Present and future of unified, portable, and efficient data processing with Apache Beam
1 like325 views

Apache Beam is a unified programming model that facilitates the creation of portable data processing pipelines in multiple languages and environments. It serves as a connector for the big data ecosystem, allowing developers to express batch and streaming data processing tasks easily while focusing on portability. The document discusses Beam's architecture, capabilities, and roadmap, alongside community involvement and areas for future improvements.

















































Present and future of unified, portable, and efficient data processing with Apache Beam
- 1. Abstract The world of big data involves an ever-changing field of players. Much as SQL stands as a lingua franca for declarative data analysis, Apache Beam aims to provide a portable standard for expressing robust, out-of-order data processing pipelines in a variety of languages across a variety of platforms. In a way, Apache Beam is a glue that can connect the big data ecosystem together; it enables users to "run any data processing pipeline anywhere." This talk will briefly cover the capabilities of the Beam model for data processing and discuss its architecture, including the portability model. We’ll focus on the present state of the community and the current status of the Beam ecosystem. We’ll cover the state of the art in data processing and discuss where Beam is going next, including completion of the portability framework and the Streaming SQL. Finally, we’ll discuss areas of improvement and how anybody can join us on the path of creating the glue that interconnects the big data ecosystem. This session is a (Intermediate) talk in our IoT and Streaming track. It focuses on Apache Flink, Apache Kafka, Apache Spark, Cloud, Other and is geared towards Architect, Data Scientist, Data Analyst, Developer / Engineer, Operations / IT audiences. Feel free to reuse some of these slides for your own talk on Apache Beam! If you do, please add a proper reference / quote / credit.
- 2. Present and future of unified, portable and efficient data processing with Apache Beam Davor Bonaci PMC Chair, Apache Beam
- 3. Apache Beam: Open Source data processing APIs ● Expresses data-parallel batch and streaming algorithms using one unified API ● Cleanly separates data processing logic from runtime requirements ● Supports execution on multiple distributed processing runtime environments
- 4. Apache Beam is a unified programming model designed to provide efficient and portable data processing pipelines
- 5. Agenda 1. Project timeline so far 2. Expressing data-parallel pipelines with the Beam model 3. The Beam vision for portability a. Extensibility to integrate the Big Data ecosystem 4. Project roadmap
- 6. Apache Beam at DataWorks Summit ● Birds-of-a-feather: IoT, Streaming and Data Flow ○ Panel: Aldrin Piri, Davor Bonaci, Karthik Ramasamy, Jeremy Dyer ○ Yesterday @ 5:40 pm ● Foundations of streaming SQL: stream & table theory ○ Anton Kedin, Software Engineer @ Google ○ Today @ 11:30 am
- 7. What we accomplished so far? 02/01/2016 Enter Apache Incubator 3/20/2018 Latest release (2.4.0) 2016 Incubation Early 2016 API stabilization Late 2017 & 2018 Enterprise growth 01/10/2017 Graduation as a top-level project 5/16/2017 First stable release
- 8. Expressing data-parallel pipelines with the Beam model A unified model for batch and streaming
- 9. Processing time vs. event time
- 10. The Beam Model: asking the right questions What results are calculated? Where in event time are results calculated? When in processing time are results materialized? How do refinements of results relate?
- 11. PCollection<KV<String, Integer>> scores = input .apply(Sum.integersPerKey()); The Beam Model: What is being computed?
- 12. The Beam Model: What is being computed?
- 13. PCollection<KV<String, Integer>> scores = input .apply(Window.into(FixedWindows.of(Duration.standardMinutes(2))) .apply(Sum.integersPerKey()); The Beam Model: Where in event time?
- 14. The Beam Model: Where in event time?
- 15. PCollection<KV<String, Integer>> scores = input .apply(Window.into(FixedWindows.of(Duration.standardMinutes(2)) .triggering(AtWatermark())) .apply(Sum.integersPerKey()); The Beam Model: When in processing time?
- 16. The Beam Model: When in processing time?
- 17. PCollection<KV<String, Integer>> scores = input .apply(Window.into(FixedWindows.of(Duration.standardMinutes(2)) .triggering(AtWatermark() .withEarlyFirings( AtPeriod(Duration.standardMinutes(1))) .withLateFirings(AtCount(1))) .accumulatingFiredPanes()) .apply(Sum.integersPerKey()); The Beam Model: How do refinements relate?
- 18. The Beam Model: How do refinements relate?
