questions to Ask ● Measurement of outcomes ○ Is there a metric or metrics in place to optimise for? ○ Do said metrics relate to valuable business outcomes in a meaningful way? ● History/Reproducibility ○ What have they tried before? ○ Have those efforts been logged in a way such that they are accessible and understandable?
- 27. Takeaways ● Start simple ○ Easier to solve problems can often help quickly sway the unconverted and there is usually some obvious low-hanging fruit ○ Less complex models are easier to explain, train and maintain ● Align goals and expectations ○ Agree on metrics and what they actually represent ○ Call out any disconnects between KPIs and the value the client believes they represent ○ Take the time to explain ways of working and potential outcomes to team members
- 28. Takeaways ● Demonstrate value ○ In cases where clients are suspicious/unconvinced of new methodologies, easy wins and new knowledge trump elegant solutions ● Invest time in knowledge transfer and training ○ Do your best to log your efforts (especially those that were unsuccessful) in a manner easier accessible to potential future investigators ○ If you’re going to leave what you’ve created in someone else’s hands they should be comfortable maintaining it
- 29. Thank you