Performing Data Science with HBase
1 like1,508 views

This document discusses performing data science on HBase using the WibiData platform. It introduces WibiData Language (WDL), which allows analyzing data stored in HBase columns in a concise and interactive way using Scala and Apache Crunch. The document demonstrates building a histogram of editor metrics by reading user data from an HBase table, filtering and binning average edit deltas, and visualizing the results. WDL aims to make HBase data exploration more accessible for data scientists compared to other frameworks like Hive and Pig.




















![Example: Transforming a list
val lst = List(1, 4, 7)
val doubled = lst.map(x => x * 2)
• map() applies a function to each element,
yielding a new list. (doubled is the list [2,
8, 14])](https://image.slidesharecdn.com/hadoop-world-2012-web-121029204205-phpapp02/85/Performing-Data-Science-with-HBase-21-320.jpg)
![Example: Filtering
• Apply a boolean function to each element of a
list, keep the ones that return true:
val lst = List(1, 3, 5, 6, 9)
val threes =
lst.filter(x => x % 3 == 0)
// ‘threes’ is the list [3, 6, 9]](https://image.slidesharecdn.com/hadoop-world-2012-web-121029204205-phpapp02/85/Performing-Data-Science-with-HBase-22-320.jpg)



![PCollections… of WibiRows
• WibiRow: Represents a row in a Wibi table
• Enables access to sparse columns
• … as a value: row(someColumn): Value
• … As a timeline of values to iterate/aggregate:
row.timeline(someColumn): Timeline[Value]](https://image.slidesharecdn.com/hadoop-world-2012-web-121029204205-phpapp02/85/Performing-Data-Science-with-HBase-26-320.jpg)






val userTable = read(
From.wibi(WibiTableAddress.of("user"), stats))](https://image.slidesharecdn.com/hadoop-world-2012-web-121029204205-phpapp02/85/Performing-Data-Science-with-HBase-32-320.jpg)

val userTable = read(
From.wibi(WibiTableAddress.of("user"), stats))
Will act as a handle
for accessing the
column family.](https://image.slidesharecdn.com/hadoop-world-2012-web-121029204205-phpapp02/85/Performing-Data-Science-with-HBase-33-320.jpg)

val userTable = read(
From.wibi(WibiTableAddress.of("user"), stats))
Type annotation tells
WDL what kind of
data to read out of
the family.](https://image.slidesharecdn.com/hadoop-world-2012-web-121029204205-phpapp02/85/Performing-Data-Science-with-HBase-34-320.jpg)

val userTable = read(
From.wibi(WibiTableAddress.of("user"), stats))
userTable is a PCollection[WibiRow] obtained by reading the
column family “edit_metric_stats” from the Wibi table
“user.”](https://image.slidesharecdn.com/hadoop-world-2012-web-121029204205-phpapp02/85/Performing-Data-Science-with-HBase-35-320.jpg)





](https://image.slidesharecdn.com/hadoop-world-2012-web-121029204205-phpapp02/85/Performing-Data-Science-with-HBase-41-320.jpg)