- 19. Customizing What Where When How 3 Streaming 4 Streaming + Accumulation 1 Classic Batch 2 Windowed Batch
- 20. The Beam vision for portability Write once, run anywhere“ ”
- 21. Beam Vision: mix and match SDKs and runtimes ● The Beam Model: the abstractions at the core of Apache Beam Runner 1 Runner 3Runner 2 ● Choice of SDK: Users write their pipelines in a language that’s familiar and integrated with their other tooling ● Choice of Runners: Users choose the right runtime for their current needs -- on-prem / cloud, open source / not, fully managed / not ● Scalability for Developers: Clean APIs allow developers to contribute modules independently The Beam Model Language A Language CLanguage B The Beam Model Language A SDK Language C SDK Language B SDK
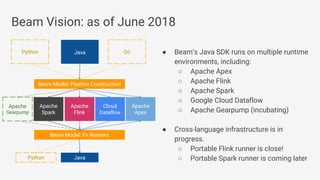
- 22. ● Beam’s Java SDK runs on multiple runtime environments, including: ○ Apache Apex ○ Apache Flink ○ Apache Spark ○ Google Cloud Dataflow ○ Apache Gearpump (incubating) ● Cross-language infrastructure is in progress. ○ Portable Flink runner is close! ○ Portable Spark runner is coming later Beam Vision: as of June 2018 Beam Model: Fn Runners Apache Spark Cloud Dataflow Beam Model: Pipeline Construction Apache Flink Java Java Python Python Apache Apex Apache Gearpump Go
- 23. Example Beam Runners Apache Spark ● Open-source cluster-computing framework ● Large ecosystem of APIs and tools ● Runs on premise or in the cloud Apache Flink ● Open-source distributed data processing engine ● High-throughput and low-latency stream processing ● Runs on premise or in the cloud Google Cloud Dataflow ● Fully-managed service for batch and stream data processing ● Provides dynamic auto-scaling, monitoring tools, and tight integration with Google Cloud Platform
- 24. How to think about Apache Beam?
- 25. How do you build an abstraction layer? Apache Spark Cloud Dataflow Apache Flink ???????? ????????
- 26. Beam: the intersection of runner functionality?
- 27. Beam: the union of runner functionality?
- 30. Getting Started with Apache Beam Quickstarts ● Java SDK ● Python SDK Example walkthroughs ● Word Count ● Mobile Gaming Extensive documentation
- 31. Extensibility to integrate the entire Big Data ecosystem Integrating Up, Down, and Sideways “ ”
- 32. Extensibility points ● Software Development Kits (SDKs) ● Runners ● Domain-specific extensions (DSLs) ● Libraries of transformations ● IOs ● File systems
- 33. Software Development Kits (SDKs) Runner 1 Runner 3Runner 2 The Beam Model Language A SDK Language C SDK Language B SDK
- 34. Runners Runner 1 Runner 3Runner 2 The Beam Model Language A SDK Language C SDK Language B SDK
- 35. Domain-specific extensions (DSLs) The Beam Model Language A SDK Language C SDK Language B SDK DSL 2 DSL 3DSL 1
- 36. Libraries of transformations The Beam Model Language A SDK Language C SDK Language B SDK Library 2 Library 3Library 1
- 37. IO connectors The Beam Model Language A SDK Language C SDK Language B SDK IO connector 2 IO connector 3 IO connector 1
- 38. File systems The Beam Model Language A SDK Language C SDK Language B SDK File system 2 File system 3 File system 1
- 39. Ecosystem integration ● I have an engine → write a Beam runner ● I want to extend Beam to new languages → write an SDK ● I want to adopt an SDK to a target audience → write a DSL ● I want a component can be a part of a bigger data-processing pipeline → write a library of transformations ● I have a data storage or messaging system → write an IO connector or a file system connector
- 40. Apache Beam is a glue that integrates the big data ecosystem
- 41. Project roadmap The future: usability & completion of vision
- 42. ● Beam’s Java SDK runs on multiple runtime environments, including: ○ Apache Apex ○ Apache Flink ○ Apache Spark ○ Google Cloud Dataflow ○ Apache Gearpump (incubating) ● Cross-language infrastructure is in progress. ○ Portable Flink runner is close! ○ Portable Spark runner is coming later Beam Vision: as of June 2018 Beam Model: Fn Runners Apache Spark Cloud Dataflow Beam Model: Pipeline Construction Apache Flink Java Java Python Python Apache Apex Apache Gearpump Go
- 43. collection.apply(ParDo.of(new DoFn<MyType, MyType>() { @ProcessElement void process(ProcessContext c, IntervalWindow w) { }})) collection.apply(ParDo.of(new DoFn<MyType, MyType>() { @ProcessElement void process(@Element MyType element, @Timestamp Instant instant, IntervalWindow window, PaneInfo paneInfo, OutputReceiver<MyType> out) { }})) API usability improvements
- 44. Schemas ● Beam currently treats elements as opaque blobs. ● Understanding structure of elements enables simplification of common tasks and optimizations!
- 45. Canonical streaming use cases Extract-Transform- Load Transforming and cleaning data as it arrives and loading it into a long-term storage layer. Streaming Analytics Analysis and aggregation of data streams that produce a table or a real-time dashboard. Real-time Actions Detecting situations within the event stream and triggering actions in real-time. 3 2 1
- 46. Work in progress: Streaming analytics PCollection<Row> filteredNames = testApps.apply( BeamSql.query( "SELECT appId, description, rowtime " + "FROM PCOLLECTION " + "WHERE id=1"));
- 47. Work in progress: Complex event processing
- 48. Other work in progress ● Performance testing infrastructure ● Build system improvements
- 49. Apache Beam is a unified programming model designed to provide efficient and portable data processing pipelines
- 50. Still coming up... ● Foundations of streaming SQL: stream & table theory ○ Anton Kedin, Software Engineer @ Google ○ Today @ 11:30 am