Pivoting Data with SparkSQL by Andrew Ray
18 likes16,403 views

This document discusses pivoting data with SparkSQL. It begins with an outline of topics to be covered, including what a pivot is, syntax, examples, tips, implementation details, and future work. It then provides examples of using pivots on retail sales and movie rating data to generate reports and features for modeling. It also offers tips on specifying pivot values, handling multiple aggregations, and pivoting multiple columns. The implementation details are discussed along with potential areas of future work, including adding pivot support to additional APIs and languages.









![© 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED.
@SVDataScience | 11
SYNTAX: COMPETITION
• pandas (Python)
– pivot_table(df, values='D', index=['A', 'B'],
columns=['C'], aggfunc=np.sum)
• reshape2 (R)
– dcast(df, A + B ~ C, sum)
• Oracle 11g
– SELECT * FROM df PIVOT (sum(D) FOR C IN
('small', 'large')) p](https://image.slidesharecdn.com/9snandrewray-160224040116/85/Pivoting-Data-with-SparkSQL-by-Andrew-Ray-11-320.jpg)






















Pivoting Data with SparkSQL by Andrew Ray
- 1. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 1 Pivoting Data with SparkSQL Andrew Ray Senior Data Engineer Silicon Valley Data Science
- 2. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 2 CODE git.io/vgy34 (github.com/silicon-valley-data-science/spark-pivot-examples)
- 3. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 3 OUTLINE • What’s a Pivot? • Syntax • Real world examples • Tips and Tricks • Implementation • Future work git.io/vgy34
- 4. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 4 WHAT’S A PIVOT?
- 5. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 5 WHAT’S A PIVOT?
- 6. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 6 WHAT’S A PIVOT? Group by A, pivot on B, and sum C A B C G X 1 G Y 2 G X 3 H Y 4 H Z 5 A X Y Z G 4 2 H 4 5
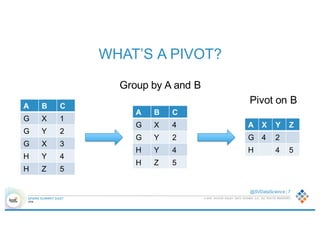
- 7. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 7 WHAT’S A PIVOT? Group by A and B Pivot on BA B C G X 1 G Y 2 G X 3 H Y 4 H Z 5 A B C G X 4 G Y 2 H Y 4 H Z 5 A X Y Z G 4 2 H 4 5
- 8. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 8 WHAT’S A PIVOT? Pivot on B (w/o agg.) Group by AA B C G X 1 G Y 2 G X 3 H Y 4 H Z 5 A X Y Z G 1 G 2 G 3 H 4 H 5 A X Y Z G 4 2 H 4 5
- 9. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 9 SYNTAX
- 10. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 10 SYNTAX • Dataframe/table with columns A, B, C, and D. • How to – group by A and B – pivot on C (with distinct values “small” and “large”) – sum of D
- 11. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 11 SYNTAX: COMPETITION • pandas (Python) – pivot_table(df, values='D', index=['A', 'B'], columns=['C'], aggfunc=np.sum) • reshape2 (R) – dcast(df, A + B ~ C, sum) • Oracle 11g – SELECT * FROM df PIVOT (sum(D) FOR C IN ('small', 'large')) p
- 12. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 12 SYNTAX: SPARKSQL • Simple – df.groupBy("A", "B").pivot("C").sum("D") • Explicit pivot values – df.groupBy("A", "B") .pivot("C", Seq("small", "large")) .sum("D")
- 13. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 13 PIVOT • Added to DataFrame API in Spark 1.6 – Scala – Java – Python – Not R L
- 14. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 14 REAL WORLD EXAMPLES
- 15. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 15 EXAMPLE 1: REPORTING • Retail sales • TPC-DS dataset – scale factor 1 • Docker image: docker run -it svds/spark-pivot-reporting TPC Benchmark™ DS - Standard Specification, Version 2.1.0 Page 18 of 135 2.2.2.3 The implementation chosen by the test sponsor for a particular datatype definition shall be applied consistently to all the instances of that datatype definition in the schema, except for identifier columns, whose datatype may be selected to satisfy database scaling requirements. 2.2.3 NULLs If a column definition includes an ‘N’ in the NULLs column this column is populated in every row of the table for all scale factors. If the field is blank this column may contain NULLs. 2.2.4 Foreign Key If the values in this column join with another column, the foreign columns name is listed in the Foreign Key field of the column definition. 2.3 Fact Table Definitions 2.3.1 Store Sales (SS) 2.3.1.1 Store Sales ER-Diagram 2.3.1.2 Store Sales Column Definitions Each row in this table represents a single lineitem for a sale made through the store channel and recorded in the store_sales fact table. Table 2-1 Store_sales Column Definitions Column Datatype NULLs Primary Key Foreign Key ss_sold_date_sk identifier d_date_sk ss_sold_time_sk identifier t_time_sk ss_item_sk (1) identifier N Y i_item_sk ss_customer_sk identifier c_customer_sk ss_cdemo_sk identifier cd_demo_sk ss_hdemo_sk identifier hd_demo_sk ss_addr_sk identifier ca_address_sk ss_store_sk identifier s_store_sk ss_promo_sk identifier p_promo_sk
- 16. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 16 SALES BY CATEGORY AND QUARTER sql("""select *, concat('Q', d_qoy) as qoy from store_sales join date_dim on ss_sold_date_sk = d_date_sk join item on ss_item_sk = i_item_sk""") .groupBy("i_category") .pivot("qoy") .agg(round(sum("ss_sales_price")/1000000,2)) .show