Performing Data Science with HBase
- 2. Performing Data Science with HBase Aaron Kimball – CTO Kiyan Ahmadizadeh – MTS
- 3. MapReduce and log files Log files Batch analysis Result data set
- 4. The way we build apps is changing
- 5. HBase plays a big role • High performance random access • Flexible schema & sparse storage • Natural mechanism for time series data … organized by user
- 8. Data science lays the groundwork • Feature selection requires insight • Data lies in HBase, not log files • MapReduce is too cumbersome for exploratory analytics
- 9. Data science lays the groundwork • Feature selection requires insight • Data lies in HBase, not log files • MapReduce is too cumbersome for exploratory analytics • This talk: How do we explore data in HBase?
- 10. Why not Hive? • Need to manually sync column schemas • No complex type support for HBase + Hive – Our use of Avro facilitates complex record types • No support for time series events in columns
- 11. Why not Pig? • Tuples handle sparse data poorly • No support for time series events in columns • UDFs and main pipeline are written in different languages (Java, Pig Latin) – (True of Hive too)
- 12. Our analysis needs • Read from HBase • Express complex concepts • Support deep MapReduce pipelines • Be written in concise code • Be accessible to data scientists more comfortable with R & python than Java
- 13. Our analysis needs • Concise: We use Scala • Powerful: We use Apache Crunch • Interactive: We built a shell wibi>
- 14. WDL: The WibiData Language wibi> 2 + 2 wibi> :tables res0: Int = 4 Table Description ======== =========== page Wiki page info user per-user stats
- 15. Outline • Analyzing Wikipedia • Introducing Scala • An Overview of Crunch • Extending Crunch to HBase + WibiData • Demo!
- 16. Analyzing Wikipedia • All revisions of all English pages • Simulates real system that could be built on top of WibiData • Allows us to practice real analysis at scale
- 17. Per-user information • Rows keyed by Wikipedia user id or IP address • Statistics for several metrics on all edits made by each user
- 18. Introducing • Scala language allows declarative statements • Easier to express transformations over your data in an intuitive way • Integrates with Java and runs on the JVM • Supports interactive evaluation
- 19. Example: Iterating over lists def printChar(ch: Char): Unit = { println(ch) } val lst = List('a', 'b', 'c') lst.foreach(printChar)
- 20. … with an anonymous function val lst = List('a', 'b', 'c') lst.foreach( ch => println(ch) ) • Anonymous function can be specified as argument to foreach() method of a list. • Lists, sets, etc. are immutable by default
- 21. Example: Transforming a list val lst = List(1, 4, 7) val doubled = lst.map(x => x * 2) • map() applies a function to each element, yielding a new list. (doubled is the list [2, 8, 14])
- 22. Example: Filtering • Apply a boolean function to each element of a list, keep the ones that return true: val lst = List(1, 3, 5, 6, 9) val threes = lst.filter(x => x % 3 == 0) // ‘threes’ is the list [3, 6, 9]
- 23. Example: Aggregation val lst = List(1, 2, 12, 5) lst.reduceLeft( (sum, x) => sum + x ) // Evaluates to 20. • reduceLeft() aggregates elements left-to-right, in this case by keeping a running sum.
- 24. Crunch: MapReduce pipelines def runWordCount(input, output) = { val wordCounts = read(From.textFile(input)) .flatMap(line => line.toLowerCase.split("""s+""")) .filter(word => !word.isEmpty()) .count wordCounts.write(To.textFile(output)) }
- 25. PCollections: Crunch data sets • Represent a parallel record-oriented data set • Items in PCollections can be lines of text, tuples, or complex data structures • Crunch functions (like flatMap() and filter()) do work on partitions of PCollections in parallel.
- 26. PCollections… of WibiRows • WibiRow: Represents a row in a Wibi table • Enables access to sparse columns • … as a value: row(someColumn): Value • … As a timeline of values to iterate/aggregate: row.timeline(someColumn): Timeline[Value]
- 28. Demo!
- 29. Demo: Visualizing Distributions • Suppose you have a metric taken on some population of users. • Want to visualize what the distribution of the metric among the population looks like. – Could inform next analysis steps, feature selection for models, etc. • Histograms can give insight on the shape of a distribution. – Choose a set of bins for the metric. – Count the number of population members whose metric falls into each bin.
- 30. Demo: Wikimedia Dataset • We have a user table containing the average delta for all edits made by a user to pages. • Edit Delta: The number of characters added or deleted by an edit to a page. • Want to visualize the distribution of average deltas among users.
- 31. Demo!
- 32. Code: Accessing Data val stats = ColumnFamily[Stats]("edit_metric_stats") val userTable = read( From.wibi(WibiTableAddress.of("user"), stats))
- 33. Code: Accessing Data val stats = ColumnFamily[Stats]("edit_metric_stats") val userTable = read( From.wibi(WibiTableAddress.of("user"), stats)) Will act as a handle for accessing the column family.
- 34. Code: Accessing Data val stats = ColumnFamily[Stats]("edit_metric_stats") val userTable = read( From.wibi(WibiTableAddress.of("user"), stats)) Type annotation tells WDL what kind of data to read out of the family.
- 35. Code: Accessing Data val stats = ColumnFamily[Stats]("edit_metric_stats") val userTable = read( From.wibi(WibiTableAddress.of("user"), stats)) userTable is a PCollection[WibiRow] obtained by reading the column family “edit_metric_stats” from the Wibi table “user.”
- 36. Code: UDFs def getBin(bins: Range, value: Double): Int = { bins.reduceLeft ( (choice, bin) => if (value < bin) choice else bin ) } def inRange(bins: Range, value: Double): Boolean = range.start <= value && value <= range.end
- 37. Code: UDFs def getBin(bins: Range, value: Double): Int = { bins.reduceLeft ( (choice, bin) => if (value < bin) choice else bin ) } def inRange(bins: Range, value: Double): Boolean = range.start <= value && value <= range.end Everyday Scala function declarations!
- 38. Code: Filtering val filtered = userTable.filter { row => // Keep editors who have edit_metric_stats:delta defined !row(stats).isEmpty && row(stats).get.contains("delta") }
- 39. Code: Filtering val filtered = userTable.filter { row => // Keep editors who have edit_metric_stats:delta defined !row(stats).isEmpty && row(stats).get.contains("delta") } Boolean predicate on elements in the PCollection
- 40. Code: Filtering val filtered = userTable.filter { row => // Keep editors who have edit_metric_stats:delta defined !row(stats).isEmpty && row(stats).get.contains("delta") } filtered is a PCollection of rows that have the column edit_metric_stats:delta
- 41. Code: Filtering val filtered = userTable.filter { row => // Keep editors who have edit_metric_stats:delta defined !row(stats).isEmpty && row(stats).get.contains("delta") } Use stats variable we declared earlier to access the column family. val stats = ColumnFamily[Stats]("edit_metric_stats")
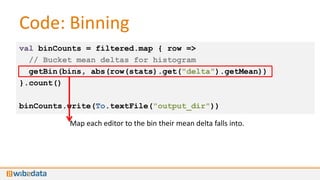
- 42. Code: Binning val binCounts = filtered.map { row => // Bucket mean deltas for histogram getBin(bins, abs(row(stats).get("delta").getMean)) }.count() binCounts.write(To.textFile("output_dir"))
- 43. Code: Binning val binCounts = filtered.map { row => // Bucket mean deltas for histogram getBin(bins, abs(row(stats).get("delta").getMean)) }.count() binCounts.write(To.textFile("output_dir")) Map each editor to the bin their mean delta falls into.
- 44. Code: Binning val binCounts = filtered.map { row => // Bucket mean deltas for histogram getBin(bins, abs(row(stats).get("delta").getMean)) }.count() binCounts.write(To.textFile("output_dir")) Count how many times each bin occurs in the resulting collection.
- 45. Code: Binning val binCounts = filtered.map { row => // Bucket mean deltas for histogram getBin(bins, abs(row(stats).get("delta").getMean)) }.count() binCounts.write(To.textFile("output_dir")) binCounts contains the number of editors that fall in each bin.
- 46. Code: Binning val binCounts = filtered.map { row => // Bucket mean deltas for histogram getBin(bins, abs(row(stats).get("delta").getMean)) }.count() binCounts.write(To.textFile("output_dir")) Writes the result to HDFS.
- 47. Code: Visualization Histogram.plot(binCounts, bins, "Histogram of Editors by Mean Delta", "Mean Delta", "Number of Editors", "delta_mean_hist.html")
- 48. Analysis Results: 1% of Data
- 49. Analysis Results: Full Data Set
- 50. Conclusions + + = Scalable analysis of sparse data
- 51. Aaron Kimball – [email protected] Kiyan Ahmadizadeh – [email protected]