- 17. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 17 SALES BY CATEGORY AND QUARTER +-----------+----+----+----+----+ | i_category| Q1| Q2| Q3| Q4| +-----------+----+----+----+----+ | Books|1.58|1.50|2.84|4.66| | Women|1.41|1.36|2.54|4.16| | Music|1.50|1.44|2.66|4.36| | Children|1.54|1.46|2.74|4.51| | Sports|1.47|1.40|2.62|4.30| | Shoes|1.51|1.48|2.68|4.46| | Jewelry|1.45|1.39|2.59|4.25| | null|0.04|0.04|0.07|0.13| |Electronics|1.56|1.49|2.77|4.57| | Home|1.57|1.51|2.79|4.60| | Men|1.60|1.54|2.86|4.71| +-----------+----+----+----+----+
- 18. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 18 EXAMPLE 2: FEATURE GENERATION • MovieLens 1M Dataset – ~1M movie ratings – 6040 users – 3952 movies • Predict gender based on ratings – Using 100 most popular movies
- 19. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 19 LOAD RATINGS val ratings_raw = sc.textFile("Downloads/ml-1m/ratings.dat") case class Rating(user: Int, movie: Int, rating: Int) val ratings = ratings_raw.map(_.split("::").map(_.toInt)).map(r => Rating(r(0),r(1),r(2))).toDF ratings.show +----+-----+------+ |user|movie|rating| +----+-----+------+ | 11| 1753| 4| | 11| 1682| 1| | 11| 216| 4| | 11| 2997| 4| | 11| 1259| 3| ...
- 20. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 20 LOAD USERS val users_raw = sc.textFile("Downloads/ml-1m/users.dat") case class User(user: Int, gender: String, age: Int) val users = users_raw.map(_.split("::")).map(u => User(u(0).toInt, u(1), u(2).toInt)).toDF val sample_users = users.where(expr("gender = 'F' or ( rand() * 5 < 2 )")) sample_users.groupBy("gender").count().show +------+-----+ |gender|count| +------+-----+ | F| 1709| | M| 1744| +------+-----+
- 21. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 21 PREP DATA val popular = ratings.groupBy("movie") .count() .orderBy($"count".desc) .limit(100) .map(_.get(0)).collect val ratings_pivot = ratings.groupBy("user") .pivot("movie", popular.toSeq) .agg(expr("coalesce(first(rating),3)").cast("double")) ratings_pivot.where($"user" === 11).show +----+----+---+----+----+---+----+---+----+----+---+... |user|2858|260|1196|1210|480|2028|589|2571|1270|593|... +----+----+---+----+----+---+----+---+----+----+---+... | 11| 5.0|3.0| 3.0| 3.0|4.0| 3.0|3.0| 3.0| 3.0|5.0|... +----+----+---+----+----+---+----+---+----+----+---+...
- 22. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 22 BUILD MODEL val data = ratings_pivot.join(sample_users, "user") .withColumn("label", expr("if(gender = 'M', 1, 0)").cast("double")) val assembler = new VectorAssembler() .setInputCols(popular.map(_.toString)) .setOutputCol("features") val lr = new LogisticRegression() val pipeline = new Pipeline().setStages(Array(assembler, lr)) val Array(training, test) = data.randomSplit(Array(0.9, 0.1), seed = 12345) val model = pipeline.fit(training)
- 23. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 23 TEST val res = model.transform(test).select("label", "prediction") res.groupBy("label").pivot("prediction", Seq(1.0, 0.0)).count().show +-----+---+---+ |label|1.0|0.0| +-----+---+---+ | 1.0|114| 74| | 0.0| 46|146| +-----+---+---+ Accuracy 68%
- 24. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 24 TIPS AND TRICKS
- 25. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 25 USAGE NOTES • Specify the distinct values of the pivot column – Otherwise it does this: val values = df.select(pivotColumn) .distinct() .sort(pivotColumn) .map(_.get(0)) .take(maxValues + 1) .toSeq
- 26. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 26 MULTIPLE AGGREGATIONS df.groupBy("A", "B").pivot("C").agg(sum("D"), avg("D")).show +---+---+------------+------------+------------+------------+ | A| B|small_sum(D)|small_avg(D)|large_sum(D)|large_avg(D)| +---+---+------------+------------+------------+------------+ |foo|two| 6| 3.0| null| null| |bar|two| 6| 6.0| 7| 7.0| |foo|one| 1| 1.0| 4| 2.0| |bar|one| 5| 5.0| 4| 4.0| +---+---+------------+------------+------------+------------+
- 27. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 27 PIVOT MULTIPLE COLUMNS • Merge columns and pivot as usual df.withColumn(“p”, concat($”p1”, $”p2”)) .groupBy(“a”, “b”) .pivot(“p”) .agg(…)
- 28. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 28 MAX COLUMNS • spark.sql.pivotMaxValues – Default: 10,000 – When doing a pivot without specifying values for the pivot column this is the maximum number of (distinct) values that will be collected without error.
- 29. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 29 IMPLEMENTATION
- 30. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 30 PIVOT IMPLEMENTATION • pivot is a method of GroupedData and returns GroupedData with PivotType. • New logical operator: o.a.s.sql.catalyst.plans.logical.Pivot • Analyzer rule: o.a.s.sql.catalyst.analysis.Analyzer.ResolvePivot – Currently translates logical pivot into an aggregation with lots of if statements.
- 31. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 31 FUTURE WORK
- 32. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 32 FUTURE WORK • Add to R API • Add to SQL syntax • Add support for unpivot • Faster implementation
- 33. © 2016 SILICON VALLEY DATA SCIENCE LLC. ALL RIGHTS RESERVED. @SVDataScience | 33 Pivoting Data with SparkSQL Andrew Ray [email protected] We’re hiring! svds.com/careers THANK YOU. git.io/vgy34